Win下用idea远程在hadoop上调试spark程序及读取hbase
Win下用idea远程在hadoop上调试spark程序及读取hbase
环境:
Win7
Jdk1.8
Hadoop2.7.3的winutils.exe工具
IntelliJ IDEA 2017.3 x64
IDEA 2017.3 的scala支持包
Spark2.1.1
Scala2.11.4
第0步 配置系统环境变量
0.1 Jdk1.8,Scala2.11.4配置就行不细说
0.2 Hadoop在win下的配置:(这里用的是2.7.3)
拷贝集群中的hadoop2.7.3安装路径,放到win下任意盘符的根目录
下载Hadoop2.7.3的winutils.exe工具链接:https://pan.baidu.com/s/1pKWAGe3 密码:zyi7
用该bin替换原来的hadoop的bin目录
将hadoop2.7.3配置到系统环境变量中,hadoop2.7.3/bin可以不用配
第一步 配置idea
1.1下载并安装(https://www.jetbrains.com/idea/)
安装后先别启动,等待破解
破解(如果经济条件可以的话,尽量支持正版,毕竟这么好的工具)
下载破解包:链接:https://pan.baidu.com/s/1eRSjwJ4 密码:mo6d
将该破解包直接拷贝到安装目录的bin目录即可
1.2 配置idea环境
下载IDEA 2017.3 的scala支持包
地址:链接:https://pan.baidu.com/s/1mixLiPU 密码:dbzu
安装IDEA 2017.3 的scala支持包(必做)

第二步 开发
2.1 创建项目(maven项目,便于开发,创建同时支持java和scala的项目)
maven-archetype-quickstartolve/70/gravity/SouthEast)

请忽略组id里的内容,瞎起的;删除版本的快照

2.2 修改pom.xml文件,添加个框架所用到的依赖
添加以下内容:
<properties>
<project.build.sourceEncoding>UTF-8project.build.sourceEncoding>
<scala.version>2.11.4scala.version>
<hbase.version>1.2.5hbase.version>
<spark.version>2.1.1spark.version>
<hadoop.version>2.7.3hadoop.version>
properties>
<dependencies>
<dependency>
<groupId>junitgroupId>
<artifactId>junitartifactId>
<version>3.8.1version>
<scope>testscope>
dependency>
<dependency>
<groupId>org.scala-langgroupId>
<artifactId>scala-libraryartifactId>
<version>${scala.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-core_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-streaming_2.11artifactId>
<version>${spark.version}version>
<scope>providedscope>
dependency>
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.11artifactId>
<version>${spark.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-commonartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-hdfsartifactId>
<version>${hadoop.version}version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-clientartifactId>
<version>${hbase.version}version>
dependency>
<dependency>
<groupId>org.apache.hbasegroupId>
<artifactId>hbase-serverartifactId>
<version>${hbase.version}version>
dependency>
dependencies>
<build>
<sourceDirectory>src/main/javasourceDirectory>
<testSourceDirectory>src/test/javatestSourceDirectory>
<plugins>
<plugin>
<artifactId>maven-assembly-pluginartifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependenciesdescriptorRef>
descriptorRefs>
<archive>
<manifest>
<maniClass>maniClass>
manifest>
archive>
configuration>
<executions>
<execution>
<id>make-assemblyid>
<phase>packagephase>
<goals>
<goal>singlegoal>
goals>
execution>
executions>
plugin>
<plugin>
<groupId>org.codehaus.mojogroupId>
<artifactId>exec-maven-pluginartifactId>
<version>1.3.1version>
<executions>
<execution>
<goals>
<goal>execgoal>
goals>
execution>
executions>
<configuration>
<executable>javaexecutable>
<includeProjectDependencies>falseincludeProjectDependencies>
<classpathScope>compileclasspathScope>
<mainClass>com.dt.spark.SparkApps.AppmainClass>
configuration>
plugin>
<plugin>
<groupId>org.apache.maven.pluginsgroupId>
<artifactId>maven-compiler-pluginartifactId>
<configuration>
<source>1.6source>
<target>1.6target>
configuration>
plugin>
plugins>
build>2.3 添加集群的配置文件到我们的项目中去
将hadoop,hbase的配置文件复制到resources文件夹下

第三步 写代码,实现案例
案例一 用java实现一个wordcount案例
装备测试文件
我将words.txt编辑好之后放到了hdfs上

查看words.txt的内容

红框中就是我们的words.txt,可以看到,每个单词间使用空格分割的
JavaWordCount代码如下:
package com.shanshu.demo;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.sql.SparkSession;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
import java.util.regex.Pattern;
public class JavaWordCount {
private static final Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
/*if (args.length < 1) {
System.err.println("Usage: JavaWordCount ");
System.exit(1);
}*/
System.setProperty("hadoop.home.dir","E:\\hadoop-2.7.3");
SparkSession spark = SparkSession
.builder().master("spark://192.168.10.84:7077")
.appName("JavaWordCount")
.getOrCreate();
spark.sparkContext()
.addJar("E:\\myIDEA\\sparkDemo\\out\\artifacts\\sparkDemo_jar\\sparkDemo.jar");
JavaRDD lines = spark.read().textFile("hdfs://192.168.10.82:8020/user/jzz/word/words.txt").javaRDD();
JavaRDD words = lines.flatMap(new FlatMapFunction() {
@Override
public Iterator call(String s) {
return Arrays.asList(SPACE.split(s)).iterator();
}
});
JavaPairRDD ones = words.mapToPair(
new PairFunction() {
@Override
public Tuple2 call(String s) {
return new Tuple2(s, 1);
}
});
JavaPairRDD counts = ones.reduceByKey(
new Function2() {
@Override
public Integer call(Integer i1, Integer i2) {
return i1 + i2;
}
});
List> output = counts.collect();
for (Tuple2 tuple : output) {
System.out.println(tuple._1() + ": " + tuple._2());
}
spark.stop();
}
}
请注意:代码中用到@Override时,需要修改一下java的版本,不然报错

修改Project的java版本
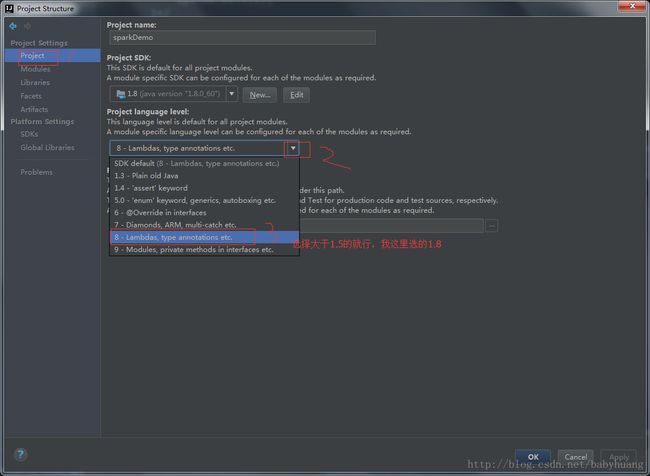
修改Module的java版本

说明:在本地运行代码也就是把打好的jar添加到代码中
打jar包的步骤如下:
i 添加路径




注:有时需要拷贝生成的jar到集群上去运跑,为了防止编译过后的jar过大,删除这些jar

ii 编译


iii 编译的结果

iv复制该jar包在磁盘中的目录

将这个路径写到代码中(必须做,不然不能在本地运行)
如下:

v 执行代码,成功后可以看到结果如下

案例二 用scala代码实现读取hbase的数据
准备工作:在hbase中建一张表fruit,列族为info,并插入数据(已建好)
查看:

i 拷贝hbase的配置文件到idea的resources目录

ii 添加scala的jar

iii 在main目录下创建一个scala的文件夹,设置scala为source

iv 目录拷贝java目录下的META-INF目录到scala下,删除MANIFEST.MF文件,创建包

v 写scala代码

代码如下:
package com.shanshu.scala
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.{SparkConf, SparkContext}
object ReadHbase {
def main(args: Array[String]): Unit = {
val conf = HBaseConfiguration.create()
conf.set("hbase_zookeeper_property_clientPort","2181")
conf.set("hbase_zookeeper_quorum","192.168.10.82")
val sparkConf = new SparkConf().setMaster("local[3]").setAppName("readHbase")
val sc = new SparkContext(sparkConf)
//设置查询的表名
conf.set(TableInputFormat.INPUT_TABLE, "fruit")
val stuRDD = sc.newAPIHadoopRDD(conf, classOf[TableInputFormat],
classOf[org.apache.hadoop.hbase.io.ImmutableBytesWritable],
classOf[org.apache.hadoop.hbase.client.Result])
//遍历输出
stuRDD.foreach({ case (_,result) =>
val key = Bytes.toString(result.getRow)
val name = Bytes.toString(result.getValue("info".getBytes,"name".getBytes))
val color = Bytes.toString(result.getValue("info".getBytes,"color".getBytes))
val num = Bytes.toString(result.getValue("info".getBytes,"num".getBytes))
val people = Bytes.toString(result.getValue("info".getBytes,"people".getBytes))
println("Row key:"+key+" Name:"+name+" color:"+color+" num:"+num+" people"+people)
})
sc.stop()
}
}
vi 同样,打jar包(非必须,在集群上执行时才需要)
删除原来的jar,因为我们这次要选择scala的主类

vii 运行结果如下:

QQ:2816942401(广告勿扰)