vmware(centos7)下搭建hadoop2.5.2环境
1、虚拟机安装centos7(比较简单,自行安装)
2、创建用户密码hadoop/hadoop
[root@localhost home]# adduser hadoop
[root@localhost home]# passwd hadoop
修改主机名并查看
[root@localhost hadoop]# sudo hostnamectl set-hostname "master"
[root@localhost hadoop]# hostnamectl status --transient
master
[root@localhost hadoop]# hostnamectl status --static
master
手动修改/etc/hosts
[root@localhost hadoop]# vim /etc/hosts
127.0.0.1 localhost.localdomain localhost
::1 localhost6.localdomain6 localhost6
192.168.189.136 master
192.168.189.138 slave2
192.168.189.137 slave1
master 192.168.189.136
重启
3、设置ip
首先关闭VMware的DHCP:
Edit->Virtual Network Editor
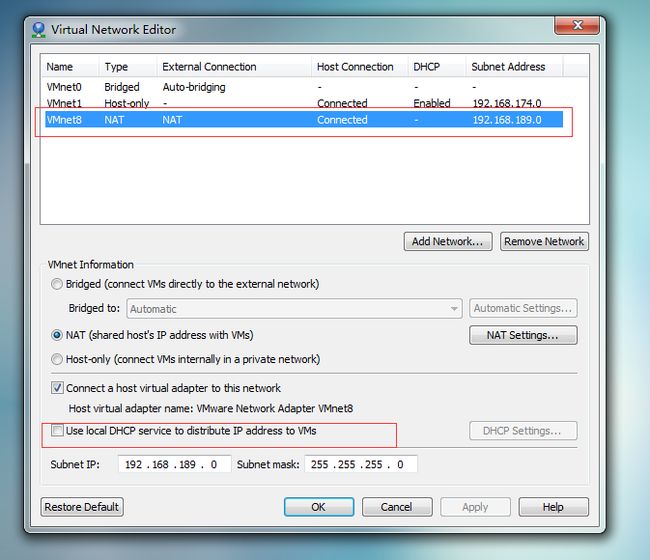
选择VMnet8,去掉Use local DHCP service to distribute IP address to VMs选项。点击NAT Settings查看一下GATEWAY地址:
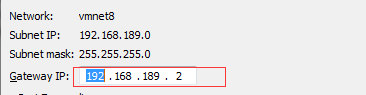
点击OK就可以了。
进入如下目录
[root@localhost hadoop]# cd /etc/sysconfig/network-scripts/
[root@localhost network-scripts]# ls
ifcfg-ens33 ifdown-bnep
[root@localhost network-scripts]# vim ifcfg-ens33
修改 BOOTPROTO="static"
添加如下内容
NETMASK=255.255.255.0
IPADDR=192.168.189.136
PREFIXO=24
GATEWAY=192.168.189.2
DNS1=192.168.189.2
:wq 保存并退出
重启网络
[root@localhost network-scripts]# service network restart
测试 ping www.baidu.com
b-关闭防火墙
systemctl stop firewalld.service --关闭防火墙
systemctl disable firewalld.service --永久关闭
安装软件 [root@master ~]# yum install -y tree
4、安装ssh,并且设置无密码登陆
切换用户:[root@master ~]# su hadoop
进入用户主目录:[hadoop@master root]$ cd ~
创建文件夹:[hadoop@master ~]$ mkdir .ssh
修改权限(可选):[hadoop@master ~]$ chmod 744 .ssh
生成加密文件:[hadoop@master ~]$ ssh-keygen -t rsa -P '' ##回车即可
追加文件:[hadoop@master ~]$ cat ~/.ssh/id_rsa.pub>>~/.ssh/authorized_keys
修改权限:[hadoop@master ~]$ chmod 644 ~/.ssh/authorized_keys
切换回root用户:[hadoop@master ~]$ su
编辑文件:[root@master hadoop]# vim /etc/ssh/sshd_config
确保下面的可用(去掉前面的#)
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
:wq ##保存并退出重启服务:[root@master hadoop]# service sshd restart
切换用户:[root@master hadoop]# su hadoop
验证:[hadoop@master ~]$ ssh localhost 或者:[hadoop@master ~]$ ssh master
第一次登陆直接输入yes即可,以后即可免登陆
5、安装jdk,参见如下
http://blog.csdn.net/bahaidong/article/details/41848393
6、安装配置hadoop
root用户登录
进入hadoop文件目录:[root@master opt]# cd /opt
解压hadoop文件:[root@master opt]# tar xzvf hadoop-2.5.2.tar.gz
改变用户及群组:[root@master opt]# chown -R hadoop:hadoop hadoop-2.5.2
设置环境变量:[root@master opt]# vim /etc/profile
在文件末尾添加如下
export HADOOP_HOME=/opt/hadoop-2.5.2
export PATH=$PATH:$HADOOP_HOME/bin
:wq ##保存退出
刷新配置:[root@master opt]# . /etc/profile 或者 [root@master opt]# source /etc/profile
验证:[root@master opt]# echo $HADOOP_HOME
/opt/hadoop-2.5.2
切换用户:[root@master etc]# su hadoop
进入如下文件夹并创建下列文件夹
[hadoop@master etc]$ cd /opt/hadoop-2.5.2
[hadoop@master hadoop-2.5.2]$ mkdir -p dfs/name
[hadoop@master hadoop-2.5.2]$ mkdir -p dfs/data
[hadoop@master hadoop-2.5.2]$ mkdir -p tmp
进入文件夹:[hadoop@master hadoop-2.5.2]$ cd etc/hadoop
配置slaves :[hadoop@master hadoop]$ vim slaves
slave1
slave2
:wq ##保存并退出
修改hadoop-env.sh和yarn-env.sh
[hadoop@master hadoop]$ vim hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_71
[hadoop@master hadoop]$ vim yarn-env.sh
export JAVA_HOME=/usr/java/jdk1.7.0_71
修改core-site.xml
[hadoop@master hadoop]$ vim core-site.xml
修改hdfs-site.xml
[hadoop@master hadoop]$ vim hdfs-site.xml
配置mapred-site.xml
[hadoop@master hadoop]$ cd /opt/hadoop-2.5.2
[hadoop@master hadoop-2.5.2]$ cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
[hadoop@master hadoop-2.5.2]$ vim etc/hadoop/mapred-site.xml
配置yarn-site.xml
[hadoop@master hadoop-2.5.2]$ vim etc/hadoop/yarn-site.xml
1)伪分布配置
2)集群配置
7、配置另两台机器
1)按照上述方法配置另两台机器
2)关机,复制两台slave
[root@master opt]# shutdown
修改网卡配置与主机名
查看ip
[hadoop@master hadoop-2.5.2]$ ip addr
1: lo:
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33:
link/ether 00:0c:29:56:c7:fd brd ff:ff:ff:ff:ff:ff
inet 192.168.189.136/24 brd 192.168.189.255 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe56:c7fd/64 scope link
valid_lft forever preferred_lft forever
注意看2:后面的ens33就是网卡名,然后编辑网卡配置
[hadoop@master hadoop-2.5.2]$ vim /etc/sysconfig/network-scripts/ifcfg-ens33
HWADDR="00:0C:29:56:C7:FD" ##上面标红的为mac地址
TYPE="Ethernet"
BOOTPROTO="static"
DEFROUTE="yes"
PEERDNS="yes"
PEERROUTES="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_PEERDNS="yes"
IPV6_PEERROUTES="yes"
IPV6_FAILURE_FATAL="no"
NAME="ens33"
UUID="be8a81d8-3a44-49b8-9b5f-b08e836c7811"
ONBOOT="yes"
NETMASK=255.255.255.0
IPADDR=192.168.189.136 ##修改ip
PREFIXO=24
GATEWAY=192.168.189.2
DNS1=192.168.189.2
:wq ##保存退出
修改主机名参考上面的文档
3、配置ssh无密码登录
在master机器上
[hadoop@master .ssh]$ ssh-copy-id hadoop@slave1
在salve机器上
[root@slave1 ~]# cat /home/hadoop/.ssh/id_rsa.pub | ssh hadoop@master 'cat >> ~/.ssh/authorized_keys'
两台机器修改的内容相似
8、格式化master的namenode,启动并测试
以hadoop用户登录
[hadoop@master hadoop-2.5.2]$ hdfs namenode -format
启动:[hadoop@master hadoop-2.5.2]$ ./sbin/start-dfs.sh
启动:[hadoop@master hadoop-2.5.2]$ ./sbin/start-yarn.sh
在各个机器上用jps查看节点
查看master的jps
[hadoop@master hadoop-2.5.2]$ jps
12121 Jps
10715 NameNode
10928 SecondaryNameNode
11087 ResourceManager
查看slave的jps
[hadoop@slave1 logs]$ jps
8030 Jps
7122 DataNode
7254 NodeManager
查看各节点日志
查看master是否监听其他节点
[hadoop@master hadoop-2.5.2]$ netstat -an | grep 9000
浏览器查看
浏览器打开 http://master:50070/,会看到hdfs管理页面
浏览器打开 http://master:8088/,会看到hadoop进程管理页面
浏览器打开 http://master:8088/cluster 查看cluster情况
验证(WordCount验证)
1.dfs上创建input目录
[hadoop@master hadoop-2.5.2]$ bin/hadoop fs -mkdir -p input
2.把hadoop目录下的README.txt拷贝到dfs新建的input里
[hadoop@master hadoop-2.5.2]$ bin/hadoop fs -copyFromLocal README.txt input
3.运行WordCount
[hadoop@master hadoop-2.5.2]$ bin/hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.5.2-sources.jar org.apache.hadoop.examples.WordCount input output
4.运行完毕后,查看单词统计结果
[hadoop@master hadoop-2.5.2]$ bin/hadoop fs -cat output/*
假如程序的输出路径为output,如果该文件夹已经存在,先删除
[hadoop@master hadoop-2.5.2]$ bin/hadoop dfs -rmr output
关闭hadoop
[hadoop@master hadoop-2.5.2]$ ./sbin/stop-dfs.sh
[hadoop@master hadoop-2.5.2]$ ./sbin/stop-yarn.sh