linux(centos7)基于hadoop2.5.2安装spark1.2.1
1、安装hadoop参考
http://blog.csdn.net/bahaidong/article/details/41865943
2、安装scala参考
http://blog.csdn.net/bahaidong/article/details/44220633
3、安装spark
下载spark最新版spark-1.2.1-bin-hadoop2.4.tgz
http://www.apache.org/dyn/closer.cgi/spark/spark-1.2.1/spark-1.2.1-bin-hadoop2.4.tgz
上传到linux上/opt下面,解压
[root@master opt]# tar -zxf spark-1.2.1-bin-hadoop2.4.tgz
修改属组(与hadoop一个用户)
[root@master opt]# chown -R hadoop:hadoop spark-1.2.1-bin-hadoop2.4
查看权限
[root@master opt]# ls -ll
drwxrwxr-x 10 hadoop hadoop 154 2月 3 11:45 spark-1.2.1-bin-hadoop2.4
-rw-r--r-- 1 root root 219309755 3月 12 13:41 spark-1.2.1-bin-hadoop2.4.tgz
添加环境变量
[root@master spark-1.2.1-bin-hadoop2.4]# vim /etc/profile
export SPARK_HOME=/opt/spark-1.2.1-bin-hadoop2.4
export PATH=$PATH:$SPARK_HOME/bin
:wq #保存并退出
执行
[root@master spark-1.2.1-bin-hadoop2.4]# . /etc/profile
切换用户
[root@master spark-1.2.1-bin-hadoop2.4]# su hadoop
进入conf
[hadoop@master spark-1.2.1-bin-hadoop2.4]$ cd conf
拷贝spark-env.sh.template 到 spark-env.sh
[hadoop@master conf]$ cp spark-env.sh.template spark-env.sh
编辑
[hadoop@master conf]$ vim spark-env.sh
添加如下内容
export JAVA_HOME=/usr/java/jdk1.7.0_71
export SCALA_HOME=/usr/scala/scala-2.11.6
export SPARK_MASTER_IP=192.168.189.136 #集群master的ip
export SPARK_WORKER_MEMORY=2g #worker几点分配给excutors的最大内存,因为三台机器都是2G
export HADOOP_CONF_DIR=/opt/hadoop-2.5.2/etc/hadoop #hadoop集群的配置文件的目录
编辑slaves
[hadoop@master conf]$ cp slaves.template slaves
[hadoop@master conf]$ vim slaves
修改成如下内容
master
slave1
slave2
4、安装另两台slave1与slave2,安装过程与上述过程一样直接拷贝文件即可
[hadoop@master opt]$ scp -r spark-1.2.1-bin-hadoop2.4 root@slave1:/opt/
[hadoop@master opt]$ scp -r spark-1.2.1-bin-hadoop2.4 root@slave2:/opt/
修改slave1的属组
[root@slave1 opt]# chown -R hadoop:hadoop spark-1.2.1-bin-hadoop2.4/
修改slave2的属组
[root@slave2 opt]# chown -R hadoop:hadoop spark-1.2.1-bin-hadoop2.4/
添加slave1的环境变量
[root@slave1 opt]# vim /etc/profile
export SPARK_HOME=/opt/spark-1.2.1-bin-hadoop2.4
export PATH=$PATH:$SPARK_HOME/bin
[root@slave1 opt]# . /etc/profile
添加slave2的环境变量
[root@slave2 opt]# vim /etc/profile
export SPARK_HOME=/opt/spark-1.2.1-bin-hadoop2.4
export PATH=$PATH:$SPARK_HOME/bin
4、启动
首先启动hadoop
[hadoop@master hadoop-2.5.2]$ ./sbin/start-dfs.sh
[hadoop@master hadoop-2.5.2]$ ./sbin/start-yarn.sh
[hadoop@master hadoop-2.5.2]$ jps
25229 NameNode
25436 SecondaryNameNode
25862 Jps
25605 ResourceManager
[hadoop@master hadoop-2.5.2]$
表示启动成功
在启动spark
[hadoop@master spark-1.2.1-bin-hadoop2.4]$ ./sbin/start-all.sh
[hadoop@master spark-1.2.1-bin-hadoop2.4]$ jps
26070 Master
25229 NameNode
26219 Worker
25436 SecondaryNameNode
25605 ResourceManager
26314 Jps
[hadoop@master spark-1.2.1-bin-hadoop2.4]$
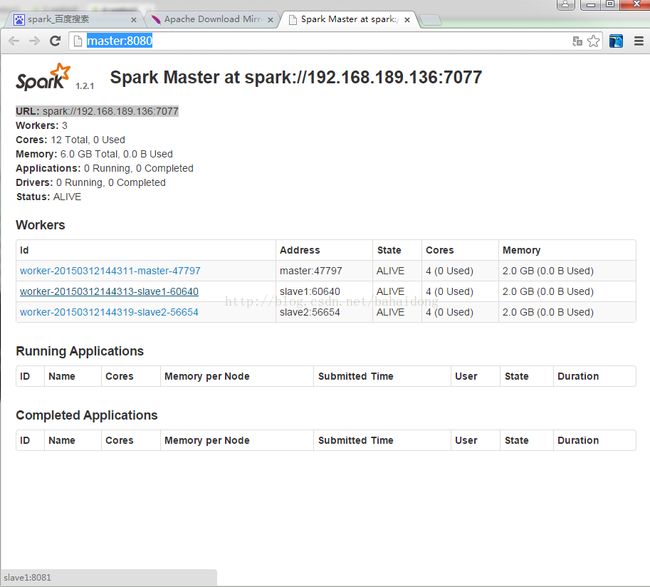
多了Master与Worker表示启动成功
web页面
http://master:8080/
进入bin目录下的spark-shell
[hadoop@master spark-1.2.1-bin-hadoop2.4]$ cd bin
[hadoop@master bin]$ spark-shell
Spark assembly has been built with Hive, including Datanucleus jars on classpath
15/03/12 14:53:48 INFO spark.SecurityManager: Changing view acls to: hadoop
15/03/12 14:53:48 INFO spark.SecurityManager: Changing modify acls to: hadoop
15/03/12 14:53:48 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/03/12 14:53:48 INFO spark.HttpServer: Starting HTTP Server
15/03/12 14:53:48 INFO server.Server: jetty-8.y.z-SNAPSHOT
15/03/12 14:53:48 INFO server.AbstractConnector: Started [email protected]:47965
15/03/12 14:53:48 INFO util.Utils: Successfully started service 'HTTP class server' on port 47965.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 1.2.1
/_/
Using Scala version 2.10.4 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_71)
Type in expressions to have them evaluated.
Type :help for more information.
15/03/12 14:54:44 INFO spark.SecurityManager: Changing view acls to: hadoop
15/03/12 14:54:44 INFO spark.SecurityManager: Changing modify acls to: hadoop
15/03/12 14:54:44 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); users with modify permissions: Set(hadoop)
15/03/12 14:54:47 INFO slf4j.Slf4jLogger: Slf4jLogger started
15/03/12 14:54:47 INFO Remoting: Starting remoting
15/03/12 14:54:48 INFO Remoting: Remoting started; listening on addresses :[akka.tcp://sparkDriver@master:35608]
15/03/12 14:54:48 INFO util.Utils: Successfully started service 'sparkDriver' on port 35608.
15/03/12 14:54:48 INFO spark.SparkEnv: Registering MapOutputTracker
15/03/12 14:54:48 INFO spark.SparkEnv: Registering BlockManagerMaster
15/03/12 14:54:48 INFO storage.DiskBlockManager: Created local directory at /tmp/spark-f86b289e-f690-4e31-9f8c-55814655620b/spark-c6d44057-0149-4046-bddb-7609e9b78984
15/03/12 14:54:48 INFO storage.MemoryStore: MemoryStore started with capacity 267.3 MB
15/03/12 14:54:50 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/03/12 14:54:51 INFO spark.HttpFileServer: HTTP File server directory is /tmp/spark-0ffa51b3-bb0a-4689-8dd5-1d649503b21f/spark-04debaff-ac2c-403f-8c12-13f3e1f63812
15/03/12 14:54:51 INFO spark.HttpServer: Starting HTTP Server
15/03/12 14:54:51 INFO server.Server: jetty-8.y.z-SNAPSHOT
15/03/12 14:54:51 INFO server.AbstractConnector: Started [email protected]:38245
15/03/12 14:54:51 INFO util.Utils: Successfully started service 'HTTP file server' on port 38245.
15/03/12 14:54:52 INFO server.Server: jetty-8.y.z-SNAPSHOT
15/03/12 14:54:52 INFO server.AbstractConnector: Started [email protected]:4040
15/03/12 14:54:52 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
15/03/12 14:54:52 INFO ui.SparkUI: Started SparkUI at http://master:4040
15/03/12 14:54:52 INFO executor.Executor: Starting executor ID
15/03/12 14:54:52 INFO executor.Executor: Using REPL class URI: http://192.168.189.136:47965
15/03/12 14:54:52 INFO util.AkkaUtils: Connecting to HeartbeatReceiver: akka.tcp://sparkDriver@master:35608/user/HeartbeatReceiver
15/03/12 14:54:53 INFO netty.NettyBlockTransferService: Server created on 37564
15/03/12 14:54:53 INFO storage.BlockManagerMaster: Trying to register BlockManager
15/03/12 14:54:53 INFO storage.BlockManagerMasterActor: Registering block manager localhost:37564 with 267.3 MB RAM, BlockManagerId(
15/03/12 14:54:53 INFO storage.BlockManagerMaster: Registered BlockManager
15/03/12 14:54:53 INFO repl.SparkILoop: Created spark context..
Spark context available as sc.
scala>
通过浏览器进入sparkUI
http://master:4040
5、测试
复制README.md文件到hdfs系统上
[hadoop@master spark-1.2.1-bin-hadoop2.4]$ hadoop dfs -copyFromLocal README.md ./
查看文件
[hadoop@master hadoop-2.5.2]$ hadoop fs -ls -R README.md
-rw-r--r-- 2 hadoop supergroup 3629 2015-03-12 15:11 README.md
通过spark-shell读取文件
scala> val file=sc.textFile("hdfs://master:9000/user/hadoop/README.md")
统计Spark出现多少次
scala> val sparks = file.filter(line=>line.contains("Spark"))
scala> sparks.count
15/03/12 15:28:47 INFO mapred.FileInputFormat: Total input paths to process : 1
15/03/12 15:28:47 INFO spark.SparkContext: Starting job: count at
15/03/12 15:28:47 INFO scheduler.DAGScheduler: Got job 0 (count at
15/03/12 15:28:47 INFO scheduler.DAGScheduler: Final stage: Stage 0(count at
15/03/12 15:28:47 INFO scheduler.DAGScheduler: Parents of final stage: List()
15/03/12 15:28:47 INFO scheduler.DAGScheduler: Missing parents: List()
15/03/12 15:28:47 INFO scheduler.DAGScheduler: Submitting Stage 0 (FilteredRDD[2] at filter at
15/03/12 15:28:47 INFO storage.MemoryStore: ensureFreeSpace(2752) called with curMem=187602, maxMem=280248975
15/03/12 15:28:47 INFO storage.MemoryStore: Block broadcast_1 stored as values in memory (estimated size 2.7 KB, free 267.1 MB)
15/03/12 15:28:47 INFO storage.MemoryStore: ensureFreeSpace(1975) called with curMem=190354, maxMem=280248975
15/03/12 15:28:47 INFO storage.MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 1975.0 B, free 267.1 MB)
15/03/12 15:28:47 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:37564 (size: 1975.0 B, free: 267.2 MB)
15/03/12 15:28:47 INFO storage.BlockManagerMaster: Updated info of block broadcast_1_piece0
15/03/12 15:28:47 INFO spark.SparkContext: Created broadcast 1 from broadcast at DAGScheduler.scala:838
15/03/12 15:28:47 INFO scheduler.DAGScheduler: Submitting 2 missing tasks from Stage 0 (FilteredRDD[2] at filter at
15/03/12 15:28:47 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
15/03/12 15:28:47 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, ANY, 1304 bytes)
15/03/12 15:28:47 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, ANY, 1304 bytes)
15/03/12 15:28:47 INFO executor.Executor: Running task 1.0 in stage 0.0 (TID 1)
15/03/12 15:28:47 INFO executor.Executor: Running task 0.0 in stage 0.0 (TID 0)
15/03/12 15:28:48 INFO rdd.HadoopRDD: Input split: hdfs://master:9000/user/hadoop/README.md:0+1814
15/03/12 15:28:48 INFO rdd.HadoopRDD: Input split: hdfs://master:9000/user/hadoop/README.md:1814+1815
15/03/12 15:28:48 INFO Configuration.deprecation: mapred.tip.id is deprecated. Instead, use mapreduce.task.id
15/03/12 15:28:48 INFO Configuration.deprecation: mapred.task.is.map is deprecated. Instead, use mapreduce.task.ismap
15/03/12 15:28:48 INFO Configuration.deprecation: mapred.task.partition is deprecated. Instead, use mapreduce.task.partition
15/03/12 15:28:48 INFO Configuration.deprecation: mapred.job.id is deprecated. Instead, use mapreduce.job.id
15/03/12 15:28:48 INFO Configuration.deprecation: mapred.task.id is deprecated. Instead, use mapreduce.task.attempt.id
15/03/12 15:28:48 INFO executor.Executor: Finished task 1.0 in stage 0.0 (TID 1). 1757 bytes result sent to driver
15/03/12 15:28:48 INFO executor.Executor: Finished task 0.0 in stage 0.0 (TID 0). 1757 bytes result sent to driver
15/03/12 15:28:48 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 567 ms on localhost (1/2)
15/03/12 15:28:48 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 565 ms on localhost (2/2)
15/03/12 15:28:48 INFO scheduler.DAGScheduler: Stage 0 (count at
15/03/12 15:28:48 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
15/03/12 15:28:48 INFO scheduler.DAGScheduler: Job 0 finished: count at
res2: Long = 19
用linux 自带的命令验证
[hadoop@master spark-1.2.1-bin-hadoop2.4]$ grep Spark README.md|wc
19 156 1232