redis持久化机制以及集群操作
redis提供了两种持久化策略
RDB
rdb的持久化策略:按照规则,定时将内存中的数据同步到磁盘当中
snapshot
redis在指定的情况下会触发快照
1.自己配置的快照规则
2.手动执行 save或者 bgsave方法
save 执行内存的数据同步到磁盘上的操作,这个操作会阻塞客户端的请求
bgsave 在后台异步执行快照操作,这个操作不会阻塞客户端的请求
3.执行flushall的时候
清除内存中的数据,只要快照规则不为空,也就是第一个规则存在,那么redis会执行快照
4.执行复制的时候
执行复制的时候
快照文件的存在位置在 redis的bin目录下,里面有一个 dump.rdb文件
快照的实现原理:redis会使用fork函数复制一份当前进程的副本(子进程),fork进程负责把内存的数据同步到磁盘的临时文件,父进程继续处理客户端请求
redis的优缺点:
1.redis会出现数据丢失的情况,执行快照到下一次快照的过程中可能丢失数据
2.可以最大化redis的性能。
AOF
AOF策略,每次执行命令后,把命令本身记录下来
aof会把redis执行的每一条命令追加到磁盘当中。
两种持久化策略可以同时使用,也可以只使用其中的一种,如果同时使用的话,那么redis重启时,会优先使用AOF文件来还原数据。
默认在redis当中aof是没有开启的,我们可以在 redis.conf 文件中开启aof持久化策略,找到 appendonly yes 这样就开启了持久化策略
在redis中执行set命令之后可以看到在redis的bin目录下生成了一个appendonly.aof文件,这个文件中记录了 aof持久化的数据
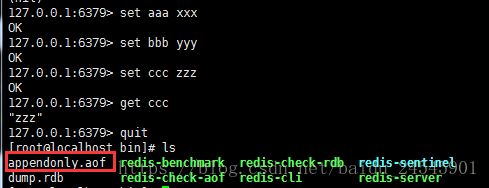
修改redis.conf中的 appendonly yes,重启后执行对数据的变更命令,会在bin目录下生成对应的aof文件,aof文件中会记录所有的操作命令,如下两个参数可以去对aof文件做优化。
在redis.conf文件中还有这样两个属性
auto-aof-rewrite-percentage 100 表示当前aof文件大小超过上一次aof文件大小的百分之多少的时候会进行重写,如果之前没有重写过,以启动时aof文件大小为准
auto-aof-rewrite-min-size 64mb 限制允许重写最小aof文件大小,也就是文件大小小于64m的时候不需要进行优化。
aof重写的原理
aof重写的整个过程是安全的,
同步磁盘数据,redis每次更改数据的时候,aof机制都会将命令记录到aof文件,但是实际上由于操作系统的缓存机制,数据并没有实时的写入到硬盘,而是进入到硬盘的缓存,再通过硬盘缓存机制刷新保存到文件。
appendfsync always 每次执行写入都会进行同步,这个是最安全但是效率比较低的方式
appendfsync everysec 每一秒执行一次
appendfsync no 不主动进行同步操作,由操作系统去执行,这个是最快但是最不安全的方式
aof文件损坏之后如何修复
通过 redis-check-aof-fix 命令对原来的文件进行修复
redis的集群
复制 (master、slave)
哨兵机制
集群
安装redis,然后make,make install PREFIX=/usr/local/redis 然后把安装目录下的 redis.conf 文件拷贝到 启动目录下
redis集群操作,首先先找到 redis.conf目录下的
bind 127.0.0.1 注释掉
daemonize属性设置成 yes
protected-mode no
把改好的redis复制多份到其他的机器上
然后选择一台机器作为主master的redis节点,其他的作为 slave的节点,在slave的节点的 redis.conf中配置下面的信息。
找到 slaveof ip port 给这个属性配置上相应的 master节点的 ip和port(默认6379)
然后把三台服务器都重新启动
使用 redis-cli 命令进入到redis的控制台执行 info replication命令可以看到下面的信息:
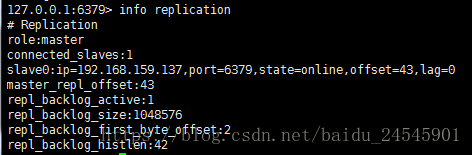
代表这台机器是redis中的master机器
在master中set一条值 set aaa xxx
然后可以在slave这个节点中获取到 aaa的实际值 get aaa
但是如果在从服务器上set值的话会报错
![]()
实现原理
slave第一次或者重连接到master上以后,会向master发送一个 SYNC的命令
master收到 SYNC的时候会做两件事情,
a)执行 bgsave (rdb快照文件)
b)master会把新收到的数据修改命令存入到缓冲区,
可以通过 replconf listening-port 6379 这个命令来检测 master上发出的指令

为了不使slave读取的时候出现脏数据
需要在 slave那端的 redis.conf文件中更改上面的配置
slave-server-stale-data yes 这个配置的含义是必须要完成一个master的同步之后才能去做接下来的操作,否则,读取都会报错。
slave中无法对数据进行写的操作,没有办法对master进行动态选举
复制的方式
1.基于rdb文件的复制
2.无硬盘复制
3.增量复制
redis中的哨兵机制
通过哨兵机制去监控服务器master的状态。
使用redis当中的哨兵机制
首先把 redis安装包下的seentinel.conf 文件拷贝到运行目录下的 sentinel.conf下。
该文件中的port 参数表示的是哨兵监控的端口号,
有一个这样的配置 sentinel monitor mymaster 127.0.0.1 6379 2 ,后面的三个参数表示的意思是监控的主机、监控的端口号、控制有多少投票数(如果三个哨兵集群的话最少两个哨兵投票同意才生效)
sentinel down-after-milliseconds mymaster 30000,这个配置表示的意思是 30秒内如果没有连上则表示已经宕机
redis的哨兵启动
./redis-sentinel ../sentinel.conf
启动之后也同样出现了启动redis的界面

然后这里做一个 让主机 ./redis-cli shutdown 这样的操作,可以看到哨兵的控制台会进行 master的重新选举操作。
重新投票选举出来新的 master机器,
redis中的集群原理
slot槽的概念,在redis当中一共有 16384个槽
根据 key的 CRC16算法,得到的结果再对 16384进行取模,假如有三个节点 16384/3 = 5000多个槽
node1 0 5460
node2 5461 10922
node3 10923 16383
当出现第四个节点的时候,就会出现节点数据的重新分配,涉及到数据的迁移,会从每个节点拿个数据到node4节点