java并发大总结
注:文章参考了各类大神和机构的内容。已标出。
引子:
在一个list中有过亿条的Integer类型的值,如何更快的计算这些值的总和?

要学习的东西那么多!扶我起来。。
慢慢来深入,慢慢来领略大牛的思想融汇。
注:本文汇集各方材料而成,部分不知出处
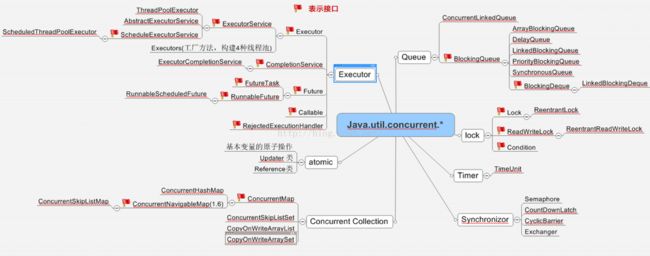
一.线程
想使用多线程?线程之间如何交互呢?有哪些原则?注意点?顺序?
Visibility:通过并发线程修改变量值, 必须将线程变量同步回主存后, 其他线程才能访问到。
Ordering:通过java提供的同步机制或volatile关键字, 来保证内存的访问顺序。(操作系统有自己的顺序)
Cache coherency :它是一种管理多处理器系统的高速缓存区结构,其可以保证数据在高速缓存区到内存的传输中不会丢失或重复。---cpu缓存机制的好与坏
Happens-beforeordering(规则):synchronized,volatile,final,java.util.concurrent.lock|atomic(应对方法)
1.可见性
Java Memory Model (JAVA 内存模型)描述线程之间如何通过内存(memory)来进行交互。 具体说来, JVM中存在一个主存区(Main Memory或Java Heap Memory),对于所有线程进行共享,而每个线程又有自己的工作内存(Working Memory),工作内存中保存的是主存中某些变量的拷贝,线程对所有变量的操作并非发生在主存区,而是发生在工作内存中,而线程之间是不能直接相互访问,变量在程序中的传递,是依赖主存来完成的。
从上图来看,线程A与线程B之间如要通信的话,必须要经历下面2个步骤:
1、线程A把本地内存A中更新过的共享变量刷新到主内存中去。
2、线程B到主内存中去读取线程A之前已更新过的共享变量。
下面通过示意图来说明这两个步骤:
何为可见性:
从上图可知,如果线程A对共享变量X进行了修改,但是线程A没有及时把更新后的值刷入到主内存中,而此时线程B从主内存读取共享变量X的值,所以X的值是原始值,那么我们就说对于线程B来讲,共享变量X的更改对线程B是不可见的
package com.ming.test;
public class TestVisible {
private static boolean ready;
private static int number;
private static int count;
private static class ReaderThread extends Thread {
public void run() {
while(!ready) {
System.out.println(System.currentTimeMillis()+"计数"+count++);
Thread.yield();
}
System.out.println(number);
}
}
public static void main(String[] args) {
for(int i=0;i < 100;i++)
new ReaderThread().start();
number = 11;
ready = true;
}
} 1469690434615计数218
11
11
1469690434614计数214
1469690434614计数211
11
1469690434614计数212
1469690434614计数210
11
1469690434614计数209
11
1469690434614计数208
1469690434614计数207
11
。。。
结果不止100次
分析:--CPU内部缓存,指令优化执行顺序
理论上如果某个线程打印出了11,说明main方法已经执行完毕,即变量ready的值已经设置为true了,那么这以后其它的线程打印的结果应该都是11了,但这里的结果是有些线程读取的ready值仍然为false,这就说明了java虚拟机会对线程中使用到的变量进行缓存,所以就出问题了。
java虚拟机缓存变量,是出于性能的考虑,并且在单线程程序中,或者不存在共享变量的多线程程序中,这都不会出现问题。但是,在有共享变量的多线程程序中,就会发生问题,这里就涉及到共享对象的可见性了,也就是在没有使用同步机制的情况下,一个线程对某个共享对象的修改,并不会立即被其它的线程读取到。上面的代码之所以会出问题,就是因为ReaderThread线程,没有读取到main线程对ready变量修改后的值。要解决上述问题,可以通过在main方法和ReaderThread线程中的run方法中,给访问number和ready值的代码块中加锁来解决。
注意:网上大神说可能打印出0,另外一种结果打印出0来,这个暂时还不是很明白,书中的解释是java虚拟机的内存模型允许编译器对操作顺序进行重排序,并将数值缓存在寄存器中,这样可能在读取到ready修改后的值后,却仍然读取了number的旧值,从而打印出了int的默认值0来。
现在模拟不出来,是不是JDK版本升级了?本人测试7.0
为了保证值一致:---volatile注: 如果一个基本变量被volatile修饰,编译器将不会把它保存到寄存器中,而是每一次都去访问内存中实际保存该变量的位置上。这一点就避免了没有volatile修饰的变量在多线程的读写中所产生的由于编译器优化所导致的灾难性问题。所以多线程中必须要共享的基本变量一定要加上volatile修饰符。当然了,volatile还能让你在编译时期捕捉到非线程安全的代码。
package com.ming.test;
public class TestVisible {
private volatile static boolean ready;
private volatile static int number;
private static int count;
private static class ReaderThread extends Thread {
public void run() {
while(!ready) {
System.out.println(System.currentTimeMillis()+"计数"+count++);
Thread.yield();
}
System.out.println(number);
}
}
public static void main(String[] args) {
for(int i=0;i < 10;i++)
new ReaderThread().start();
number = 11;
ready = true;
}
} 11
1469690848950计数4
11
11
11
11
11
1469690848951计数15
11
11
。。。。
注:在调试过程中遇到的问题
package com.ming.test;
public class TestVisible {
private volatile static boolean ready;
private volatile static int number;
private volatile static int count;
private static class ReaderThread extends Thread {
public void run() {
synchronized(this){
while(!ready) {
count = count+1;
System.out.println(Thread.currentThread().getName()+"计数"+count);
Thread.yield();
Thread.currentThread().stop();
}
System.out.println(number);
}
}
}
public static void main(String[] args) {
for(int i=0;i < 10;i++)
new ReaderThread().start();
number = 11;
ready = true;
}
} Thread-3计数4
Thread-5计数6
Thread-1计数2
Thread-2计数3
Thread-4计数5
Thread-6计数7
Thread-8计数8
Thread-7计数8
11
count值相同的原因??
2.原子性
定义:
原子是世界上的最小单位,原子性由此而来,具有不可分割性。比如 a=0;(a非long和double类型) 这个操作是不可分割的,那么我们说这个操作时原子操作。再比如:a++; 这个操作实际是a = a + 1;是可分割的,所以他不是一个原子操作。非原子操作都会存在线程安全问题,需要我们使用同步技术(sychronized)来让它变成一个原子操作。一个操作是原子操作,那么我们称它具有原子性。java的concurrent包下提供了一些原子类,我们可以通过阅读API来了解这些原子类的用法。比如:AtomicInteger、AtomicLong、AtomicReference等。
3.锁与同步
锁:内部锁、互斥锁、分离锁、闭锁、顺序锁、读写锁、独占锁、分拆锁、重入锁
先看看synchronized
一、synchronized的实现方案
synchronized比较简单,语义也比较明确,尽管Lock推出后性能有较大提升,但是基于其使用简单,语义清晰明了,使用还是比较广泛的,其应用层的含义是把任意一个非NULL的对象当作锁。当synchronized作用于方法时,锁住的是对象的实例(this),当作用于静态方法时,锁住的是Class实例,又因为Class的相关数据存储在永久带,因此静态方法锁相当于类的一个全局锁,当synchronized作用于一个对象实例时,锁住的是对应的代码块。在Sun的HotSpot JVM实现中,其实synchronized锁还有一个名字:对象监视器。
当多个线程一起访问某个对象监视器的时候,对象监视器会将这些请求存储在不同的容器中。(获得锁的流程)
1、 Contention List:竞争队列,所有请求锁的线程首先被放在这个竞争队列中
2、 Entry List:Contention List中那些有资格成为候选资源的线程被移动到Entry List中
3、 Wait Set:哪些调用wait方法被阻塞的线程被放置在这里
4、 OnDeck:任意时刻,最多只有一个线程正在竞争锁资源,该线程被成为OnDeck
5、 Owner:当前已经获取到所资源的线程被称为Owner
6、 !Owner:当前释放锁的线程
下图展示了他们之前的关系
JVM
每次从队列的尾部取出一个数据用于锁竞争候选者( OnDeck ),但是并发情况下, ContentionList 会被大量的并发线程进行 CAS 访问,为了降低对尾部元素的竞争, JVM 会将一部分线程移动到 EntryList 中作为候选竞争线程。 Owner 线程会在 unlock 时,将 ContentionList 中的部分线程迁移到 EntryList 中,并指定 EntryList 中的某个线程为 OnDeck 线程(一般是最先进去的那个线程)。 Owner 线程并不直接把锁传递给 OnDeck 线程,而是把锁竞争的权利交个 OnDeck , OnDeck 需要重新竞争锁 。这样虽然牺牲了一些公平性,但是能极大的提升系统的吞吐量,在 JVM 中,也把这种选择行为称之为“竞争切换”。OnDeck线程获取到锁资源后会变为Owner线程,而没有得到锁资源的仍然停留在EntryList中。如果Owner线程被wait方法阻塞,则转移到WaitSet队列中,直到某个时刻通过notify或者notifyAll唤醒,会重新进去EntryList中。
处于ContentionList、EntryList、WaitSet中的线程都处于阻塞状态,该阻塞是由操作系统来完成的。该线程被阻塞后则进入内核调度状态,会导致系统在用户和内核之间进行来回切换,严重影响锁的性能。为了缓解上述性能问题,JVM引入了自旋锁。原理非常简单,如果Owner线程能在很短时间内释放锁资源,那么哪些等待竞争锁的线程可以稍微等一等(自旋)而不是立即阻塞,当Owner线程释放锁后可立即获取锁,进而避免用户线程和内核的切换。但是Owner可能执行的时间会超过设定的阈值,争用线程在一定时间内还是获取不到锁,这是争用线程会停止自旋进入阻塞状态。基本思路就是先自旋等待一段时间看能否成功获取,如果不成功再执行阻塞,尽可能的减少阻塞的可能性,这对于占用锁时间比较短的代码块来说性能能大幅度的提升!
但是有个头大的问题,何为自旋?其实就是执行几个空方法,稍微等一等,也许是一段时间的循环,也许是几行空的汇编指令,其目的是为了占着CPU的资源不释放,等到获取到锁立即进行处理。但是如何去选择自旋的执行时间呢?如果自旋执行时间太长,会有大量的线程处于自旋状态占用CPU资源,进而会影响整体系统的性能。因此自旋的周期选的额外重要!
Synchronized在线程进入ContentionList时,等待的线程就通过自旋先获取锁,如果获取不到就进入ContentionList,这明显对于已经进入队列的线程是不公平的,还有一个不公平的事情就是自旋获取锁的线程还可能直接抢占OnDeck线程的锁资源。
在JVM6以后还引入了一种偏向锁,主要用于解决无竞争下面锁的性能问题。我们首先来看没有这个会有什么样子的问题。
现在基本上所有的锁都是可重入的,即已经获取锁的线程可以多次锁定/解锁监视对象,但是按照之前JVM的设计,每次加锁解锁都采用CAS操作,而CAS会引发本地延迟(下面会讲原因),因此偏向锁希望线程一旦获取到监视对象后,之后让监视对象偏向这个锁,进而避免多次CAS操作,说白了就是设置了一个变量,发现是这个线程过来的就避免再走加锁解锁流程。
Lock的实现
与synchronized不同的是,Lock书纯Java实现的,与底层的JVM无关。在java.util.concurrent.locks包中有很多Lock的实现类,常用的有ReentrantLock、ReadWriteLock(实现类ReentrantReadWriteLock),其实现都依赖java.util.concurrent.AbstractQueuedSynchronizer类(简称AQS),实现思路都大同小异,因此我们以ReentrantLock作为讲解切入点。
分析之前我们先来花点时间看下AQS。AQS是我们后面将要提到的CountDownLatch/FutureTask/ReentrantLock/RenntrantReadWriteLock/Semaphore的基础,因此AQS也是Lock和Excutor实现的基础。它的基本思想就是一个同步器,支持获取锁和释放锁两个操作。
获取锁:首先判断当前状态是否允许获取锁,如果是就获取锁,否则就阻塞操作或者获取失败,也就是说如果是独占锁就可能阻塞,如果是共享锁就可能失败。另外如果是阻塞线程,那么线程就需要进入阻塞队列。当状态位允许获取锁时就修改状态,并且如果进了队列就从队列中移除。
while(synchronization state does not allow acquire){
enqueue current thread if not already queued;
possibly block current thread;
}
dequeue current thread if it was queued;
释放锁:这个过程就是修改状态位,如果有线程因为状态位阻塞的话,就唤醒队列中的一个或者更多线程。
update synchronization state;
if(state may permit a blocked thread to acquire)
unlock one or more queued threads;
要支持上面两个操作就必须有下面的条件:
1、 状态位必须是原子操作的
2、 阻塞和唤醒线程
3、 一个有序的队列,用于支持锁的公平性
怎么样才能满足这几个条件呢?
1、 原子操作状态位,前面我们已经提到了,实际JDK中也是通过一个32bit的整数位进行CAS操作来实现的。(compare and swap)
2、 阻塞和唤醒,JDK1.5之前的API中并没有阻塞一个线程,然后在将来的某个时刻唤醒它(wait/notify是基于synchronized下才生效的,在这里不算),JDK5之后利用JNI在LockSupport 这个类中实现了相关的特性!
3、 有序队列:在AQS中采用CLH队列来解决队列的有序问题。
我们来看下ReentrantLock的调用过程
经过源码分析,我们看到ReentrantLock把所有的Lock都委托给Sync类进行处理,该类继承自AQS,其类关系图如下
其中
Sync 又有两个 final static 的子类 NonfairSync 和 FairSync 用于支持 非公平锁和公平锁 。我们先来挑一个看下对应 Reentrant.lock() 的调用过程(默认为非公平锁)
这些模版很难让我们直观的看到整个调用过程,但是通过上面的过程图和
AbstractQueuedSynchronizer 的注释可以看出, AbstractQueuedSynchronizer抽象了大多数Lock 的功能,而只把 tryAcquire(int) 委托给子类进行多态实现。 tryAcquire 用于判断对应线程事都能够获取锁,无论成功与否, AbstractQueuedSynchronizer 都将处理后面的流程。简单来讲,AQS会把所有请求锁的线程组成一个CLH的队列,当一个线程执行完毕释放锁(Lock.unlock())的时候,AQS会激活其后继节点,正在执行的线程不在队列当中,而那些等待的线程全部处于阻塞状态,经过源码分析,我们可以清楚的看到最终是通过LockSupport.park()实现的,而底层是调用sun.misc.Unsafe.park()本地方法,再进一步,HotSpot在Linux中中通过调用pthread_mutex_lock函数把线程交给系统内核进行阻塞。其运行示意图如下
与
synchronized 相同的是,这个也是一个虚拟队列,并不存在真正的队列示例, 仅存在节点之前的前后关系 。(注:原生的 CLH 队列用于自旋锁, JUC 将其改造为阻塞锁)。和 synchronized 还有一点相同的是,就是当获取锁失败的时候,不是立即进行阻塞,而是先自旋一段时间看是否能获取锁,这对那些已经在阻塞队列里面的线程显然不公平(非公平锁的实现,公平锁通过有序队列强制线程顺序进行),但会极大的提升吞吐量。如果自旋还是获取失败了,则创建一个节点加入队列尾部,加入方法仍采用 CAS 操作,并发对队尾 CAS 操作有可能会发生失败, AQS 是采用自旋循环的方法,知道 CAS 成功!下面我们来看下锁的实现细节!锁的实现依赖与lock()方法,Lock()方法首先是调用acquire(int)方法,不管是公平锁还是非公平锁
| public final void acquire(int arg) { if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg)) selfInterrupt(); } |
Acquire()方法默认首先调用tryAcquire(int)方法,而此时公平锁和不公平锁的实现就不一样了。
1、Sync.NonfairSync.TryAcquire(非公平锁)
nonfairTryAcquire方法是lock方法间接调用的第一个方法,每次调用都会首先调用这个方法,我们来看下对应的实现代码:
| final boolean nonfairTryAcquire(int acquires) { final Thread current = Thread.currentThread(); int c = getState(); if (c == 0) { if (compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); return true; } } else if (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0) // overflow throw new Error("Maximum lock count exceeded"); setState(nextc); return true; } return false; } |
该方法首先会判断当前线程的状态,如果c==0 说明没有线程正在竞争锁。(反过来,如果c!=0则说明已经有其他线程已经拥有了锁)。如果c==0,则通过CAS将状态设置为acquires(独占锁的acquires为1),后续每次重入该锁都会+1,每次unlock都会-1,当数据为0时则释放锁资源。其中精妙的部分在于:并发访问时,有可能多个线程同时检测到c为0,此时执行compareAndSetState(0, acquires))设置,可以预见,如果当前线程CAS成功,则其他线程都不会再成功,也就默认当前线程获取了锁,直接作为running线程,很显然这个线程并没有进入等待队列。如果c!=0,首先判断获取锁的线程是不是当前线程,如果是当前线程,则表明为锁重入,继续+1,修改state的状态,此时并没有锁竞争,也非CAS,因此这段代码也非常漂亮的实现了偏向锁。
Threadlocal
http://www.cnblogs.com/dolphin0520/p/3920407.html