Kylin基本原理
一、Kylin介绍
1.1 现状
Hadoop于2006年初步实现,改变了企业级的大数据存储(基于HDFS)和批处理(主要基于MR)问题,10几年过去了,数据量随着互联网的发展井喷式增长,如何高速、低延迟的分析数据成为后续面临的挑战,辟如我们面临的一些质疑:Hadoop老矣,尚能饭否?
其中也出现过各种各样的框架来协助Hadoop降低访问数据的延迟,比如列存储框架(Columnar Storage)例如:HBase,以及一些“SQL on Hadoop”的批处理框架,其中以Hive为代表的,Impala,Presto,Drill,SparkSQL紧随其后。
大规模并行处理可以利用多台机器,并行计算,用线性增加的硬件资源,来换取计算时间的线性下降。列式存储则是将数据按照列来存放,这样可以在访问数据时只读取需要的列,“硬件横向插拔式拓展”和“面向列存储”大大提高了基于Hadoop查询分析数据的效率,从原来的几个小时,缩小到了几分钟,但是面临完整的业务分析体系,依然需要以小时甚至天来衡量从提交任务到得到结果的时间。这造成了数据分析师大部分时间都停留在等待结果上——一杯咖啡喝完,又打了把王者荣耀,结果依然没出来。
举个例子,假设查询1亿条数据耗时1分钟,那么可能会有如下对应关系:

也就是说我们提到的之前存在并一直在使用的优化机制并没有改变查询本身的时间复杂度,也有解决得到查询时间与数据量成线性增长这一问题。显然,无限制的横向拓展硬件部署,理论上可以无限的缩小查询时间,但是硬件成本极其昂贵,亦然于运维成本。
1.2 Kylin 出发思路
要解决问题,先分析问题核心矛盾点:
1) 大数据查询大多为统计结果,即多条数据经过聚合函数计算后的统计值,原始记录直接作为结果返回的概率极低。
2) 数据分析与描述必须按照维度来进行,业务范围不可能无限大,即,维度也不会大到天文数字这样的级别,展示需求也是如此,那么有价值的“维度组合个数”也是相对有限的,一般不会随着数据量的增加,维度也跟着不断的增加。举个例子,如下查询:
SELECT telephone, sum(duration)
FROM tb_call_records
where call_date=’2018-02’
group by telephone
order by sum(duration) desc;传统方式则是先全表扫描,然后找到符合2月的日期,再按照电话号码聚合,统计每个电话号码这一天所有的通话时长总和,最后排序输出,如果2月份的通话记录有1亿条,则查询会先访问1亿条记录,如果记录增加5倍,则查询效率下降5倍,等待时间提高5倍。
OK,基于以上矛盾,Kylin,出发了。
使用预计算,即把上面例子中的查询结果先计算好,保存下来,下次做相同访问时,就会变得非常快。我们可以先按照维度[call_date, telephone]计算sum(duration),并存储下来,下次如果查询2月,或者其他月份的通话时长时,就可以直接返回了。这样一来,假如之前1亿条记录中有10万个电话号码,那么预计算之后,2月份的通话记录就只有10万条记录了,是原来的1000分之1。无论2月份的通话记录如何增加,我的查询速度也不会改变。那么各种统计结果保存也是需要消耗存储空间的,Kylin核心之一即:空间换时间,闲时定期对已有数据做预计算,并保存结果。这也是除“多硬件大规模并行处理”、“面向列存储”之外的提供大数据快速分析查询的第三技术——“预计算”。
还是那个例子,假设我们的原始数据是:
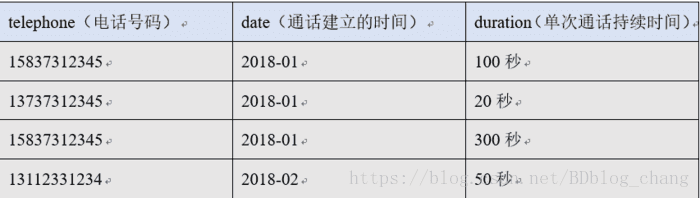
我们此处称:
前两列为:维度
后一列为:度量
我们的预计算便是通过各种不同的“维度”组合,来聚合“度量”。
1.3 Kylin工作原理
给定一个数据模型,我们找到所有可能的维度组合,对于N个维度来说,组合的可能性就有2^N种。对于每一种维度进行度量的聚合运算,将运算结果保存为一个物化视图,称之为:Cuboid。所有维度组合的Cuboid作为一个整体,我们称之为:Cube。所以一个Cube就是多种维度聚合度量的物化视图集。
所以刚才的例子,我们再稍微复杂一点,加上location维度列(通话位置),构建Cube就变成了如下样子:
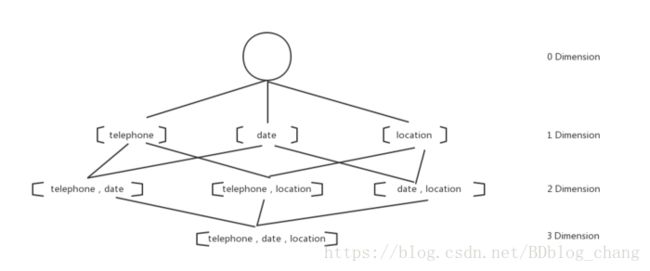
0维度和3维度的共有2个,1维度3个,2维度3个。共2^3 = 8个维度组合。
总结Kylin的工作流程:
1) 指定数据模型,定义维度和度量。
2) 预计算Cube,得到所有Cuboid并保存为物化视图。
3) 执行查询,读取Cuboid并计算,返回查询结果。即,Kylin在查询时,不再去扫描原始数据集,万亿级数据的查询也可以提升到压秒级别。
但存储Cube所消耗的空间一般是原始数据集大小的20~100倍,即原始数据100GB,那么构建出的物化视图大概为20 * 100GB = 2TB。
那么显而易见,Kylin的使命就是OLAP(Online Analytical Processing),即,使得大数据分析快速而简洁。
转自:https://www.cnblogs.com/wzlbigdata/p/8481991.html