Hadoop集群搭建详细步骤(2.6.0)
本文记录在3台物理机上搭建Hadoop 2.6.0的详细步骤及碰到的问题解决。默认使用root账号操作,实际中建议使用专用的hadoop用户账号。
1. 环境
机器: 物理机3台,ip分别为192.168.1.130、192.168.1.132、192.168.1.134
操作系统: CentOS 6.6
Java: 1.7
Hadoop: 2.6.0
请确保JDK已安装,使用java -version确认。
hosts配置
配置主机hosts文件:
vim /etc/hosts
192.168.1.130 master
192.168.1.132 slave1
192.168.1.134 slave2ssh配置
master上的namenode需要无密码ssh访问两台salve,一次需要配置无密码ssh。步骤如下:
在master上:
使用下面命令生成密钥对:
ssh-keygen -t rsa-t参数表示类型,这里选择rsa。选择保存位置的时候直接回车,使用默认的/root/.ssh/id_rsa。提示输入密码的时候,直接回车。如下图:

上述命令将在/root/.ssh目录下生成公钥文件id_rsa.pub。将此文件拷贝到.ssh目录下的authorized_keys:
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keysssh登录本机,确保能够免密码登录:
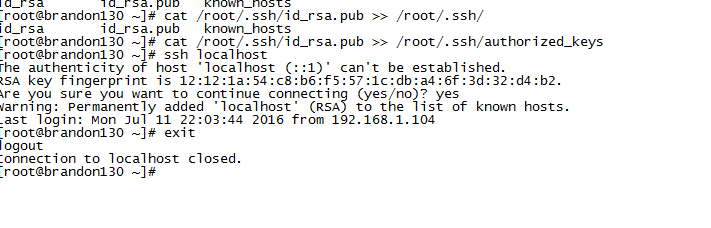
然后将公钥复制到两台slave:
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.1.132
ssh-copy-id -i ~/.ssh/id_rsa.pub root@192.168.1.134ssh-copy-id 把公钥分发即追加到远程主机的 .ssh/authorized_key 上,并确保目录及文件有对应的权限。确保可以从master免密码登录到slave1和slave2:
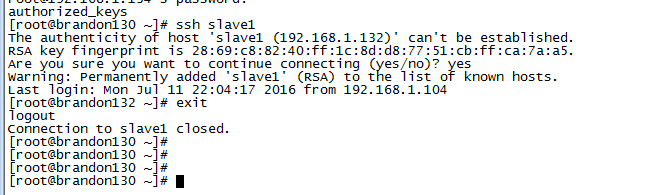

配置文件目录
在master常见name,data,ymp分别用于保存HDFS的namenode文件,数据及临时文件:
mkdir /home/data/hdfs
cd /home/data/hdfs
mkdir name
mkdir data
mkdir tmp然后将hdfs文件拷贝到两台slave对应的位置:
scp -r hdfs/ root@192.168.1.132:/home/data/hdfs
scp -r hdfs/ root@192.168.1.134:/home/data/hdfs2. 安装及配置
下载hadoop 2.6
cd /home/soft/
mkdir hadoop
cd hadoop
wget http://apache.fayea.com/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz解压到home目录下:
tar zxvf hadoop-2.6.0.tar.gz -C /home/配置Hadoop集群:
Hadoop的配置文件位于安装目录下的etc/hadoop文件。
配置core-site.xml
vim /home/hadoop-2.6.0/etc/hadoop/core-site.xml <configuration>
<property>
<name>hadoop.tmp.dirname>
<value>file:/home/data/hdfs/tmpvalue>
<description>A base for other temporary directories.description>
property>
<property>
<name>io.file.buffer.sizename>
<value>131072value>
property>
<property>
<name>fs.default.namename>
<value>hdfs://master:9000value>
property>
<property>
<name>hadoop.proxyuser.root.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.root.groupsname>
<value>*value>
property>
configuration>配置hdfs-site.xml
基本配置包括副本数量,数据存放目录等。
vim /home/hadoop-2.6.0/etc/hadoop/hdfs-site.xml <configuration>
<property>
<name>dfs.replicationname>
<value>2value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:/home/data/hdfs/namevalue>
<final>truefinal>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:/home/data/hdfs/datavalue>
<final>truefinal>
property>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>master:9001value>
property>
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
configuration>配置yarn-site.xml
vim /home/hadoop-2.6.0/etc/hadoop/yarn-site.xml <configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>mastervalue>
property>
<property>
<name>yarn.resourcemanager.addressname>
<value>master:18040value>
property>
<property>
<name>yarn.resourcemanager.scheduler.addressname>
<value>master:18030value>
<property>
<name>yarn.resourcemanager.webapp.addressname>
<value>master:18088value>
property>
<property>
<name>yarn.resourcemanager.resource-tracker.addressname>
<value>master:18025value>
<property>
<name>yarn.resourcemanager.admin.addressname>
<value>master:18141value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.classname>
<value>org.apache.hadoop.mapred.ShuffleHandlervalue>
property>
configuration>配置mapred-site.xml
vim /home/hadoop-2.6.0/etc/hadoop/mapred-site.xml <configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
configuration>配置salve
vim /home/hadoop-2.6.0/etc/hadoop/slaves slave1
slave2将hadoop整个文件copy到两台slave:
cd /home
scp -r hadoop-2.6.0 root@slave1:/home/
scp -r hadoop-2.6.0 root@slave2:/home/
配置path
vim /etc/profile
export HADOOP_HOME=/home/hadoop-2.6.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
. /etc/profile这样在master机器上的任意路径都可以运行hadoop命令。
3. 运行Hadoop
Hadoop提供了很丰富的脚本供使用,主要在安装目录中的bin及sbin。
启动namenode
启动之前需要格式化一下:
在master机器上执行下面的命令,格式化HDFS文件系统:
hadoop namenode -format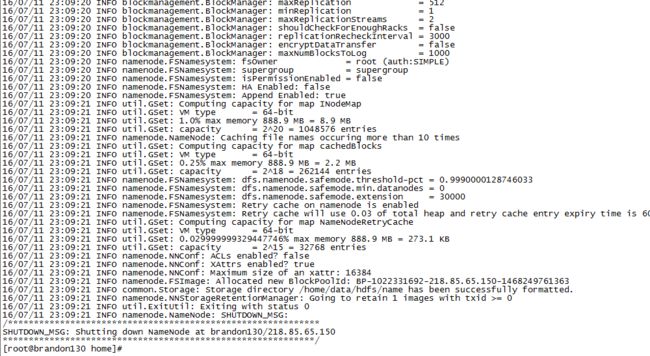
格式化成功,现在启动namenode守护进程:
hadoop-daemon.sh start namenode查看hadoop进程:
ps -ef | grep hadoop可以看到已经有hadoop进程启动:

使用jps命令查看JVM进程:
jps可以看到namenode成功启动:
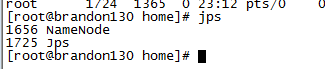
如果提示你找不到jps,请确保你安装了JDK而不是jre并将jdk/bin设置到PATH环境变量中。
启动datanode
启动datanode命令如下:
hadoop-daemons.sh start datanode该命令会远程启动slave上的datanode守护进程。但是启动出现错误:

echo $JAVA_HOME看到已经配置了,查明是因为hadoop-env.sh没有配置JAVA_HOME,修改配置如下(集群其他节点需同步修改):
vim /home/hadoop-2.6.0/etc/hadoop/hadoop-env.sh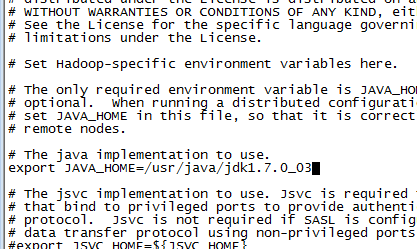
重新启动datanode:

在slave上运行jps,发现没有datanode,查看日志:
vim /home/hadoop-2.6.0/logs/hadoop-root-datanode-brandon132.out
提示mapred-site.xml配置有问题,查看果然如此:

修正后重新启动datanode:

两台slave运行jps都证明datanode启动成功:


上述两个步骤(启动namenode和datanode可以合并为一个命令)
start-dfs.sh 该脚本位于Hadoop安装目录中bin目录下,我们已经加入到PATH环境变量中。
启动YARN:
yarn-daemon.sh start resourcemanager启动nodemanager:
yarm-daemon.sg start nodemanager上述两步一样可以合并为:
start-yarn.sh
在master上运行jps,ResourceManager已启动:

在salve上运行jps,发现只有datanode而没有nodemanager:

查看log日志:

发现shuffle这个aux-serviece配置非法,经查证,新版本中mapreduce.shuffle需改为mapreduce-shuffle,即在mapred-site.xml中配置修改如下(集群其他节点需同步修改):
原来:
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce.shufflevalue>
property>改为下划线:
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>修改后重启,成功:

查看HDFS管理界面:

访问YARN管理界面:

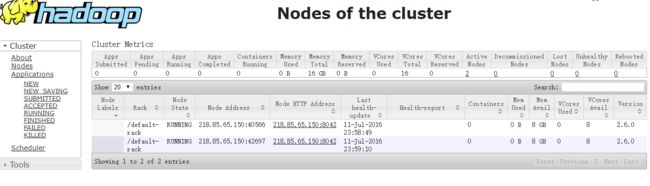
4. 运行实例
搭建完成之后,我们运行一个Mapreduce作业感受一下:
hadoop jar /home/hadoop-2.6.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar pi 5 10启动之后发现总是卡住:

管理界面的状态也一直处于Accepted,没有任何变化:

折腾了很久,总算找到原因,是因为hostname配置与/etc/hosts中的配置不一样,/etc/hosts中master的配置如下:
192.168.1.130 mastermaster机器上使用hostname查,显示为brandon130。先使用hostname命令临时修改一下主机名:
hostname master其他两台slave对应修改。
然后重新提交pi运算作业,总算成功:
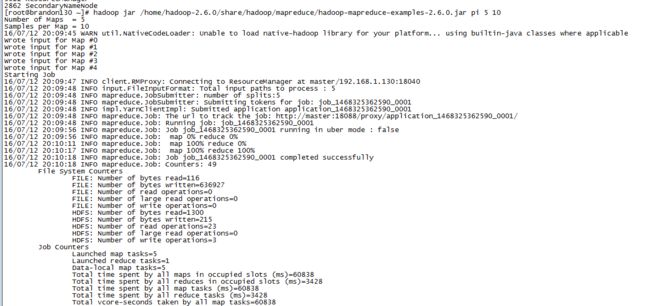

从进度日志可以看到map和reduce作业是可以一定程度上并行的:

查看YARN管理界面:
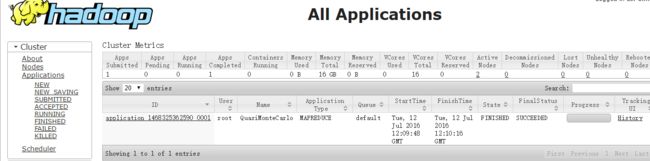
大功告成。
5. 常见问题及其他
1) 防火墙
请确保集群机器的防火墙都关闭,否则可能会出现各种莫名的问题,需要你自己去看日志排查原因。关闭防火墙方法如下:
临时生效,重启后复原:
service iptables start // 开启
service iptables stop // 关闭永久性生效,重启后不会复原
chkconfig iptables on // 开启
chkconfig iptables off // 关闭2) 主机名配置
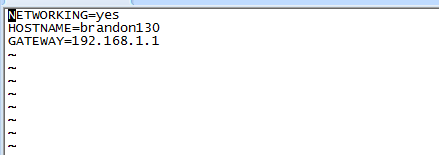
前面提到的主机名修改是临时的,重启机器之后会恢复原来的样子,要永久修改主机名,需要对应修改/etc/sysconfig/network文件,如下图,将HOSTNAME改成对应的master,其他两台对应slave1,slave2。
(完)