《一次Oracle bug的故障排查过程思考》的问题重现解决
在《
为了统计数据,在每次测试前后,各打印次AWR Snapshot。
第一次测试
1. 应用:
使用旧的夜维(无批量提交,虽然delete操作一次删除10000条,但是会在删除所有数据(20万)完成的时候,才会做commit,约需要2分钟,即需要让相应数据和回滚表空间的数据块处于事务进行中状态约2分钟)。
2. 数据库:
未设置10019,存在Bug 13641076的bugfix,未修复Bug 19791273。
3. 执行过程:
当夜维执行到第10次左右的10000条delete操作,应用的响应时间开始变长,数据库CPU idle最低降到了60%左右了,正常时间段,CPU idle一般为80%-90%左右的。
4. 数据:
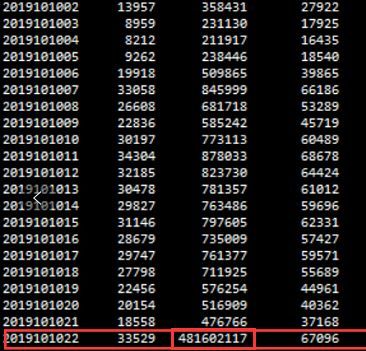
这次夜维执行,22:10-22:12,总计2分钟左右,检索对应业务的update语句逻辑读,从下图可以看出,相比其他小时段,增长了将近1000倍,
从SQL AWR看,这条update语句的逻辑读,大约是224986.5021057557,
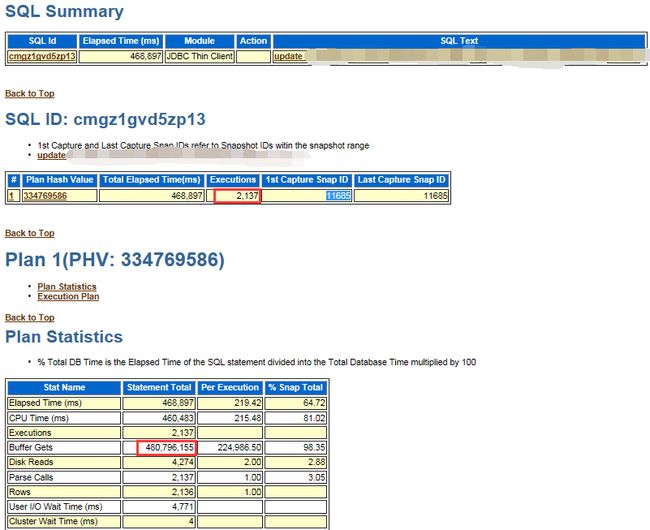
一条使用唯一索引的update语句执行计划,已经是很高效了,22万的逻辑读,就很不正常了,和Bug 19791273的现象Poor UPDATE SQL performance due to space search cache for updates on ASSM segment,很是相像的,
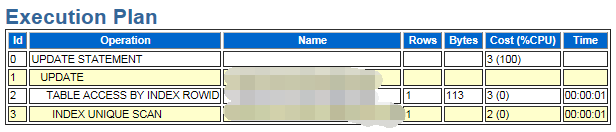
虽然没出现故障当天CPU idle为0的现象,但是有所下降,而且业务update语句的逻辑读,如此之高,应该算是复现了这个问题。
第二次测试
1. 应用:
使用旧的夜维,同时,业务切换至备份集群,重启备集群的连接池和应用,以让Bug 13641076描述的将space search cache从cursor存储改至session,需要重置连接,保证10019事件生效。
2. 数据库:
设置10019事件。
3. 执行过程:
4. 数据:
这次夜维执行,还是2分钟左右,对应SQL AWR,显示update语句逻辑读,这次变成了44.78268251273345,
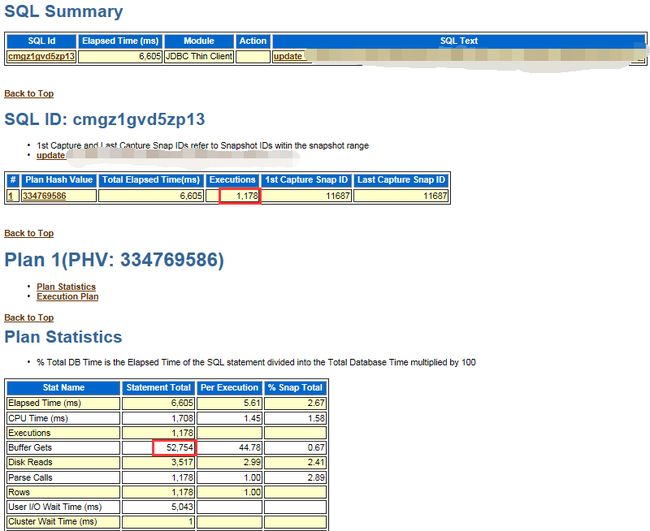
从现象上看,夜维执行中,业务update的逻辑读现在正常了,看来10019事件起到了作用。
第三次测试
1. 应用:
使用旧夜维,为了验证重启连接池的影响,将业务切换至主集群,但是不重启连接池和应用,按照假设和推理,当前数据库的10019在这套集群中,应该是未生效。
2. 数据库:
未做改动。
3. 执行过程:
夜维执行过程中,应用的响应时间,略显提升,但是非常有限,数据库CPU idle最低降到75%,介于首次和第二次测试中间,可以说基本不存在影响。
4. 数据:
从SQL AWR看,update语句的逻辑读,大约是60.03633060853769,

虽然逻辑读和第二次相比,略有提升,但和首次的数据比较,天壤之别。一种可能,就是像《
如果第一次测试,不做commit,而是在执行过程中截断程序,这次测试接着用首次的数据,可能现象上就会更具说服力。
第四次测试
使用新夜维,即带批量提交的删除逻辑,从应用和数据库角度看,时间和CPU idle都和第二次测试相近,基本不存在delete对update的影响,此处不贴数据了。(假设:数据库未设置10019,使用新夜维,从理论上说,影响应该比第一次测试要小)。
从第1、2、3次测试的AWR Compare Report看,和bug中提到的space search cache作用可能相关联的指标,例如data blocks consistent reads - undo records applied,总量分别为479,504、8,705、25,186,从数据上,进一步支撑这个问题的猜测。
这个问题的复现和基本解决,在过程中,确实学到了不少,如《
P.S. AWR相关脚本和指令,
创建AWR Snapshot,
SQL>exec dbms_workload_repository.create_snapshot;
创建AWR,
SQL>@?/rdbms/admin/awrrpt
创建SQL AWR,
SQL>@?/rdbms/admin/awrsqrpt
创建AWR Compare,
SQL>@?/rdbms/admin/awrddrpt.sql