【深度学习框架Keras】RNN、RNN的droput、stacking RNN、双向RNN的应用
说明:
主要参考Francois Chollet《Deep Learning with Python》
代码运行环境为kaggle中的kernels;
数据集jena_climate_2009_2016需要手动添加;
# This Python 3 environment comes with many helpful analytics libraries installed
# It is defined by the kaggle/python docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load in
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import gc
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
import os
print(os.listdir("../input"))
# Any results you write to the current directory are saved as output.
['jena_climate_2009_2016.csv']
一、数据集的介绍以及预处理
1.数据集介绍
该数据集包含了2009到2016年之间采集的14项指标(例如气温、气压、风向等),其中每10分钟进行一次采集。而我们的目标是利用近期的数据预测未来24小时的气温。
2.加载数据集
data = pd.read_csv('../input/jena_climate_2009_2016.csv',index_col=0)
3.绘制气温变化
# 2009到2016年所有的气温
data.iloc[:,1].plot(title='temprature')
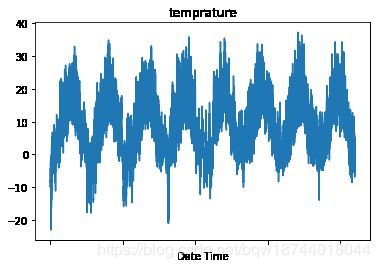
# 数据集中前10天(6*24*10=1440)的气温
data.iloc[:1440,1].plot(title='first 10 days of the temperature')
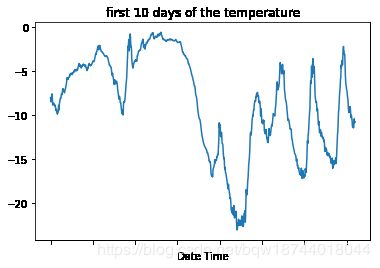
4.数据标准化
from sklearn import preprocessing
# 由于使用前200000的数据进行训练,因此只计算这部分的均值和方差进行标准化
scaler = preprocessing.StandardScaler().fit(data[:200000])
data_scaled = scaler.transform(data)
二、定义Generator产生样本及其标签
# data:原始数据
# lookback:用于预测的滑动窗口的大小。例如lookback为720,表示使用过去720/(6*24)=5天的数据进行预测
# delay:样本的标签是未名多久的数据。例如delay为144,表示要预测未来144/6=24小时的气温
# min_index:产生数据的下边界索引(产生的数据对应的索引不会小于min_index)
# max_index:产生数据的上边界索引(产生的数据对应的索引不会大于max_index)
# shuffle:数据是否进行shuffle
# batch_size:每个batch的样本数
# step:采样数据的周期。如果该值为6表示每60分钟的数据进行1次采样(原始数据是每10分钟一组数据)
def generator(data,lookback,delay,min_index,max_index,shuffle=False,batch_size=128,step=6):
# 如果max_index为None,那么将max_index设为最大的可能值(留出delay后最大的值)
if(max_index is None):
max_index = len(data) - delay - 1
# 当shuffle=False时,i记录当前batch的第1个窗口的上边界
i = min_index + lookback
while(True):
if(shuffle):
# 当前采样样本的索引范围为(min_index+lookback,max_index)
# rows是大小为batch_size的随机采样样本的索引(有重复)
# 由于每次采样是采到长度为looback//step的窗口,rows中的值表示该层采样对应的窗口的上边界
rows = np.random.randint(min_index + lookback,max_index,size=batch_size)
else:
if(i+batch_size>=max_index):
i = min_index + lookback
rows = np.arange(i,min(i+batch_size,max_index))
i += len(rows)
# samples是三维tensor,其三个维度为(样本数量,窗口中的样本数,每个样本的维度)
# 在该问题中:样本数量由batch_size指定,窗口中的样本数由窗口中总样本数除以采样频率,每个样本的维度为14
samples = np.zeros((len(rows),lookback//step,data.shape[-1]))
targets = np.zeros((len(rows),))
for j,row in enumerate(rows):
# rows[j]的rows中第j个索引,该索引作为滑窗的上边界
# rows[j]-lookback是该滑窗的下边界
# indices表示单次采样对应的窗口值的索引
indices = range(rows[j] - lookback,rows[j],step)
samples[j] = data[indices]
# 该窗口的标签由当前窗口上边界后delay个样本组成
targets[j] = data[rows[j]+delay][1]
# 返回batch_size个采样的样本
yield samples,targets
lookback = 1440 # 使用1440/(6*24)=10天的数据进行预测
step= 6 # 数据采样频率为6*10=60分钟,即1个小时
delay = 144 # 预测未来144/6=24小时的气温,即未来1天的气温
batch_size = 128 # 每次训练128个连续10天的样本
train_gen = generator(data_scaled,
lookback=lookback,
delay=delay,
min_index=0,
max_index=200000,
shuffle=True,
step=step,
batch_size=batch_size)
val_gen = generator(data_scaled,
lookback=lookback,
delay=delay,
min_index=200001,
max_index=300000,
step=step,
batch_size=batch_size)
test_gen = generator(data_scaled,
lookback=lookback,
delay=delay,
min_index=300001,
max_index=None,
step=step,
batch_size=batch_size)
# 当shuffle=False时,要覆盖所有验证集中样本需要的迭代次数
val_steps = (300000 - 200001 - lookback)
# 当shuffle=False时,要覆盖所有测试集中样本需要的迭代次数
test_steps = (len(data_scaled) - 300001 - lookback)
三、一个基于常识的、非机器学习的基准方法
一般而言气温是一个连续性的值,因此一种符合直觉性的预测方法就是认为未来24小时的气温和当前气温相同。使用这种方式我们就可以建立一个基本的baseline,这个baseline可以与我们之后使用深度学习方法的效果进行比较,从而度量方法的优劣。
def evaluate_naive_method():
batch_maes = []
for step in range(val_steps):
# 这里samples.shape=(128,240,14):128是batch_size,240表示每小时进行一次采样然后连续10天的数据
samples,targets = next(val_gen)
# 预测未来24小时的期望为当前的气温
preds = samples[:,-1,1]
mae = np.mean(np.abs(preds-targets))
batch_maes.append(mae)
print(np.mean(batch_maes))
loss = evaluate_naive_method()
0.2896994197960971
四、使用基本的全连接神经网络建立一个baseline
1.建立和训练模型
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.Flatten(input_shape=(lookback//step,data_scaled.shape[-1])))
model.add(layers.Dense(32,activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(),loss='mae')
history = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=20,
validation_data=val_gen,
validation_steps=100)
Epoch 1/20
500/500 [==============================] - 8s 16ms/step - loss: 1.0704 - val_loss: 0.7708
...
Epoch 20/20
500/500 [==============================] - 8s 15ms/step - loss: 0.1973 - val_loss: 0.3316
2.绘制loss曲线
import matplotlib.pyplot as plt
def plot_loss(history):
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1,len(loss)+1)
plt.figure()
plt.plot(epochs,loss,'bo',label='Training loss')
plt.plot(epochs,val_loss,'b',label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plot_loss(history)

五、使用循环神经网络建立baseline
全连接神经网络的表现不好,甚至比不上基于常识的非机器学习模型,因为我们没有考虑的气温的时序关系,因此尝试RNN
from keras.models import Sequential
from keras import layers
from keras.optimizers import RMSprop
model = Sequential()
model.add(layers.GRU(32,input_shape=(None,data_scaled.shape[-1])))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(),loss='mae')
history = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=20,
validation_data=val_gen,
validation_steps=100)
Epoch 1/20
500/500 [==============================] - 177s 354ms/step - loss: 0.3063 - val_loss: 0.3028
...
Epoch 20/20
500/500 [==============================] - 177s 353ms/step - loss: 0.2143 - val_loss: 0.3044
plot_loss(history)
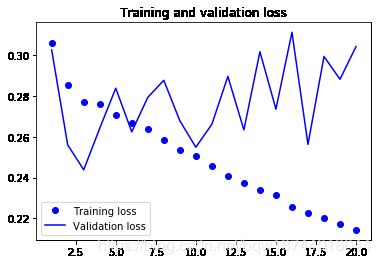
可以看到使用GRU产生了过拟合
六、使用循环dropout抑制过拟合
观测上面模型的loss曲线发现已经发生了过拟合,因此需要使用dropout抑制过拟合。
model = Sequential()
model.add(layers.GRU(32,
dropout = 0.2,# 输入层dropout比率
recurrent_dropout = 0.2,# 循环层dropout比率
input_shape = (None,data_scaled.shape[-1])))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(),loss='mae')
history = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=20,
validation_data=val_gen,
validation_steps=100)
Epoch 1/20
500/500 [==============================] - 198s 396ms/step - loss: 0.3413 - val_loss: 0.2713
...
Epoch 20/20
500/500 [==============================] - 194s 388ms/step - loss: 0.2804 - val_loss: 0.2723
plot_loss(history)

模型不再过拟合
七、循环层堆叠
在使用dropout后模型不再过拟合,但也就是说模型还没有达到最佳性能,因此需要考虑增加网络的容量。这里我们尝试将两个循环层堆叠在一起,这种模型也称为深度循环模型。
model = Sequential()
model.add(layers.GRU(32,
dropout=0.1,
recurrent_dropout=0.5,
return_sequences=True,
input_shape=(None,data_scaled.shape[-1])))
model.add(layers.GRU(64,
activation='relu',
dropout=0.1,
recurrent_dropout=0.5))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(),loss='mae')
history = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=20,
validation_data=val_gen,
validation_steps=100)
Epoch 1/20
500/500 [==============================] - 404s 807ms/step - loss: 0.3366 - val_loss: 0.2526
...
Epoch 20/20
500/500 [==============================] - 405s 811ms/step - loss: 0.2693 - val_loss: 0.2716
plot_loss(history)

八、使用双向GRU
model = Sequential()
model.add(layers.Bidirectional(layers.GRU(32),input_shape=(None,data_scaled.shape[-1])))
model.add(layers.Dense(1))
model.compile(optimizer=RMSprop(),loss='mae')
history = model.fit_generator(train_gen,
steps_per_epoch=500,
epochs=20,
validation_data=val_gen,
validation_steps=100)
Epoch 1/20
500/500 [==============================] - 340s 681ms/step - loss: 0.2932 - val_loss: 0.2746
...
Epoch 20/20
500/500 [==============================] - 342s 683ms/step - loss: 0.1822 - val_loss: 0.3143
plot_loss(history)
