【自然语言处理】文本分类模型_Transformer_TensorFlow实现
一、原始Transformer模型
1. Paper:Attention Is All You Need
2. 该模型是一个Seq2Seq的模型,其包含一个encoder和一个decoder,其结构如下图:

上图中encoder和decoder只包含了一层结构。在原始的模型中,encoder包含6层如上图的结果,decoder也包含6层如上图的结果
二、Attention机制
Attention机制可以看做计算query与key的相似度,然后通过softmax得到每个key对query的贡献度(概率分布);然后使用这个贡献度做为权重,对value进行加权求和得到Attention的最终输出。在NLP中通常key和value是相同的。
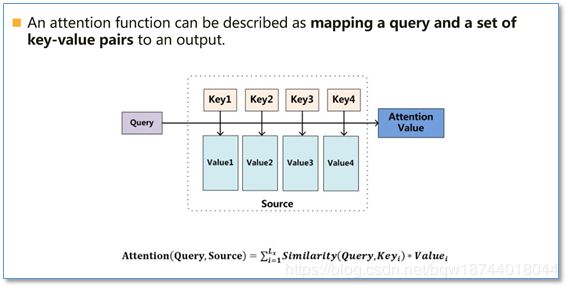
计算相似度的方法通常有点积、拼接等,如下;

三、用于文本分类的Transformer结构
本文中只使用原始Transformer的encoder部分,而且为了体现思想仅使用单层结构,而不是6层;
1.embedding层
获得词的分布式表示
2.positional encoding
由于attention没有包含序列信息(即语句顺序并不影响结构),因此需要加入位置的信息,在transformer中选择将顺序的信息加入到embedding中。
设某个词在句子中的位置为pos,词的embeding维度为 d m o d e l d_{model} dmodel,我们需要产生一个关于pos的维度为 d m o d e l d_{model} dmodel的向量。因此可以使用公式:
P E ( p o s , i ) = p o s 1000 0 2 i / d m o d e l PE(pos,i)=\frac{pos}{10000^{2i/d_{model}}} PE(pos,i)=100002i/dmodelpos来计算pos对应的位置向量的各个维度的值。以pos=1来举例,[ 1 1000 0 0 \frac{1}{10000^0} 1000001, 1 1000 0 2 / d m o d e l \frac{1}{10000^{2/d_{model}}} 100002/dmodel1, 1 1000 0 4 / d m o d e l \frac{1}{10000^{4/d_{model}}} 100004/dmodel1, . . . . . . ...... ...... , 1 1000 0 2 \frac{1}{10000^{2}} 1000021];但是这种方式的编码并没有考虑到相对位置,因此在论文中使用了三角函数对奇偶维进行变化,下面是论文中的位置编码公式:

3.Scaled dot-product attention
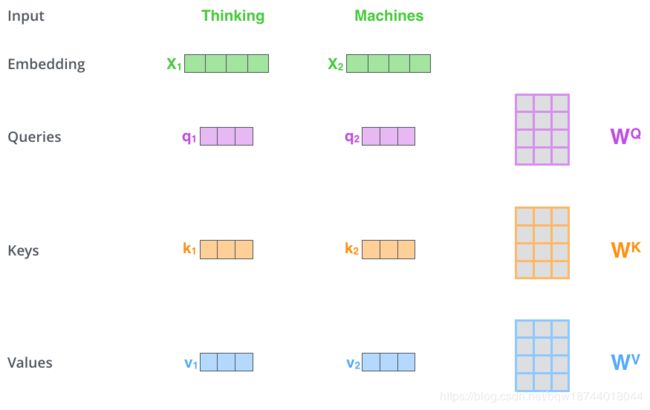
在attention中query、key、value的来源各不相同,但是在该attention中query、key、value均是从同一个输入中产生。如下图中query、key、value均是将输入的embedding乘以一个矩阵产生的:
(可以观测到q,k,v的维度是由权重矩阵的维度决定的,因此维度的大小由设计者决定)
有了q,k,v后,我们先通过点积计算k与q的相似度,并且为了防止相似度放入softmax中太大,因此将点积结果除以 d k \sqrt{d_k} dk,其中 d k d_k dk是k的维度。在将结果放入到softmax中输出当前q与各个k的相似度,如下图:
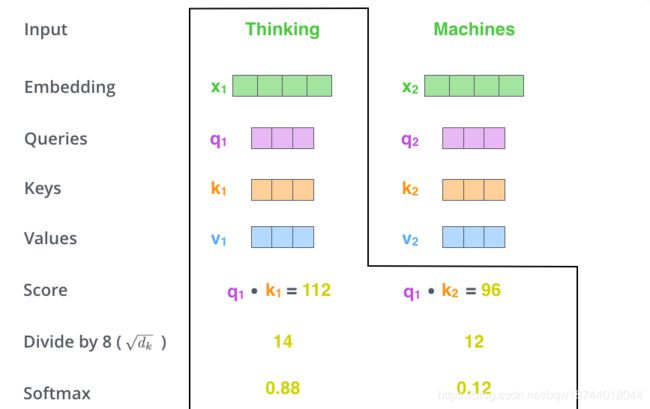
有了q与各个k的相似度以后,使用这些相似度对v进行加权求和,得到当前query的输出

上面介绍了Scaled dot-product attention的向量计算方式,但是在实际中为了加速计算需要使用矩阵的计算方式。下面介绍矩阵计算:
首先对于所有的输出计算对应的q、k、v,如下图:
(这样可以一次计算出所有输入的q、k、v,并记输出的矩阵为Q、K、V)

计算相似度并加权求和
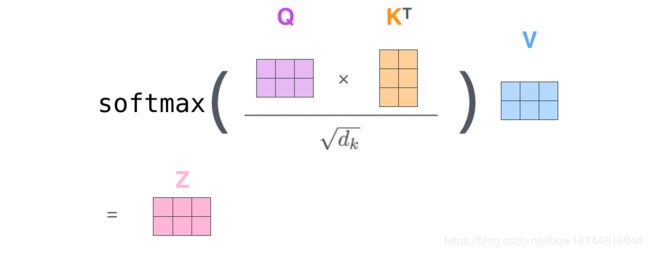
论文中的计算公式:
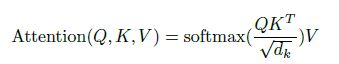
4.Multi-head attention
在论文中他们发现将Q、K、V在 d q , d k , d v d_q,d_k,d_v dq,dk,dv(即每个q\k\v的维度)维度上切成h份,然后分别进行scaled dot-product attention,并将最终的结果合并在一起,其中超参数h就是head的数量。
论文中的公式:

5.Padding mask
因为文本的长度不同,所以我们会在处理时对其进行padding。但是在进行attention机制时,注意力不应该放在padding的部分。因此将这些位置设置为非常大的负数,这样经过softmax后的概率接近与0。
对于矩阵 Q K T QK^T QKT的第i行第j列的元素表示的是第i个query与第j个key的相似度,为了进行padding mask,那么必须要将所有与padding key的相似度设为负无穷。因此生成一个形状与 Q K T QK^T QKT相同的padding 矩阵,其中所有padding key对应的列设为false,其余为true。

6.残差连接
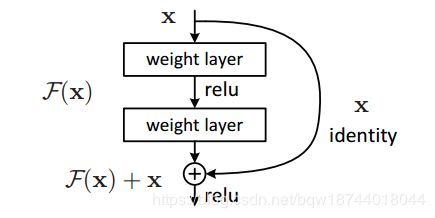
假设网络中某个层对输入x作用后的输出是 F ( x ) F(x) F(x),那么增加残差连接后为 F ( x ) + x F(x)+x F(x)+x。当对该层求偏导时,
7.Layer Normalization
Batch Normalization:设某个batch中的样本均值为 μ B \mu_B μB,样本方差为 σ B 2 \sigma^2_B σB2,那么BN的公式就是 B N ( x i ) = α × x i − μ B σ B 2 + ϵ + β BN(x_i)=\alpha\times\frac{x_i-\mu_B}{\sqrt{\sigma^2_B+\epsilon}}+\beta BN(xi)=α×σB2+ϵxi−μB+β。其主要是沿着batch方向进行的。
Layer Normalization:BN是在batch上计算均值和方差,而LN则是对每个样本计算均值和方差; L N ( x i ) = α × x i − μ L σ L 2 + ϵ + β LN(x_i)=\alpha\times\frac{x_i-\mu_L}{\sqrt{\sigma^2_L+\epsilon}}+\beta LN(xi)=α×σL2+ϵxi−μL+β。可以方向公式中只是均值和方差不同而已。
8.Position-wise Feed-Forward network
这是一个全连接层,包含两个线性变换和一个非线性激活函数ReLU,公式为 F F N ( x ) = m a x ( 0 , x W 1 + b 1 ) W 2 + b 2 FFN(x)=max(0,xW_{1}+b_1)W_{2}+b_2 FFN(x)=max(0,xW1+b1)W2+b2。这个公式还可以用两个大小为1的一维卷积来实现,其中中间层的维度为2048。
三、使用TensorFlow实现模型
import numpy as np
import pandas as pd
import tensorflow as tf
from tensorflow.contrib import rnn
import math
import datetime
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.utils import to_categorical
from sklearn.model_selection import train_test_split
import gc
Using TensorFlow backend.
参数
max_features = 10000 # vocabulary的大小
maxlen = 500
embedding_size = 128
batch_size = 256 # 每个batch中样本的数量
num_heads = 4
num_units = 128 # query,key,value的维度
ffn_dim = 2048
num_epochs = 30
max_learning_rate = 0.001
min_learning_rate = 0.0005
decay_coefficient = 2.5 # learning_rate的衰减系数
dropout_keep_prob = 0.5 # dropout的比例
evaluate_every = 100 # 每100step进行一次eval
加载数据
train = pd.read_csv("../input/labeledTrainData.tsv", header=0,delimiter="\t", quoting=3)
test = pd.read_csv("../input/testData.tsv",header=0,delimiter="\t", quoting=3)
处理数据
# 建立tokenizer
tokenizer = Tokenizer(num_words=max_features,lower=True)
tokenizer.fit_on_texts(list(train['review']) + list(test['review']))
#word_index = tokenizer.word_index
x_train = tokenizer.texts_to_sequences(list(train['review']))
x_train = pad_sequences(x_train,maxlen=maxlen) # padding
y_train = to_categorical(list(train['sentiment'])) # one-hot
x_test = tokenizer.texts_to_sequences(list(test['review']))
x_test = pad_sequences(x_test,maxlen=maxlen) # padding
# 划分训练和验证集
x_train,x_dev,y_train,y_dev = train_test_split(x_train,y_train,test_size=0.3,random_state=0)
del train,test
gc.collect()
24
定义模型
class Transformer(object):
def embedding(self, input_x):
W = tf.Variable(tf.random_uniform([self.vocab_size,self.embedding_size],-1.0,1.0),
name='W',
trainable=True)
input_embedding = tf.nn.embedding_lookup(W, input_x)
return input_embedding
def positional_encoding(self, embedded_words):
# [[0,1,2,...,499],
# [0,1,2,...,499],
# ...
# [0,1,2,...,499]]
positional_ind = tf.tile(tf.expand_dims(tf.range(self.sequence_length), 0), [batch_size, 1]) # [batch_size, sequence_length]
# [sequence_length,embedding_size]
position_enc = np.array([[pos / np.power(10000, 2.*i/self.embedding_size) for i in range(self.embedding_size)]
for pos in range(self.sequence_length)])
position_enc[:, 0::2] = np.sin(position_enc[:, 0::2])
position_enc[:, 1::2] = np.cos(position_enc[:, 1::2])
lookup_table = tf.convert_to_tensor(position_enc,dtype = tf.float32)
# # [batch_size,sequence_length,embedding_size]
positional_output = tf.nn.embedding_lookup(lookup_table, positional_ind)
positional_output += embedded_words
return positional_output
def padding_mask(self, inputs):
pad_mask = tf.equal(inputs,0)
# [batch_size,sequence_length,sequence_length]
pad_mask = tf.tile(tf.expand_dims(pad_mask,axis=1),[1,self.sequence_length,1])
return pad_mask
def layer_normalize(self, inputs, epsilon = 1e-8):
# [batch_size,sequence_length,num_units]
inputs_shape = inputs.get_shape()
params_shape = inputs_shape[-1:] # num_units
# 沿轴-1求均值和方差(也就是沿轴num_units)
# mean/variance.shape = [batch_size,sequence_length]
mean, variance = tf.nn.moments(inputs, [-1], keep_dims=True) # LN
# mean, variance = tf.nn.moments(inputs,[-2,-1],keep_dims=True) # BN
beta= tf.Variable(tf.zeros(params_shape))
gamma = tf.Variable(tf.ones(params_shape))
normalized = (inputs - mean) / ( (variance + epsilon) ** (.5) )
# [batch_size,sequence_length,num_units]
outputs = gamma * normalized + beta
return outputs
def multihead_attention(self,attention_inputs):
# [batch_size,sequence_length, num_units]
Q = tf.keras.layers.Dense(self.num_units)(attention_inputs)
K = tf.keras.layers.Dense(self.num_units)(attention_inputs)
V = tf.keras.layers.Dense(self.num_units)(attention_inputs)
# 将Q/K/V分成多头
# Q_/K_/V_.shape = [batch_size*num_heads,sequence_length,num_units/num_heads]
Q_ = tf.concat(tf.split(Q, num_heads, axis=2), axis=0)
K_ = tf.concat(tf.split(K, num_heads, axis=2), axis=0)
V_ = tf.concat(tf.split(V, num_heads, axis=2), axis=0)
# 计算Q与K的相似度
# tf.transpose(K_,[0,2,1])是对矩阵K_转置
# similarity.shape = [batch_size*num_heads,sequence_length,sequence_length]
similarity = tf.matmul(Q_, tf.transpose(K_, [0, 2, 1]))
similarity = similarity / (K_.get_shape().as_list()[-1] ** 0.5)
pad_mask = self.padding_mask(self.input_x)
pad_mask = tf.tile(pad_mask,[self.num_heads,1,1])
paddings = tf.ones_like(similarity)*(-2**32+1)
similarity = tf.where(tf.equal(pad_mask,False),paddings,similarity)
similarity = tf.nn.softmax(similarity)
similarity = tf.nn.dropout(similarity,self.dropout_keep_prob)
# [batch_size*num_heads,sequence_length,sequence_length]
outputs = tf.matmul(similarity, V_)
outputs = tf.concat(tf.split(outputs, num_heads, axis=0), axis=2 )
return outputs
def feedforward(self,inputs):
params = {"inputs": inputs, "filters": ffn_dim, "kernel_size": 1,"activation": tf.nn.relu, "use_bias": True}
# 相当于 [batch_size*sequence_length,num_units]*[num_units,ffn_dim],在reshape成[batch_size,sequence_length,num_units]
# [batch_size,sequence_length,ffn_dim]
outputs = tf.layers.conv1d(**params)
params = {"inputs": outputs, "filters": num_units, "kernel_size": 1,"activation": None, "use_bias": True}
# [batch_size,sequence_length,num_units]
outputs = tf.layers.conv1d(**params)
return outputs
def __init__(self,
sequence_length,
num_classes,
vocab_size,
embedding_size,
num_units,
num_heads):
self.sequence_length = sequence_length
self.num_classes = num_classes
self.vocab_size = vocab_size
self.embedding_size = embedding_size
self.num_units = num_units
self.num_heads = num_heads
# 定义需要用户输入的placeholder
self.input_x = tf.placeholder(tf.int32, [None,sequence_length], name='input_x')
self.input_y = tf.placeholder(tf.float32, [None,num_classes], name='input_y')
self.dropout_keep_prob = tf.placeholder(tf.float32, name='dropout_keep_prob')
self.learning_rate = tf.placeholder(tf.float32, name='learning_rate') # 定义为placeholder是为了实现lr递减
input_embedding = self.embedding(self.input_x)
# [batch_size, sequence_length, num_units]
positional_output = self.positional_encoding(input_embedding)
# Dropout
positional_output = tf.nn.dropout(positional_output, self.dropout_keep_prob)
attention_output = self.multihead_attention(positional_output)
# Residual connection
attention_output += positional_output
# [batch_size, sequence_length, num_units]
outputs = self.layer_normalize(attention_output) # LN
# feedforward
feedforward_outputs = self.feedforward(outputs)
#Residual connection
feedforward_outputs += outputs
# LN
feedforward_outputs = self.layer_normalize(feedforward_outputs)
outputs = tf.reduce_mean(outputs ,axis=1)
self.scores = tf.keras.layers.Dense(self.num_classes)(outputs)
self.predictions = tf.argmax(self.scores, 1, name="predictions")
with tf.name_scope('loss'):
# 交叉熵loss
losses = tf.nn.softmax_cross_entropy_with_logits_v2(logits=self.scores, labels=self.input_y)
# L2正则化后的loss
self.loss = tf.reduce_mean(losses)
with tf.name_scope('accuracy'):
correct_predictions = tf.equal(self.predictions, tf.argmax(self.input_y, 1))
self.accuracy = tf.reduce_mean(tf.cast(correct_predictions, "float"), name="accuracy")
# 用于产生batch
def batch_iter(data, batch_size, num_epochs, shuffle=True):
data_size = len(data)
num_batches_per_epoch = data_size// batch_size # 每个epoch中包含的batch数量
for epoch in range(num_epochs):
# 每个epoch是否进行shuflle
if shuffle:
shuffle_indices = np.random.permutation(np.arange(data_size))
shuffled_data = data[shuffle_indices]
else:
shuffled_data = data
for batch_num in range(num_batches_per_epoch):
start_index = batch_num * batch_size
end_index = min((batch_num + 1) * batch_size, data_size)
yield shuffled_data[start_index:end_index]
训练模型
with tf.Graph().as_default():
session_conf = tf.ConfigProto(
allow_soft_placement=True, # 如果指定的设备不存在,允许tf自动分配设备
log_device_placement=False) # 不打印设备分配日志
sess = tf.Session(config=session_conf) # 使用session_conf对session进行配置
# 构建模型
nn = Transformer(sequence_length=x_train.shape[1],
num_classes=y_train.shape[1],
vocab_size=max_features,
embedding_size=embedding_size,
num_units=num_units,
num_heads=num_heads)
# 用于统计全局的step
global_step = tf.Variable(0, name="global_step", trainable=False)
optimizer = tf.train.AdamOptimizer(nn.learning_rate)
train_op = optimizer.minimize(nn.loss, global_step=global_step)
sess.run(tf.global_variables_initializer())
batches = batch_iter(np.hstack((x_train,y_train)), batch_size, num_epochs)
decay_speed = decay_coefficient*len(y_train)/batch_size
counter = 0 # 用于记录当前的batch数
for batch in batches:
learning_rate = min_learning_rate + (max_learning_rate - min_learning_rate) * math.exp(-counter/decay_speed)
counter += 1
x_batch,y_batch = batch[:,:-2],batch[:,-2:]
# 训练
feed_dict = {nn.input_x: x_batch,
nn.input_y: y_batch,
nn.dropout_keep_prob: dropout_keep_prob,
nn.learning_rate: learning_rate}
_, step, loss, accuracy= sess.run(
[train_op, global_step, nn.loss, nn.accuracy],
feed_dict)
current_step = tf.train.global_step(sess, global_step)
# Evaluate
if current_step % evaluate_every == 0:
print("\nEvaluation:")
loss_sum = 0
accuracy_sum = 0
step = None
batches_in_dev = len(y_dev) // batch_size
for batch in range(batches_in_dev):
start_index = batch * batch_size
end_index = (batch + 1) * batch_size
feed_dict = {
nn.input_x: x_dev[start_index:end_index],
nn.input_y: y_dev[start_index:end_index],
nn.dropout_keep_prob: 1.0
}
step, loss, accuracy = sess.run(
[global_step, nn.loss, nn.accuracy],feed_dict)
loss_sum += loss
accuracy_sum += accuracy
loss = loss_sum / batches_in_dev
accuracy = accuracy_sum / batches_in_dev
time_str = datetime.datetime.now().isoformat()
print("{}: step {}, loss {:g}, acc {:g}".format(time_str, step, loss, accuracy))
print("")
# predict test set
all_predictions = []
test_batches = batch_iter(x_test, batch_size, num_epochs=1, shuffle=False)
for batch in test_batches:
feed_dict = {
nn.input_x: batch,
nn.dropout_keep_prob: 1.0
}
predictions = sess.run([nn.predictions],feed_dict)[0]
all_predictions.extend(list(predictions))
Evaluation:
2019-04-24T11:26:46.465267: step 100, loss 0.687885, acc 0.536638
Evaluation:
2019-04-24T11:27:05.357059: step 200, loss 0.685882, acc 0.516298
Evaluation:
2019-04-24T11:27:24.331140: step 300, loss 0.690206, acc 0.522225
Evaluation:
2019-04-24T11:27:43.218558: step 400, loss 0.67215, acc 0.534887
Evaluation:
2019-04-24T11:28:02.218079: step 500, loss 0.655838, acc 0.56681
Evaluation:
2019-04-24T11:28:21.133057: step 600, loss 0.632425, acc 0.584456
Evaluation:
2019-04-24T11:28:40.129454: step 700, loss 0.683302, acc 0.543373
Evaluation:
2019-04-24T11:28:59.081713: step 800, loss 0.649721, acc 0.561288
Evaluation:
2019-04-24T11:29:18.060436: step 900, loss 0.600029, acc 0.602775
Evaluation:
2019-04-24T11:29:36.982586: step 1000, loss 0.758706, acc 0.553745
Evaluation:
2019-04-24T11:29:55.939290: step 1100, loss 0.479009, acc 0.782866
Evaluation:
2019-04-24T11:30:14.831542: step 1200, loss 0.55743, acc 0.667161
Evaluation:
2019-04-24T11:30:33.761636: step 1300, loss 0.508881, acc 0.726158
Evaluation:
2019-04-24T11:30:52.676481: step 1400, loss 0.492081, acc 0.739224
Evaluation:
2019-04-24T11:31:11.671053: step 1500, loss 0.413467, acc 0.837015
Evaluation:
2019-04-24T11:31:30.601062: step 1600, loss 0.400088, acc 0.841191
Evaluation:
2019-04-24T11:31:49.486295: step 1700, loss 0.395875, acc 0.829741
Evaluation:
2019-04-24T11:32:08.436114: step 1800, loss 0.379996, acc 0.848869
Evaluation:
2019-04-24T11:32:27.364562: step 1900, loss 0.398805, acc 0.832705
Evaluation:
2019-04-24T11:32:46.313906: step 2000, loss 0.384953, acc 0.841325
参考
[1].The Illustrated Transformer
[2].Transformer的PyTorch实现
[3].Attention is all you need