【机器学习】LDA线性判别分析原理及实例
1、LDA的基本原理
LDA线性判别分析也是一种经典的降维方法,LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的。这点和PCA不同。PCA是不考虑样本类别输出的无监督降维技术。LDA的思想可以用一句话概括,就是“*投影后类内方差最小,类间方差最大*”。什么意思呢? 我们要将数据在低维度上进行投影,投影后希望每一种类别数据的投影点尽可能的接近,而不同类别的数据的类别中心之间的距离尽可能的大。
可能还是有点抽象,我们先看看最简单的情况。假设我们有两类数据分别为红色和蓝色,如下图所示,这些数据特征是二维的,我们希望将这些数据投影到一维的一条直线,让每一种类别数据的投影点尽可能的接近,而红色和蓝色数据中心之间的距离尽可能的大。
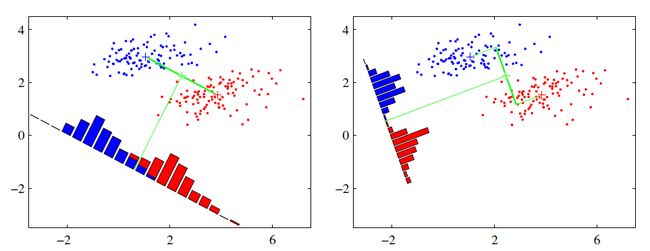
上图中提供了两种投影方式,哪一种能更好的满足我们的标准呢?从直观上可以看出,右图要比左图的投影效果好,因为右图的黑色数据和蓝色数据各个较为集中,且类别之间的距离明显。左图则在边界处数据混杂。以上就是LDA的主要思想了,当然在实际应用中,我们的数据是多个类别的,我们的原始数据一般也是超过二维的,投影后的也一般不是直线,而是一个低维的超平面。
2、LDA算法流程
现在我们对LDA降维的流程做一个总结。
输入:数据集D={(x1,y1),(x2,y2),...,((xm,ym))},其中任意样本xi为n维向量,yi∈{C1,C2,...,Ck},降维到的维度d。
输出:降维后的样本集$D′$
1) 计算类内散度矩阵Sw
2) 计算类间散度矩阵Sb
3) 计算矩阵Sw^−1*Sb
4)计算Sw^−1*Sb的最大的d个特征值和对应的d个特征向量(w1,w2,...wd),得到投影矩阵W
5) 对样本集中的每一个样本特征xi,转化为新的样本zi=WT*xi
6) 得到输出样本集
以上就是使用LDA进行降维的算法流程。实际上LDA除了可以用于降维以外,还可以用于分类。一个常见的LDA分类基本思想是假设各个类别的样本数据符合高斯分布,这样利用LDA进行投影后,可以利用极大似然估计计算各个类别投影数据的均值和方差,进而得到该类别高斯分布的概率密度函数。当一个新的样本到来后,我们可以将它投影,然后将投影后的样本特征分别带入各个类别的高斯分布概率密度函数,计算它属于这个类别的概率,最大的概率对应的类别即为预测类别。
3、LDA与PCA比较
LDA用于降维,和PCA有很多相同,也有很多不同的地方,因此值得好好的比较一下两者的降维异同点。
首先我们看看相同点:
1)两者均可以对数据进行降维。
2)两者在降维时均使用了矩阵特征分解的思想。
3)两者都假设数据符合高斯分布【正态分布】。
我们接着看看不同点:
1)LDA是有监督的降维方法,而PCA是无监督的降维方法
2)LDA降维最多降到类别数**k-1**的维数,而PCA没有这个限制。
3)LDA除了可以用于降维,还可以用于分类。
4)LDA选择分类性能最好的投影方向,而PCA选择样本点投影具有最大方差的方向。
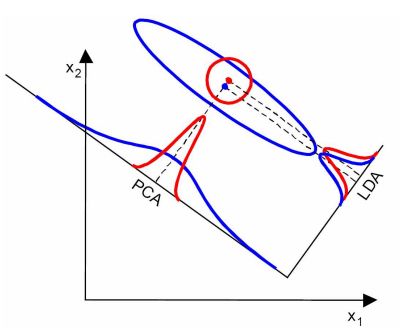
这点可以从下图形象的看出,在某些数据分布下LDA比PCA降维较优。

当然,某些某些数据分布下PCA比LDA降维较优,如下图所示:
4、 LDA算法小结
LDA算法既可以用来降维,又可以用来分类,但是目前来说,主要还是用于降维。在我们进行图像识别图像识别相关的数据分析时,LDA是一个有力的工具。下面总结下LDA算法的优缺点。
LDA算法的主要优点有:
1)在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识。
2)LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优。
LDA算法的主要缺点有:
1)LDA不适合对非高斯分布样本进行降维,PCA也有这个问题。
2)LDA降维最多降到类别数k-1的维数,如果我们降维的维度大于k-1,则不能使用LDA。当然目前有一些LDA的进化版算法可以绕过这个问题。
3)LDA在样本分类信息依赖方差而不是均值的时候,降维效果不好。
4)LDA可能过度拟合数据
5、LinearDiscriminantAnalysis 主要参数
1)solver : 即求LDA超平面特征矩阵使用的方法。可以选择的方法有奇异值分解”svd”,最小二乘”lsqr”和特征分解”eigen”。一般来说特征数非常多的时候推荐使用svd,而特征数不多的时候推荐使用eigen。主要注意的是,如果使用svd,则不能指定正则化参数shrinkage进行正则化。默认值是svd
2)shrinkage:正则化参数,可以增强LDA分类的泛化能力。如果仅仅只是为了降维,则一般可以忽略这个参数。默认是None,即不进行正则化。可以选择”auto”,让算法自己决定是否正则化。当然我们也可以选择不同的[0,1]之间的值进行交叉验证调参。注意shrinkage只在solver为最小二乘”lsqr”和特征分解”eigen”时有效。
3)priors :类别权重,可以在做分类模型时指定不同类别的权重,进而影响分类模型建立。降维时一般不需要关注这个参数。
4)n_components:即我们进行LDA降维时降到的维数。在降维时需要输入这个参数。注意只能为[1,类别数-1)范围之间的整数。如果我们不是用于降维,则这个值可以用默认的None。
从上面的描述可以看出,如果我们只是为了降维,则只需要输入n_components,注意这个值必须小于“类别数-1”。PCA没有这个限制。
6、实例
# -*- coding: utf-8 -*-
"""
Created on Fri Dec 1 10:49:37 2017
LDA_learning
@author: BruceWong
"""
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn import datasets
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import numpy as np
def main():
iris = datasets.load_iris() #典型分类数据模型
#这里我们数据统一用pandas处理
data = pd.DataFrame(iris.data, columns=iris.feature_names)
data['class'] = iris.target
#这里只取两类
# data = data[data['class']!=2]
#为了可视化方便,这里取两个属性为例
X = data[data.columns.drop('class')]
Y = data['class']
#划分数据集
X_train, X_test, Y_train, Y_test =train_test_split(X, Y)
lda = LinearDiscriminantAnalysis(n_components=2)
lda.fit(X_train, Y_train)
#显示训练结果
print(lda.means_) #中心点
print(lda.score(X_test, Y_test)) #score是指分类的正确率
print(lda.scalings_)#score是指分类的正确率
X_2d = lda.transform(X) #现在已经降到二维X_2d=np.dot(X-lda.xbar_,lda.scalings_)
#对于二维数据,我们做个可视化
#区域划分
lda.fit(X_2d,Y)
h = 0.02
x_min, x_max = X_2d[:, 0].min() - 1, X_2d[:, 0].max() + 1
y_min, y_max = X_2d[:, 1].min() - 1, X_2d[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = lda.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap=plt.cm.Paired)
#做出原来的散点图
class1_x = X_2d[Y==0,0]
class1_y = X_2d[Y==0,1]
l1 = plt.scatter(class1_x,class1_y,color='b',label=iris.target_names[0])
class1_x = X_2d[Y==1,0]
class1_y = X_2d[Y==1,1]
l2 = plt.scatter(class1_x,class1_y,color='y',label=iris.target_names[1])
class1_x = X_2d[Y==2,0]
class1_y = X_2d[Y==2,1]
l3 = plt.scatter(class1_x,class1_y,color='r',label=iris.target_names[2])
plt.legend(handles = [l1, l2, l3], loc = 'best')
plt.grid(True)
plt.show()
if __name__ == '__main__':
main()