HBase Replication的源码分析
在HRegionServer中有两个量和replication相关,如下图所示:
![]()
在ReplicationSourceService中只有一个方法getWALActionsListener,该方法返回WALActionsListener。ReplicationSinkService同样也是一个接口类,它有一个方法replicateLogEntries。在HRegionServer的如下代码段中会启动replicationservice。
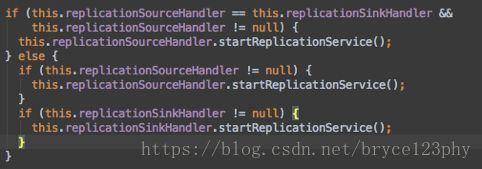
startReplicationService中做了三件事,分别是调用ReplicationSourceManger的init方法,初始化replicationSink,初始化调度线程池scheduleThreadPool;
在ReplicationSourceManager的init方法中遍历replicationPeers中的peerid。并以该id为参数,调用addSource方法。
addSource中做了这么几件事,首先,针对每个peerid构造了一个ReplicationSource对象,把所有的wal log按照不同的peer id归类,并保存在ReplicationSourceManager的队列replicationQueues中,以表示不同目标端集群当前replicate的wal log。每个ReplicationSource中保存了待同步到同一个slave集群的hlog,这些hlog根据不同的prefix name组成不同的队列,每个队列都有一个ReplicationSourceWorkerThread负责同步该队列中的hlog。
下面说回ReplicationSource,ReplicationSource是个守护进程,这里初始化的时候并不是通过构造函数,而是通过getReplicationSource函数在这个方法里先获得了一个ReplicationSource的接口,接着调用init初始化该接口,此外,getReplicationSource还有一个重要的作用是它实例化了replicationEndpoint(HBaseInterClusterReplicationEndpoint)。回到addSource这个方法,他返回前调用了ReplicationSource的startup方法,startup是个挺有意思的方法,代码如下:
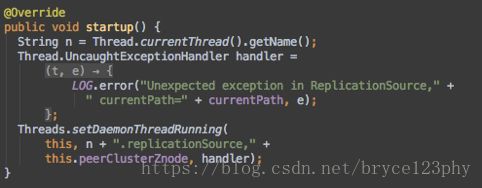
ReplicationSource是个守护线程,每个slave集群都有一个自己的ReplicationSource守护线程。我们从它的run方法入手分析ReplicationSource这个守护线程的处理逻辑。run方法中主要包括了如下几个步骤:
1、获取一个replicationEndpoint并启动它:Service.State state = replicationEndpoint.start().get()
2、构造walEntryFilter:this.walEntryFilter = new ChainWALEntryFilter(filters);
3、前面讲过ReplicationSource将待同步的hlog根据prefix name划分到不同的队列中,每个队列分配了一个ReplicationSourceWorkThread负责同步该队列的hlog,这里的第三步就是初始化并启动一个ReplicationSourceWorkThread;
ReplicationSourceWorkThread是读取hlog文件并将之解析成entry的工作线程,run中的关键步骤列在下面:
1、获取log path;
2、调用openReader打开当前path的log reader;
3、从reader中依次读取WAL.Entry并放入一个List中,方法调用如下:
readAllEntriesToReplicateOrNextFile(currentWALisBingWrittenTo, entries)
4、最后调用shipEdits将entries发送到远端集群;
发送WALEntry到从集群的逻辑在方法shipEdits中完成,ship方法首先进行一些限流逻辑的处理,接着将传入的entries参数包装进replicateContext中并发送到从集群,这部分的主要代码如下所示:

replicate有两个类来实现,分别是HBaseInterClusterReplicationEndpoint和RegionReplicaReplicationEndpoint,后者是region多副本逻辑的实现。本文的背景是分析不同集群间的数据同步,因此进入HBaseInterClusterReplicationEndpoint的replicate方法的实现,该方法首先从参数replicateContext中获得List
Replicator的call方法就是Entry对象序列化之后递交ReplicationSinkService发送到远端集群:
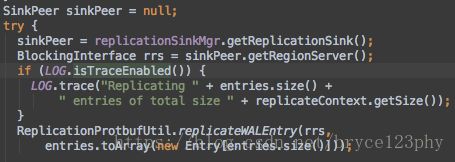
如果目标sink集群包含多个regionserver时,getReplicationSink从目标集群依ratio随机选取regionserver作为目标regionserver;
以上这些就是大概的replication时,wal跨集群传递的一些细节实现。接下来回过头详细解释上文留下的一个小辫子,就是围绕ReplicationSource的openReader方法的实现,分析这个调用的目的是理清wal的读逻辑是什么样的。
ReplicationSource的openReader以currentPath为参数,openReader在ReplicationWALReaderManager中实现,ReplicationWALReaderManager是负责wal log读取的类。
ReplicationWALReaderManager的openReader通过WALFactory.createReader返回指定文件的reader。创建文件reader的关键代码语句如下面所列出的:
stream = fs.open(path);
byte[] magic = new byte[ProtobufLogReader.PB_WAL_MAGIC.length]
boolean isPbWal = (stream.read(magic) == magic.length)
&& Arrays.equals(magic, ProtobufLogReader.PB_WAL_MAGIC);
DefaultWALProvider.Reader reader =
isPbWal ? new ProtobufLogReader() : new SequenceFileLogReader();
reader.init(fs, path, conf, stream);
return reader;可见Reader是在这里构建的,我们以最常见的lrClass属于ProtobufLogReader.class为例来解释,首先初始化一个数据输入流FSDataInputStream,通过这个流打开文件,根据isPbWal选择new不同的Reader实例,最后调用reader的init方法完成初始化工作。这里的Reader大多数是DefaultWALProvider.Reader类型的。
Reader创建已经分析完毕,那读实现是什么样的?
读的动作主要在readAllEntriesToReplicateOrNextFile中,该方法接收一个List
1、this.repLogReader.seek();
2、WAL.Entry entry = this.repLogReader.readNextAndSetPosition();
3、进入循环
while(entry != null) {
//过滤掉已经消费掉的log entry
if (replicationEndpoint.canReplicateToSameCluster()
|| !entry.getKey().getClusterIds().contains(peerClusterId)) {
entry = walEntryFilter.filter(entry); //过滤掉不需要的entry
entries.add(entry);
}
try {
entry = this.repLogReader.readNextAndSetPosition();
}
}
4、各种metrics处理;WALEntryFilter的作用是在把wal entries发送到slave集群前过滤掉某些并不需要发送的entry,它有很多个实现类,所有的类都实现了filter方法,这些不同的WALEntryFilter可以通过ChainWALEntryFilter构成一条责任链。这些读出的wal entries流经责任链,最终筛选出需要replicate的walEntry,典型的责任链模式应用。
前面分析了Replication是发送端的处理逻辑,下面来分析接收端的处理逻辑。
接收端的入口代码在RSRpcServices,这个类是RegionServer的RPC请求处理类,其中用于处理源端集群replication的函数是replicateWALEntry,该方法调用HRegionServer上的replicationSinkHandler来重演源端传送过来的entries。Handler调用的services定义是ReplicationSink中的replicateEntries方法,replicateEntries的主要逻辑包括如下两个步骤:
1、遍历entries的cell,并根据不同的action,标记为不同的mutation,如delete或者put;
2、调用hbase内部的batch接口,将数据批量写入;
Wal log在被replicate复制到目的端集群之前是不会被删除的,即使对应的peer是disable,其下的wal log也不会被删除;
对wal log的删除清理由master节点的定时清理任务来完成(cleancore),筛查的依据是将zookeeper上的所有hlog同步下来并存到本地的queue中,如果某个wal log不再上述的queue中出现,则这个wal log就是可以被删除的log。