数据提取--JSON
基础知识
数据提取
- 什么是数据提取
- 简单来说,数据提取就是从响应中获取我们需要的数据的过程
数据分类
- 结构化数据处理方式
- 文本、电话号码、邮箱地址:正则表达
- html:正则表达式、XPath
- 非结构化数据
- JSON 文件:JSON Path、转化成Python类型进行操作(json类)
- XML 文件:转化成Python类型(xmltodict)、XPath、CSS选择器、正则表达式
数据提取之JSON
- 由于把json数据转化为python内建数据类型很简单,所以爬虫中,如果我们能够找到返回json数据的URL,就会尽量使用这种URL
- JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写,同时也方便了机器进行解析和生成,适用于进行数据交互的场景。
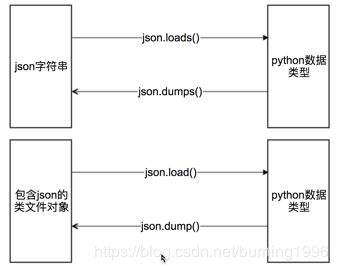
python数据类型和Json字符串之间的转换
- 什么是类文件对象
- 具有read()和write()方法的对象就是类文件对象,例如f = open(“a.txt”, “r”)就是类文件对象
json.loads()
- 把Json格式字符串解码转换成Python对象 从json到python的类型转化对照如下:

代码示例
import json
strList = '[1, 2, 3, 4]'
strDict = '{"city": "北京", "name": "大猫"}'
json.loads(strList)
# [1, 2, 3, 4]
json.loads(strDict) # json数据自动按Unicode存储
# {u'city': u'\u5317\u4eac', u'name': u'\u5927\u732b'}
json.dumps()
- 实现python类型转化为json字符串,返回一个str对象 把一个Python对象编码转换成Json字符串
- 从python原始类型向json类型的转化对照如下:

代码示例
import json
import chardet
listStr = [1, 2, 3, 4]
tupleStr = (1, 2, 3, 4)
dictStr = {"city": "北京", "name": "大猫"}
json.dumps(listStr)
# '[1, 2, 3, 4]'
json.dumps(tupleStr)
# '[1, 2, 3, 4]'
# 注意:json.dumps() 序列化时默认使用的ascii编码,所以中文无法输出
# 添加参数 ensure_ascii=False 禁用ascii编码,按utf-8编码
# chardet.detect()返回字典, 其中confidence是检测精确度
json.dumps(dictStr)
# '{"city": "\\u5317\\u4eac", "name": "\\u5927\\u5218"}'
chardet.detect(json.dumps(dictStr))
# {'confidence': 1.0, 'encoding': 'ascii'}
print json.dumps(dictStr, ensure_ascii=False)
# {"city": "北京", "name": "大刘"}
chardet.detect(json.dumps(dictStr, ensure_ascii=False))
# {'confidence': 0.99, 'encoding': 'utf-8'}
chardet是一个非常优秀的编码识别模块,可通过pip安装
json.dump()
- 将Python内置类型序列化为json对象后写入文件
代码示例
import json
listStr = [{"city": "北京"}, {"name": "大刘"}]
json.dump(listStr, open("listStr.json","w"), ensure_ascii=False)
dictStr = {"city": "北京", "name": "大刘"}
json.dump(dictStr, open("dictStr.json","w"), ensure_ascii=False)
json.load()
- 读取文件中json形式的字符串元素 转化成python类型
代码示例
import json
strList = json.load(open("listStr.json"))
print strList
# [{u'city': u'\u5317\u4eac'}, {u'name': u'\u5927\u5218'}]
strDict = json.load(open("dictStr.json"))
print strDict
# {u'city': u'\u5317\u4eac', u'name': u'\u5927\u5218'}
豆瓣电视剧爬虫案例
# coding=utf-8
import requests
import json
class DoubanSpider:
def __init__(self):
self.url_temp_list = [
{
"url_temp": "https://m.douban.com/rexxar/api/v2/subject_collection/tv_american/items?start={}&count=18"
"&loc_id=108288",
"country": "US"
},
{
"url_temp": "https://m.douban.com/rexxar/api/v2/subject_collection/tv_korean/items?start={}&count=18"
"&loc_id=108288",
"country": "UK"
},
{
"url_temp": "https://m.douban.com/rexxar/api/v2/subject_collection/tv_domestic/items?start={}&count=18"
"&loc_id=108288",
"country": "China"
}
]
self.headers = {"User-Agent": "Mozilla/5.0 (Linux; Android 8.0.0; Nexus 6P Build/OPP3.170518.006) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Mobile "
"Safari/537.36", "Referer": "https://m.douban.com/tv/american"}
def parse_url(self, url):
print(url)
response = requests.get(url, headers=self.headers)
return response.content.decode()
# 3.提取数据
def get_content_list(self, json_str):
dict_ret = json.loads(json_str)
content_list = dict_ret["subject_collection_items"]
total = dict_ret["total"]
return content_list, total
# 4.保存数据
def save_content_list(self, content_list, country):
with open("douban.txt", "a", encoding="utf-8") as f:
for content in content_list:
content["country"] = country
f.write(json.dumps(content, ensure_ascii=False))
f.write("\n")
# 实现主要逻辑
def run(self):
for url_temp in self.url_temp_list:
# 1.start_utl
number = 0
total = 100
while number < total + 18:
url = url_temp["url_temp"].format(number)
# 2.发送请求,获取响应
json_str = self.parse_url(url)
# 3.提取数据
content_list, total = self.get_content_list(json_str)
# 4.保存数据
self.save_content_list(content_list, url_temp["country"])
# 5.构造下一页的URL地址 进入循环
number += 18
if __name__ == '__main__':
douban_spider = DoubanSpider()
douban_spider.run()