PageRank 算法及实例分析
本文一部分是针对图的PageRank 的实现,以及具体数据集的分析过程的记录。
另一部分是BFS的实现,并记录每一层的节点数。
数据集下载地址 soc-Slashdot0811 、 roadNet-CA 、 soc-LiveJournal1
1. java 实现代码
Main.java
import java.util.List;
public class Main{
public static void main(String args[]){
long start = System.currentTimeMillis();
List> graph = PageRank.file_to_matrix();
System.out.println("开始PageRank算法...");
PageRank.pagerank(graph);
System.out.println("PageRank算法结束,总共用时:" + (System.currentTimeMillis() - start) + "ms");
start = System.currentTimeMillis();
System.out.println();
System.out.println("开始进行BFS遍历...");
System.out.println();
BFS.bfs(graph);
System.out.println();
System.out.println("BFS结束,总共用时:" + (System.currentTimeMillis() - start) + "ms");
}
} PageRank.java
import java.io.*;
import java.sql.Time;
import java.util.*;
public class PageRank {
// public static final int N = 77360;
// public static final int N = 1971281;
public static final int N = 4847571;
// public static final int N = 5;
private static final double AFA = 0.85;
private static final double DELTA = 1;
private static final double MAX_TIMES = 100;
// private static final String FILE = "/home/jkbao/Slashdot0811.txt";
// private static final String OUT = "/home/jkbao/result.txt";
// private static final String FILE = "/home/jkbao/roadNet-CA.txt";
// private static final String OUT = "/home/jkbao/result_roadNet.txt";
private static final String FILE = "/home/jkbao/soc-LiveJournal1.txt";
private static final String OUT = "/home/jkbao/result_LiveJournall.txt";
public static void pagerank(List> graph){
// List> graph = new ArrayList<>();
// List list0 = Arrays.asList(1,2,3);
// List list1 = Arrays.asList(3,4);
// List list2 = Arrays.asList(4);
// List list3 = Arrays.asList(4);
// List list4 = Arrays.asList(0);
// graph.add(list0);
// graph.add(list1);
// graph.add(list2);
// graph.add(list3);
// graph.add(list4);
double [] Prnew = new double[N];
for (int i = 0; i < N; i++) {
Prnew[i] = 1.0/N;
}
double [] Pr;
//迭代至|Pn+1−Pn|<ϵ
long start = System.currentTimeMillis();
long now = 0;
for (int i = 1; i < MAX_TIMES; i++) {
//保留迭代前的Pr
Pr = Prnew;
//迭代后
Prnew = get_Prnew(graph,Pr);
double delta = get_DELTA(Prnew,Pr);
now = System.currentTimeMillis() - start;
System.out.println("第" + i + "次迭代完成,DELTA = " + delta + ", 用时 " + now + "ms");
if(delta < DELTA)
break;
}
//打印前十个pr节点
System.out.println();
System.out.println("开始计算前十节点...");
System.out.println();
double [][] big = getBiggestPr(Prnew);
for (int j = 0; j < 10; j++) {
System.out.println("第" + (j+1) + "大节点, node: " + (int)big[j][0] + " pr: " + big[j][1]);
}
//写文件
// BufferedWriter bw = null;
// try {
// bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(OUT)));
// double sum = 0;
// for (int j = 0; j < N; j++) {
//// System.out.println(Prnew[j]);
// sum+=Prnew[j];
// bw.write(String.valueOf(Prnew[j]));
// bw.newLine();
// }
// System.out.println(sum);
//
// }catch (Exception e){
// e.printStackTrace();
// }
}
public static double [][] getBiggestPr(double [] Pr){
double [][] biggestPr = new double[10][2];
for (int i = 0; i < N; i++) {
if (Pr[i] > biggestPr[9][1]){
biggestPr[9][0] = i;
biggestPr[9][1] = Pr[i];
for (int j = 8; j >= 0; j--) {
if (biggestPr[j+1][1] > biggestPr[j][1]){
//交换
biggestPr[j+1][0] = biggestPr[j+1][0] + biggestPr[j][0];
biggestPr[j][0] = biggestPr[j+1][0] - biggestPr[j][0];
biggestPr[j+1][0] = biggestPr[j+1][0] - biggestPr[j][0];
biggestPr[j+1][1] = biggestPr[j+1][1] + biggestPr[j][1];
biggestPr[j][1] = biggestPr[j+1][1] - biggestPr[j][1];
biggestPr[j+1][1] = biggestPr[j+1][1] - biggestPr[j][1];
}else{
break;
}
}
}
}
return biggestPr;
}
//计算|Pn+1−Pn|
public static double get_DELTA(double[] Prnew,double [] Pr){
double temp = 0;
for (int i = 0; i < N; i++) {
temp += (Prnew[i] - Pr[i])*(Prnew[i] - Pr[i]);
}
return Math.sqrt(temp);
}
//一次迭代过程
public static double [] get_Prnew(List> list,double [] Pr){
double [] Prnew = new double[N];
List _list;
int _list_size;
for (int i = 0; i < N; i++) {
if(i%100000 == 0)
System.out.println("pr值更新到:" + i);
for (int k = 0; k < N; k++) {
_list = list.get(k);
if (_list.size() == 0){
Prnew[i] += Pr[k] * (AFA * (1.0 / N) + (1 - AFA) / N);
break;
}
_list_size = _list.size();
int has = 0;
for (int j = 0; j < _list_size; j++) {
if (_list.get(j) == i) {
Prnew[i] += Pr[k] * (AFA * (1.0 / _list_size) + (1 - AFA) / N);
has = 1;
break;
}
}
if (has == 0)
Prnew[i] += Pr[k] * ((1 - AFA) / N);
}
}
return Prnew;
}
//读取图,处理后得到矩阵
public static List> file_to_matrix(){
List> graph = new ArrayList<>(N);
for (int i = 0; i < N; i++) {
graph.add(new ArrayList<>());
}
BufferedReader br = null;
try {
br = new BufferedReader(new InputStreamReader(new FileInputStream(FILE)),65536);
int delete4 = 0;
while(br.readLine() != null && delete4 < 3){
delete4++;
}
String line;
String []str;
// int max = 0;
int num = 0;
long start = System.currentTimeMillis();
long now = 0;
while((line = br.readLine()) != null){
num++;
if(num%1000000 == 0){
now = System.currentTimeMillis() - start;
System.out.println("已读取 " + num + "行! 用时 " + now + "ms");
}
str = line.split("\t");
// max = Math.max(max,Integer.parseInt(str[1]));
graph.get(Integer.parseInt(str[0])).add(Integer.parseInt(str[1]));
}
System.out.println("文件读取结束,共 " + num + "行,开始迭代!");
System.out.println();
// System.out.println(max);
}catch (Exception e){
e.printStackTrace();
}finally {
try {
if (br != null)
br.close();
}catch (IOException e){
br = null;
e.printStackTrace();
}finally {
br = null;
}
}
return graph;
}
} BFS.java
广度优先遍历,记录每一层的节点数
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
public class BFS {
public static void main(String args[]){
List> graph = PageRank.file_to_matrix();
System.out.println();
System.out.println("BFS 第一层:");
bfs(graph);
}
public static void bfs(List> graph){
int flag[] = new int[PageRank.N];
// System.out.println(flag[0]);
Queue queue = new LinkedList<>();
Queue tempQueue = new LinkedList<>();
List layer_Nodes = new ArrayList<>();
queue.offer(0);
flag[0] = 1;
layer_Nodes.add(1);
//System.out.print(0 + " ");
int node;
List node_li;
int sum = 0;
int layer_now = 1;
while(!queue.isEmpty()){
node = queue.poll();
sum++;
if(sum%100000 == 0)
System.out.println("已遍历节点数: " + sum);
node_li = graph.get(node);
for (int i = 0; i < node_li.size(); i++) {
if (flag[node_li.get(i)] == 0){
tempQueue.offer(node_li.get(i));
flag[node_li.get(i)] = 1;
}
}
if (queue.isEmpty() && !tempQueue.isEmpty()){
if (layer_Nodes.size() > layer_now)
layer_Nodes.set(layer_now,layer_Nodes.get(layer_now) + tempQueue.size());
else
layer_Nodes.add(tempQueue.size());
queue = tempQueue;
tempQueue = new LinkedList<>();
layer_now++;
}
if (queue.isEmpty() && tempQueue.isEmpty()){
for (int i = 0; i < PageRank.N; i++) {
if (flag[i] == 0){
queue.offer(i);
flag[i] = 1;
layer_Nodes.set(0,layer_Nodes.get(0) + 1);
layer_now = 1;
//System.out.print(i + " ");
break;
}
}
}
}
System.out.println();
System.out.println("总遍历节点数: " + sum);
int check = 0;
for (int i = 0; i < layer_Nodes.size(); i++) {
System.out.println("第" + (i+1) + "层节点数: " + layer_Nodes.get(i));
check+=layer_Nodes.get(i);
}
//System.out.println(check);
}
} 2. 机器配置
主板:Intel HM70
Cpu:Intel 赛扬双核 B830
内存:4G
3. 实验中遇到的问题及解决方式
1. 图的存储方式问题
一开始使用邻接矩阵的方式存储图,第一个数据集就跑不过,jvm堆内存溢出,想了想问题出现在内存上,简单分析一下,第一个数据集7万多个节点,转化成矩阵就是70000 * 70000,double类型占用8个字节,矩阵存储需要的内存就是70000 * 70000 * 8个字节,大约40G,明显是不现实的。想了想发现矩阵很稀疏,所以改用邻接表存储,并且改为存储int类型数据,只在计算过程中再对图进行处理。
2. Jvm堆内存溢出问题
在改变存储方式之后对于前两个数据集可以跑过,但是soc-LiveJournal1.txt跑不过,分析得知内存不够,然后调jvm参数,堆内存上限设置为3G(电脑内存一共就4G),虽然机器变得很卡但最终还是跑过了。
3. BFS记录每一层节点数时复杂度不够优的问题
一开始实现BFS分层节点数记录时,对于非连通节点的处理时部分代码复杂度为O(n²),结果导致遍历到第4400000个节点附近,遍历速度急剧下降。后来发现是找根节点那部分代码复杂度太大,每次都可能要从头遍历几百万个节点,后将算法优化成上面那样,速度就极快了。
4. 实验结果与分析
相关声明:对于0出链的节点,处理方式为默认对所有节点都有出链。
数据集中的节点数目认为是最大节点号,对于既无出链又无入链的节点,认为它处于第一层。
这里用最大的那个数据集进行分析(只迭代一次):
数据集:soc-LiveJournal1.txt
已读取 1000000行! 用时 1577ms
已读取 10000000行! 用时 18901ms
已读取 20000000行! 用时 35951ms
已读取 30000000行! 用时 57776ms
已读取 40000000行! 用时 76494ms
已读取 50000000行! 用时 96713ms
已读取 60000000行! 用时 130695ms
已读取 68000000行! 用时 167051ms
文件读取结束,共 68993773行,开始迭代!
开始PageRank算法...
第1次迭代完成,DELTA = 4.541775462128287E-4, 用时 240438ms
开始计算前十节点...
第1大节点, node: 0 pr: 1.032699925450267E-6
第2大节点, node: 95 pr: 2.8993879389509924E-7
第3大节点, node: 4 pr: 1.1840549493809759E-7
第4大节点, node: 58 pr: 1.0603261637036512E-7
第5大节点, node: 57 pr: 7.16700270292102E-8
第6大节点, node: 12 pr: 6.907658456699886E-8
第7大节点, node: 38 pr: 6.733933106100371E-8
第8大节点, node: 150 pr: 6.573782802059104E-8
第9大节点, node: 59 pr: 6.332023896500434E-8
第10大节点, node: 12519 pr: 5.844952926088428E-8
PageRank算法结束,总共用时:415479ms
开始进行BFS遍历...
总遍历节点数: 4847571
第1层节点数: 397380
第2层节点数: 42274
第3层节点数: 8577
第4层节点数: 102305
第5层节点数: 1175114
第6层节点数: 2166755
第7层节点数: 811143
第8层节点数: 122072
第9层节点数: 17878
第10层节点数: 3177
第11层节点数: 684
第12层节点数: 165
第13层节点数: 28
第14层节点数: 15
第15层节点数: 4
BFS结束,总共用时:4736ms
Process finished with exitcode 0
因为电脑配置低,导致读取文件花费了大量时间,后来在我的台式机上跑,图的存储过程耗时只用了17秒,这里文件读取用的BufferedReader,默认缓存8096,后增加到65536,达到些许优化效果。
第一层节点数397380个是因为对于孤立节点,认为它们在第一层。BFS复杂度O(n),四百多万节点几秒钟遍历完。
第二个数据集roadNet-CA.txt,层数有五百多层,实验结果不再展示。
5. CPU与内存使用情况分析
根据sar记录的cpu使用情况数据绘制如下表格,蓝色曲线是cpu使用率,红色曲线是iowait。
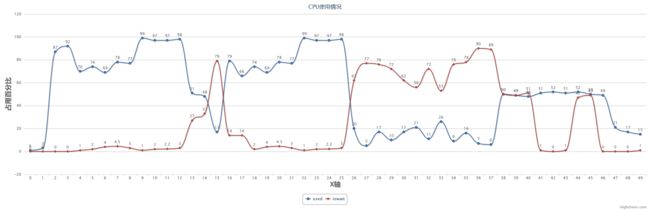
针对表中数据相应变化情况的简单分析:
第一个阶段:内存足够,cpu使用率几乎100%,结合top命令实时监控的进程占用cpu及内存情况分析,如下图:
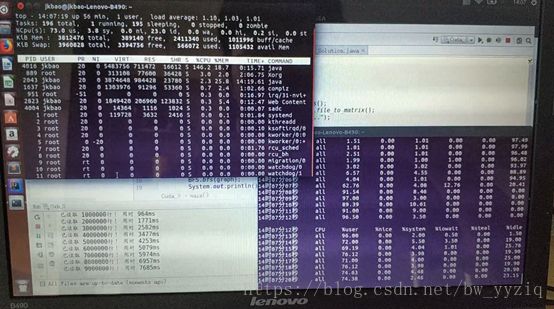
此时内存才使用了大概700M,java进程占用了70%的CPU资源。
第二个阶段:内存不足,开始换入换出虚拟内存,此时的cpu会发生iowait,如图:
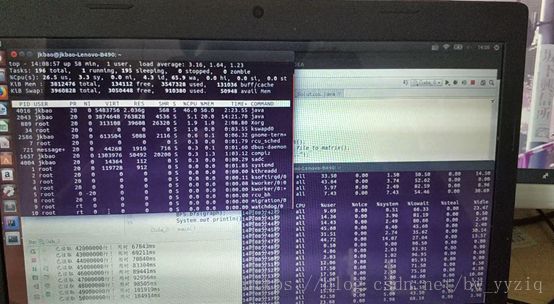
此时内存已经使用了2G多(JVM堆内存分配最大只有3G),java只占用了不多的CPU资源,iowait情况严重。
第三个阶段:图存储完毕,进行迭代等过程,如图:
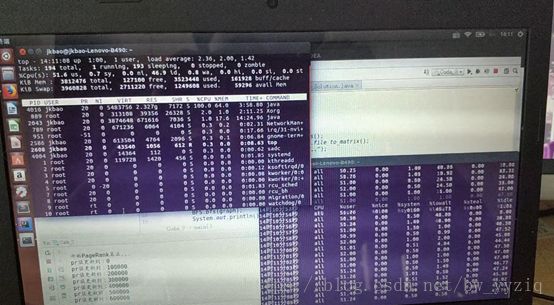
此时还是需要换入换出内存的,但大部分时间都在处理迭代等操作,此时内存占用2.3G左右,双核CPU有一个被完全占用,CPU使用率稳定在50%左右。时不时的会发生iowait。