Adversarial Discriminative Domain Adaption 阅读笔记
文章发表于 CVPR 2017
文章利用GAN网络的思想用于cross-domain识别
文章首先提到
1 先前的生成网络不适用于大的domain shift
2 先前的辨别网络施加固定的权重,没有利用GAN的loss
1 introduction
一般而言,对于这种跨领域的任务,最简单的思想就是先训练source domain, 然后利用fine-tuning调整参数。但是,如果source domain没有足够的label,将会失效。最近的domain adaptation方案:将两个域的feature投影到统一的特征空间。通过最小化一定的约束学习映射。这些方法总结为一些选择:

1 是否使用生成器generator
2 使用什么loss function
3 是否权值共享
4 。。。
生成步骤不是必须,因为目标是分类识别,用非对称的映射更好,因为不同的domain有不同的特性(因此不提倡全部权值共享)。
2 related work
一类方法是:通过一个损失函数,最小化source domain和target domain的差别,如MMD, DCC。另一类方法是选择对抗性的loss:使用一个domain二分类器(简单的全连接神经网络)将获取的特征进行分类,然后定义一个domain confusing loss,通过优化特征提取让该domain二分类器分辨不出他们来。
3 生成对抗adaptation
先学习一个source域的映射Ms,一个source域的分类器Cs来分类。由于source domain有标签,我们可以轻易地学习到这俩。现在的问题是如何把Ms和Cs迁移到target domain。首先一个假设是,分类器是共享的,也就是说Ct=Cs,相当于在映射后的子空间内,源域和目标域有着相同的分布。因此,只需要学习Mt, 为了获得Mt,需要定义一个domain分类器D,借鉴GAN网络的思想,优化D的目标函数为:

这和GAN网络的优化目标

很相似。怎么解释呢?这个分类器D我们希望它能尽量分类出得到的feature是来自于哪一个domain,因此,D(Mt(xt))理想的结果是0,D(Ms(Xs))理想的结果是1,最小化LadvD 可以得到当前的域分类器D。得到D后,通过训练Xt,希望D尽可能区分不出二者,即:

这里,是Ms和Mt要满足的约束,比如,对于全权值共享来说,Ms=Mt,对于无权值共享来说,这两者无需满足任何约束。对于部分权值共享:
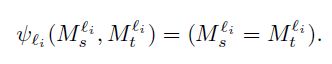
这表示,在第li层,Ms和Mt的权值是一样的。全权值共享不好,因为一个网络很难能够同时获取两个域的有用特征。
本文决定不给他们任何约束,即没有任何权值共享。那么剩下的问题就是如歌确定第二项:LadvM了。如果借鉴原始的GAN的思想:

这个的问题是容易发生梯度消失。改进方法是:将label反转,最优化目标变为:

希望D将Xt分类为1,该式子和上一个式子其实是等效的,但是有更强的梯度。如果Mt和Ms都不固定,这个loss function就不好,因为容易引发震荡,当然有其他选择,比如交叉熵:

当然,在本文中,我们固定了Ms,因此采用标准的GAN所采用的方法。至此,几个关键的选择都确定了,如下:

具体的操作:
1 先通过source domain的样本和标签训练Ms和C
2 保持Ms和C不变,用Ms初始化Mt,并交替优化第二项第三项,获得D和Mt
3 testing stage:target domain的sample直接通过Mt和C获得预测的标签。
图示如下:






