python 爬虫实践 (爬取链家成交房源信息和价格)
简单介绍
pi:
简单介绍下,我们需要用到的技术,python 版本是用的pyhon3,系统环境是linux,开发工具是vscode;工具包:request 爬取页面数据,然后redis 实现数据缓存,lxml 实现页面数据的分析,提取我们想要的数据,然后多线程和多进程提升爬取速度,最后,通过celery 框架实现分布式爬取,并实际部署下,下面就按这个逻辑顺序,进行介绍
request爬取页面数据
开发环境的的安装这里就不介绍了,大家可以在 去搜索下其他的博客,这类文章很多
第一步:通过pip 安装 request: pip install requests;
我们可以通过help(requests),查看下requests一些基本信息:
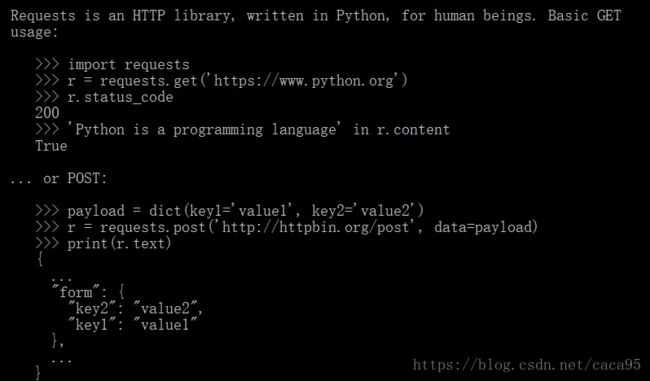
可以看到这里有两个方法一个get,一个post,post主要是一些需要提交表单的url,我们这里主要使用get方法,看下实际的代码吧:
resp = requests.get(url,headers=header,proxies=proxie,timeout=self.timeOut)
html = resp.text #text 属性获取具体的html文本
#小于400表示成功了
if resp.status_code >=400:
html = None
#500到600需要重试 400到500是可以直接退出的错误
if 600> resp.status_code >500 and self.numTry:
self.numTry -= 1
#递归 实现错误重试
return self.download(url,header,proxie)
except requests.exceptions.RequestException as e:
return {'html':None,'code':500}
return {'html':html,'code':resp.status_code}
resp 是访问网页响应实体,text属性是网页的文本内容,status_code 访问网站状态吗,可以通过它来判断访问网页是失败,还是成功,以及是否需要重试,还是不需要重试的报错;
像下载网页的具体内容,这种都是所有爬虫都是一样的,我们完全可以单独写一个类或者一个方法,以实现复用,这里我推荐,写个回调类,方便我们后面扩展,以及存储一些关键的信息,例如:缓存、代理、header
在实现这个类,之前我们下介绍下缓存,代理的实现;
代理
代理实现起来比较简单,request提供了很好的支持,只要给get()方法的proxies关键字参数,传一个代理队列就行resp = requests.get(url,headers=header,proxies=proxie,timeout=self.timeOut)
缓存
缓存需要重点介绍下,我们需要用到redis,redis的安装教程,推荐到菜鸟驿站去学习;
安装号redis服务器后,还需要安装python使用redis的模块, 直接pip安装就可以,pip install redis
,我们通过 url -> html文本的方式存储我们访问过的网页,然后直接上代码:
import json
import zlib
from redis import StrictRedis
from datetime import timedelta
class RedisCache:
#是否压缩文件 compress endcoding 编码方式,key:url value:html redis链接:client 设置缓存过期时间expires=timedelta(days=30)
def __init__(self,client=None,compress=True,endcoding='utf-8',expires=timedelta(days=30)):
self.client = StrictRedis(host='localhost',port=6379,db=0)
self.compress = True
self.endcoding =endcoding
self.expires = expires
#序列化 解压 解码 序列化
def __getitem__(self,url):
value = self.client.get(url)
if value:
if self.compress:
value = zlib.decompress(value)
return json.loads(value.decode(self.endcoding))
else:
raise KeyError(url+'does exit')
#反序列化 解码 解压
def __setitem__(self,url,html):
data = bytes(json.dumps(html),encoding=self.endcoding)
if self.compress:
data = zlib.compress(data)
#设置过期时间 setex
self.client.setex(url,self.expires,data)
这里我们还通过zilb模块对我们的代码进行了压缩,这是为了节省空间,因为redis是报内容存到磁盘中的,这里在说下这个self.client.setex(url,self.expires,data)方法,相比set方法,这个方法可以帮我们设置内容在数据库中的有效时间;
接下来实现下载类:
import requests
from redisCache import RedisCache
from throttle import Throttle
from random import choice
class Downloader:
#错误重复尝试次数 numTry,延迟 delay 缓存 cache user_agent proxies 代理
def __init__(self,user_angent='wsap',proxies=None,delay=5,numTry=5,cache=None,timeout =30):
self.user_agent=user_angent
self.proxies = proxies
self.delay =delay
self.numTry=numTry
self.cache = RedisCache()
self.throt = Throttle(delay)
self.timeOut =timeout
#回调方法,可以让类和方法一样被使用
def __call__(self,url):
try:
html = self.cache.__getitem__(url)
except KeyError:
html = None
if html is None:
self.throt.wait(url)
header = {'user-agent':self.user_agent}
#lamda表达式
proixe = choice(self.proxies) if self.proxies else None
html = self.download(url,header,proixe)
self.cache.__setitem__(url,html)
return html['html']
#处理url下载问题
def download(self,url,header,proxie):
try:
resp = requests.get(url,headers=header,proxies=proxie,timeout=self.timeOut)
html = resp.text
#小于400表示成功了
if resp.status_code >=400:
html = None
#500到600需要重试 400到500是可以直接退出的错误
if 600> resp.status_code >500 and self.numTry:
self.numTry -= 1
#递归 实现错误重试
return self.download(url,header,proxie)
except requests.exceptions.RequestException as e:
return {'html':None,'code':500}
return {'html':html,'code':resp.status_code}
这里介绍下,回调类,回调类和普通类的区别是,他必须实现__call__()方法,实现这个方法后我们就可以像调用方法一样调用我们的类,是不是很神奇(我也是接触python之后才知道的类还可以这么用,哈哈);看代码我们会发现 Throttle类,这个类干嘛的呢,他的主要目的是控制我们对同一个url访问间隔的,因为我们都知道,大多数网站都是不希望被爬虫光顾的,因为恶意的爬虫和质量不高的爬虫会造成服务器很大的压力;所以有很多反爬措施,我们使用代理也正是这个原因,同样这个类的目的也是样的,具体实现主要是个一个字典;具体代码如下:
from urllib.parse import urlparse
import time
class Throttle:
""" Add a delay between downloads to the same domain
"""
def __init__(self, delay):
# amount of delay between downloads for each domain
self.delay = delay
# timestamp of when a domain was last accessed
self.domains = {}
def wait(self, url):
domain = urlparse(url).netloc
last_accessed = self.domains.get(domain)
if self.delay > 0 and last_accessed is not None:
sleep_secs = self.delay - (time.time() - last_accessed)
if sleep_secs > 0:
# domain has been accessed recently
# so need to sleep
time.sleep(sleep_secs)
# update the last accessed time
self.domains[domain] = time.time()
到这里,一个善意的下载类已经写好了;网页内容都下下来了,怎么提取我们需要的内容呢;一个网页包含内容课太多了,这就需要用到我们下面的内容了,分析网页,抓取需要的数据;
lxml 实现页面数据的抓取
其实,分析网页的工具很多,最直接的就是我们的正则表达式了,这里还是推荐去菜鸟驿站,菜鸟驿站对于入门来说还是相当不错了,但是我们这里不用正则表达式,因为正则式太复杂了,啦啦啦,我们用更简单的工具,这就是大家爱python的原因?python为我们提供了很多处理html,xml的模块;有beautifulsoup、css选择器,xphath选择器;这里我用的xpath,要使用我们xpath我们需要安装lxml,还是一样,通过pip install lxml;
xphth 语法介绍:
- 选则所有链接 语法: //a
- 选择类名为“main” div 元素 语法: //div[@class=“main”]
- 选择ID为list 的ul 元素 语法: //ul[@id=“list”]
- 从所有段落中选择文本 语法: //p/text()
- 选择所有类名中包含test的div元素 语法: //div[contains(@class,‘test’)]
6.选择所有包含链接和列表的div元素 语法://div[a|ul]
来段代码吧:
def scrapy_callback(self,html):
tree = fromstring(html)
links = []
title = tree.xpath('//div[@class="house-title LOGVIEWDATA LOGVIEW"]/div/text()') #获取房子的信息
price = tree.xpath('//span[@class="dealTotalPrice"]/i/text()') #获取房子的价格
//div[@class=“house-title LOGVIEWDATA LOGVIEW”],全局文本下的所有class 属性 等于 house-title LOGVIEWDATA LOGVIEW div 标签;
/div,直接子节点下的所有div标签 /text() 标签的文本内容;
对于初学者最迷惑的就是这个 // 和 / ,// 可以理解未所有子节点下面,/ 直接子节点;
下面上完整的爬取代码:
import requests
from downloader import Downloader
from lxml.html import fromstring,tostring
import json
from multiprocessing import Process,queues
import time
import threading
class scrapyProcess(Process):
def __init__(self,region,q,agent,proxies,numThreads):
#实现父类构造函数
Process.__init__(self)
#小区列表
self.region = region
#爬取url列表
self.q = q
self.agent =agent
self.proxies =proxies
#多线程个数
self.numThreads = numThreads
#爬取方法的入口
def action(self):
while self.q:
D = Downloader(user_angent=self.agent, proxies=self.proxies)
url = self.q.pop()
html = D(url)
if html:
totalpages = self.scrapy_page(html)
if totalpages:
#遍历所有的网页
for page in range(2,totalpages):
urlpage = self.starturl+'/'+"pg"+str(page)+"/"
if urlpage not in self.seen:
self.seen.add(urlpage)
self.q.append(urlpage)
htmlpage = D(urlpage)
links = self.scrapy_callback(htmlpage)
for linkurl in links:
if linkurl not in self.seen:
self.seen.add(linkurl)
self.q.append(linkurl)
else:
print(url)
links = self.scrapy_callback(html)
for linkurl in links:
if linkurl not in self.seen:
self.seen.add(linkurl)
self.q.append(linkurl)
else:
continue
#获取新的成交房源url并且存储数据
def scrapy_callback(self,html):
tree = fromstring(html)
links = []
title = tree.xpath('//div[@class="house-title LOGVIEWDATA LOGVIEW"]/div/text()')
price = tree.xpath('//span[@class="dealTotalPrice"]/i/text()')
#插入数据库房子的信息 偷懒,存在文件里,没有再弄个数据库
try:
print(title)
with open('lianjia.txt','a') as f:
f.writelines(title + price)
finally:
if f:
f.close()
link = tree.xpath('//a[@class="img"]/@href')
link2= tree.xpath('//div[@class="fl pic"]/a/@href')
if link:
for li in link:
links.append(li)
if link2:
for li2 in link2:
links.append(li2)
return links
#构建爬取队列
#网页上的内容是一个页面无法显示的,所有这里获取网页的页数
def scrapy_page(self, html):
tree = fromstring(html)
pagejson = tree.xpath('//div[@class="page-box house-lst-page-box"]/@page-data')
totalpage=0
if pagejson:
pagejson = json.loads(pagejson[0])
totalpage = pagejson["totalPage"]
return totalpage
这里为什么这么写,需要结合链家网站来分析了,链家成交房源信息,就不带大家分析了,可以通过分析下代码,然后看看xpath所指向的节点应该就能明白代码的逻辑了;这部分代码大家也可以自己来实现啊,不一定非得和我这个一样;没啥特别的逻辑,就是通过xpath提取信息,然后通过一个set 去掉重复的url,避免重复提取同样的内容;
多线程和多进程提升爬取速度
python 里的多线程其实效率并不是很高(这是因为python里一个全局锁的概念,感兴趣的可以自行百度),更多的是多进程,这里我们采用多进程和多线程结合的方式,一定数量的进程加上一定数量的线程,对速度的提升相当给力,大概8个进程5个线程吧,这个比例最好了,效果显著;不要问我为啥是这个比例,我只说前人栽树,后人乘凉;我们也可以结合代码,调整比例验证下;
多线程 需要 import threading 多进程: from multiprocessing import Process,queues
python 的进程和线程提供了两种实现方式,一种是继承进程或线程类,实现run方法,自定义自己的多进程,还有就是直接实例化python为我们提供的类,并指定进程或线程方法;我这的显示思路是,下个自定义进程类,然后在类里开启实例化线程,指定线程方法;所以我们需要对上面的类进行下改造;
完整代码如下:
import requests
from downloader import Downloader
from lxml.html import fromstring,tostring
import json
from multiprocessing import Process,queues
import time
import threading
class scrapyProcess(Process):
def __init__(self,region,q,agent,proxies,numThreads):
#实现父类构造函数
Process.__init__(self)
#小区列表
self.region = region
#爬取url列表
self.q = q
self.agent =agent
self.proxies =proxies
#多线程个数
self.numThreads = numThreads
def run(self):
self.starturl = 'https://nj.lianjia.com/chengjiao/' + self.region+'/'
#需要用到共有资源需要枷锁
self.lock = threading.RLock()
#通过set控制不要重复爬取数据
self.seen = set()
self.q.append(self.starturl)
threads = []
#开启线程
for th in range(self.numThreads):
thread = threading.Thread(target=self.action())
thread.start()
threads.append(thread)
#线程主线程必须等到子线程关闭
for thj in threads:
thj.join()
def action(self):
while self.q:
self.lock.acquire()
#这个需要插入数据库,保证数据的唯一,需要放到线程里面
D = Downloader(user_angent=self.agent, proxies=self.proxies)
url = self.q.pop()
html = D(url)
if html:
totalpages = self.scrapy_page(html)
if totalpages:
for page in range(2,totalpages):
urlpage = self.starturl+'/'+"pg"+str(page)+"/"
if urlpage not in self.seen:
self.seen.add(urlpage)
self.q.append(urlpage)
htmlpage = D(urlpage)
links = self.scrapy_callback(htmlpage)
for linkurl in links:
if linkurl not in self.seen:
self.seen.add(linkurl)
self.q.append(linkurl)
else:
print(url)
links = self.scrapy_callback(html)
for linkurl in links:
if linkurl not in self.seen:
self.seen.add(linkurl)
self.q.append(linkurl)
self.lock.release()
else:
self.lock.release()
continue
#获取新的成交房源url并且存储数据
def scrapy_callback(self,html):
tree = fromstring(html)
links = []
title = tree.xpath('//div[@class="house-title LOGVIEWDATA LOGVIEW"]/div/text()')
price = tree.xpath('//span[@class="dealTotalPrice"]/i/text()')
#插入数据库房子的信息
try:
print(title)
with open('lianjia.txt','a') as f:
f.writelines(title + price)
finally:
if f:
f.close()
link = tree.xpath('//a[@class="img"]/@href')
link2= tree.xpath('//div[@class="fl pic"]/a/@href')
if link:
for li in link:
links.append(li)
if link2:
for li2 in link2:
links.append(li2)
return links
#构建爬取队列
def scrapy_page(self, html):
tree = fromstring(html)
pagejson = tree.xpath('//div[@class="page-box house-lst-page-box"]/@page-data')
totalpage=0
if pagejson:
pagejson = json.loads(pagejson[0])
totalpage = pagejson["totalPage"]
return totalpage
这里我给进程加了个锁的属性lock, 这是因为我们进程类,会开启多个线程(根据我们进程的numThreads),他们共享我们进程的所有变量,为了保证进程不出现数据混乱,所以需要加入锁;
最后,是我们的启动代码了:
if __name__ == '__main__':
#多进程
q = []
#regions 列表的长度就是我们进程的个数;
regions = ["gulou","jianye"]
process_list = []
numTh = 5
#记录下开始时间
start = time.time()
for region in regions:
scrapySpider = scrapyProcess(region,q,"Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:31.0) Gecko/20100101 Firefox/31.0",None,numTh)
scrapySpider.start()
process_list.append(scrapySpider)
#主进程必须等到子线程关闭
for pro in process_list:
pro.join()
#打印实际耗时
print ("耗时:%s"%time.time()-start)
我们可以通过设置regions的长度和numTh 来设置不同的进程和线程比例,并通过耗时,来验证我们比例了;
暂告一段落;下一篇我们为爬虫塔上分布式的顺风车 ,哈哈哈哈哈哈!有错误希望打家帮忙指出,第一次尝试写完整的博客
最后是完整的代码地址:
github地址
最后的最后
这边博客是学习python的一个总结,爬取网页和缓存借鉴了《用python写网络爬虫》这本书,也把这本书推荐个大家;对我的帮助挺大的