导入图像数据前处理问题-Pytorch深度学习框架-YOLOv1复现过程
关于利用Pytorch框架进行深度学习前导入的图像数据前处理问题
- 主要内容
- 1、程序总体框架
- 2、各部分具体实现
- 2.1读入图像及标签
- (1)标签文件说明
- (2)整合标签文件
- (3)验证box对应关系的正确性
- (4)编写数据读入程序
- 2.2 图像随机变化
- (1)翻转
- (2)放缩
- (3)滤波
- (4)亮度
- (5)色调
- (6)饱和度
- (7)裁剪
- 2.3 图像预处理
- 2.4 标签编码
- 2.5 产生数据子集
主要内容
本文是作者在复现YOLOv1算法时,所遇到的数据导入的问题的处理,数据导入及处理部分也是任何进行深度学习任务的必备操作,之后可能会写YOLOv1整个复现过程的详细解释,建议对照源代码进行参考,源代码可以留言想我索要,等完善好后,也会统一放置在GitHub上~
文本主要参考的是此项目GitHub,大家可以自行研究。
1、程序总体框架
- 读入图像及标签
- 图像随机预处理
- 标签编码
2、各部分具体实现
2.1读入图像及标签
这里我所使用的数据集为 COCO_train2014 数据集。
考虑到使用YOLO算法,其标签应包含box属性以及对应类别。
(1)标签文件说明
对于数据集标签文件的详细说明,可以参考这篇文章
以下只为本文所需要的内容进行说明
标签文件为json文件,可以直接在python中读取为字典类型
我们所用的标签类型为:object instances(目标实例)
整个结构体类型为:
{
"info": info,
"licenses": [license],
"images": [image],
"annotations": [annotation],
"categories": [category]
}
我们用到的是images和annotations类型,其都为列表类型,列表长度与图片数量相同
images记录的就是图片的信息,将其单独列出可看到:
{
"license": 5,
"file_name": "COCO_train2014_000000057870.jpg",
"coco_url": "http://images.cocodataset.org/train2014/COCO_train2014_000000057870.jpg",
"height": 480,
"width": 640,
"date_captured": "2013-11-14 16:28:13",
"flickr_url": "http://farm4.staticflickr.com/3153/2970773875_164f0c0b83_z.jpg",
"id": 57870
}
annotations记录的就是识别目标的标记信息,将其单独列出可看到:
{
'segmentation': [[312.29, 562.89, 402.25, 511.49, 400.96, 425.38, 398.39, 372.69, 388.11, 332.85, 318.71, 325.14, 295.58, 305.86, 269.88, 314.86, 258.31, 337.99, 217.19, 321.29, 182.49, 343.13, 141.37, 348.27, 132.37, 358.55, 159.36, 377.83, 116.95, 421.53, 167.07, 499.92, 232.61, 560.32, 300.72, 571.89]],
'area': 54652.9556,
'iscrowd': 0,
'image_id': 480023,
'bbox': [116.95, 305.86, 285.3, 266.03],
'category_id': 58,
'id': 86}
}
categories记录的就是识别目标的类别信息,将其单独列出可看到:
{
'supercategory': 'outdoor',
'id': 11,
'name': 'fire hydrant'}
}
可以看到bbox选项可能就是我们所用到的属性,但并不确定,以及segmentation猜测有可能是目标特征点,再就是annotations与images的对应,是顺序对应还是id对应也不确定,所以需要后续进行实验验证。
(2)整合标签文件
由上节可知,标签文件为字典类型,参数繁杂,所需要的参数分布不统一,所以可以考虑进行整合,方便操作
整合成总列表的行数代表图片序号(并非与图片ID对应),各列分别为:
| 图像文件名 | 类别ID | Box属性 |
|---|---|---|
| COCO_train2014_000000057870.jpg | [11,…] | [[116.95, 305.86, 285.3, 266.03],[…],…] |
| … | … | … |
这里应注意,考虑到一张图片中可能会有多个box,所以类别ID和Box属性应该是一个列表,且所处的位置应存在唯一对应关系,程序实现如下,其中的文件位置自行调整:
import json
label_list = []
# 打开标签文件
with open("E:/DATA/COCO2014/annotations_trainval2014/annotations/instances_train2014.json", 'r') as f:
label_dict = json.loads(f.read())
num = len(label_dict['images'])
for img in label_dict['images']:
img_name = img['file_name']
img_id = img['id']
# 储存类别ID和box属性的子列表
sublist_ID = []
sublist_box = []
# 搜寻
for anno in label_dict['annotations']:
if anno['image_id'] == img_id:
sublist_ID.append(anno['category_id'])
sublist_box.append(anno['bbox'])
# 整合到总列表
label_list.append([img_name, sublist_ID, sublist_box])
由于数据量庞大,且嵌套了两个循环,所以计算时间会非常长。
在实际进行训练时不应该把时间浪费在这上面,所以考虑每一个图片建立单独的文件,从而在训练时方便快速调用,每一个文件名可储存图像信息(图像名称),文件内部储存类和box信息(分为两行),故修改程序如下:
import json
label_list = []
# 打开标签文件
with open("E:/DATA/COCO2014/annotations_trainval2014/annotations/instances_train2014.json", 'r') as f:
label_dict = json.loads(f.read())
num = len(label_dict['images'])
# 循环一次搜寻图片对应信息
for img in label_dict['images']:
img_name = img['file_name']
img_id = img['id']
# 储存类别ID和box属性的子列表
sublist_ID = []
sublist_box = []
# 搜寻
for anno in label_dict['annotations']:
if anno['image_id'] == img_id:
sublist_ID.append(anno['category_id'])
sublist_box.append(anno['bbox'])
# 写入文件
with open("E:/DATA/COCO2014/label/"+img_name[:-4]+".txt", 'w') as f:
f.write(str(sublist_ID))
f.write('\n')
f.write(str(sublist_box))
(3)验证box对应关系的正确性
我们随便打开一个图片和标签文件,运用opencv画矩形框,验证box属性四个值分别对应,矩形左上角点坐标,和矩形的宽和高,程序实现如下,主要包括处理储存的标签信息和绘制矩形框。
import cv2
# 打开图像文件
img_name = 'COCO_train2014_000000016672'
img = cv2.imread('E:/DATA/COCO2014/train2014/train2014/' + img_name + '.jpg')
# 打开标签文件
with open("E:/DATA/COCO2014/label/"+img_name+".txt", 'r') as f:
lab = f.readlines()
catas = lab[0].replace(']', '').replace('[', '').replace(',', '').split()
catas = [int(x) for x in catas]
boxes = lab[1].replace(']', '').replace('[', '').replace(',', '').split()
boxes = [int(float(x)) for x in boxes]
for i in range(len(boxes)//4):
x, y, w, h = boxes[i*4:i*4+4]
cv2.rectangle(img, (x, y), (x+w, y+h), (0, 255, 0), 3)
cv2.imshow("image", img)
cv2.waitKey(0)
可以看到图像是没有问题的,说明验证正确。
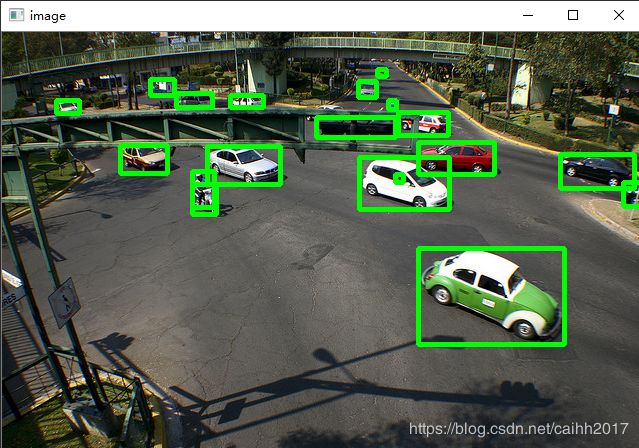
(4)编写数据读入程序
做完了上述准备工作,接下来就是编写正式的数据读入部分了。
为了方便后续处理,从这一步开始,我们开始运用类的方法,为了程序的可读性,应尽可能把所有程序放在一起,整体方便参考,但代码量会较多,所以我这里会采取局部简化,对于介绍过的内容写class 和def名称,只对当前进行的详细代码进行完整的记录,在接下来的实例中就可以明白了。
首先建立数据读入及处理的总类,pytorch框架的Dataset类,并建立初始化函数。
输入变量包括图像文件路径和标签文件路径
这里用到了一个__getitem__函数,可以增加迭代器,为了保证后续产生数据。
后面的main函数暂时用来进行debug
import torch.utils.data as data
import os
import cv2
class Dataset(data.Dataset):
def __init__(self, img_path, ann_path):
self.grid_num = 14
self.image_size = 448
self.img_path = img_path
self.ann_path = ann_path
# 读入图片文件夹下的所有图片名称
img_list = []
for _, _, files in os.walk(img_path):
img_list = [file[:-4] for file in files if file[-4:] == '.jpg']
self.img_list = img_list
self.num_samples = len(self.img_list)
def __getitem__(self, idx):
# 读入标签
file_label = '%s%s.txt' % (self.ann_path, self.img_list[idx])
with open(file_label, 'r') as f:
lab = f.readlines()
catas = lab[0].replace(']', '').replace('[', '').replace(',', '').split()
labels = [int(x) for x in catas]
boxes = lab[1].replace(']', '').replace('[', '').replace(',', '').split()
boxes = [(float(x)) for x in boxes]
boxes = np.array(boxes).reshape((-1, 4))
boxes = torch.Tensor(boxes)
labels = torch.Tensor(labels).long()
# 读入图像
file_img = '%s%s.jpg' % (self.img_path, self.img_list[idx])
img = cv2.imread(file_img)
return print(labels), print(boxes), print(img.shape)
def main():
dataset = Dataset(img_path='E:/DATA/COCO2014/train2014/train2014/', ann_path='E:/DATA/COCO2014/label/')
dataset[1]
if __name__ == '__main__':
main()
看到输出结果如下,说明编写成功。
[25, 25]
[385, 60, 214, 297, 53, 356, 132, 55]
(426, 640, 3)
2.2 图像随机变化
同上,通过上述预处理工作,基本可以对数据进行接下来的训练了,但为了保证训练泛化能力,通常还会在图像预处理期间加入图像随机变化,具体解析可百度详解,这里就只介绍程序实现。
class Dataset(data.Dataset):
def __init__(self, img_path, ann_path):
...
def __getitem__(self, idx):
# 读入标签
#...
# 读入图像
#...
# 图像随机处理
# 颠倒
img, boxes = self.rand_flip(img, boxes)
# 放缩
img, boxes = self.rand_scale(img, boxes)
# 滤波
img = self.rand_blur(img)
# 亮度
img = self.rand_bright(img)
# 色调
img = self.rand_hue(img)
# 饱和度
img = self.rand_saturation(img)
# 随机剪切
img, boxes, labels = self.rand_crop(img, boxes, labels)
(1)翻转
关键在于翻转后box属性中的坐标值的计算,考虑框在左右、上下完全颠倒,可自行推算出计算公式。
def rand_flip(self, im, boxes):
if random.random() < 0.5:
im[:, :, 0] = np.flip(im[:, :, 0]).copy()
im[:, :, 1] = np.flip(im[:, :, 1]).copy()
im[:, :, 2] = np.flip(im[:, :, 2]).copy()
h, w, _ = im.shape
boxes[:, 0] = w - boxes[:, 0] - boxes[:, 2]
boxes[:, 1] = h - boxes[:, 1] - boxes[:, 3]
return im, boxes
处理结果

(2)放缩
随机放缩图片的0.8~1.2倍的宽度和宽度。
box宽度和高度方向的属性也要做对应放缩。
def rand_scale(self, im, boxes):
if random.random() < 0.5:
scalew = random.uniform(0.8, 1.2)
scaleh = random.uniform(0.8, 1.2)
h, w, _ = im.shape
im = cv2.resize(im, (int(w*scalew), int(h*scaleh)))
scale_boxes = torch.Tensor([[scalew, scaleh, scalew, scaleh]]).expand_as(boxes)
boxes *= scale_boxes
return im, boxes
(3)滤波
滤波较为简单,直接运用opencv滤波函数滤波
def rand_blur(self, im):
if random.random() < 0.5:
im = cv2.blur(im, (5, 5))
return im
(4)亮度
这里用到了一个hsv通道转换,关于hsv的详情可以自行百度
def rand_bright(self, im):
if random.random() < 0.5:
im_hsv = cv2.cvtColor(im, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(im_hsv)
adjust = random.choice([0.5, 1.5])
v = v * adjust
v = np.clip(v, 0, 255).astype(im_hsv.dtype)
im_hsv = cv2.merge((h, s, v))
im = cv2.cvtColor(im_hsv, cv2.COLOR_HSV2BGR)
return im
(5)色调
同理上
def rand_hue(self, im):
if random.random() < 0.5:
im_hsv = cv2.cvtColor(im, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(im_hsv)
adjust = random.choice([0.5, 1.5])
h = h * adjust
h = np.clip(h, 0, 255).astype(im_hsv.dtype)
im_hsv = cv2.merge((h, s, v))
im = cv2.cvtColor(im_hsv, cv2.COLOR_HSV2BGR)
return im
(6)饱和度
同理上
def rand_saturation(self, im):
if random.random() < 0.5:
im_hsv = cv2.cvtColor(im, cv2.COLOR_BGR2HSV)
h, s, v = cv2.split(im_hsv)
adjust = random.choice([0.5, 1.5])
s = s * adjust
s = np.clip(s, 0, 255).astype(im_hsv.dtype)
im_hsv = cv2.merge((h, s, v))
im = cv2.cvtColor(im_hsv, cv2.COLOR_HSV2BGR)
return im
(7)裁剪
对于裁剪操作,首先应随机确定裁剪后的图像高度宽度以及位置。
根据位置变化情况,首先依次判定box中心是否还位于图片内部,否则取消该box和所属类别。
如果发现box全出了,说明裁剪的太巧了,把所有box都排开了,这时,返回原有的图像box。
否则,则更新box属性信息到新图片中,对于超过图像的box宽度也要进行修正到边框。
最后将图片更新为裁剪之后的图片
def rand_crop(self, im, boxes, labeles):
if random.random() < 0.5:
h, w, c = im.shape
rand_h = int(random.uniform(0.6 * h, h))
rand_w = int(random.uniform(0.6 * w, w))
rand_x = int(random.uniform(0, w - rand_w))
rand_y = int(random.uniform(0, h - rand_h))
cen = boxes[:, 0:2]+boxes[:, 2:]/2
cen = cen - torch.Tensor([[rand_x, rand_y]]).expand_as(cen)
mask1 = (cen[:, 0] > 0) & (cen[:, 0] < w)
mask2 = (cen[:, 1] > 0) & (cen[:, 0] < h)
mask = (mask1 & mask2).view(-1, 1)
boxes_crop = boxes[mask.expand_as(boxes)].view(-1, 4)
labeles_crop = labeles[mask.view(-1)]
if len(boxes_crop) == 0:
return im, boxes, labeles
boxes_crop = boxes_crop - torch.Tensor([[rand_x, rand_y, 0, 0]]).expand_as(boxes_crop)
for i, value in enumerate(boxes_crop):
boxes_crop[i, 0] = torch.clamp(value[0], 0, max=w)
boxes_crop[i, 1] = torch.clamp(value[1], 0, max=h)
boxes_crop[i, 2] = torch.clamp(value[2], 0, max=w - value[0])
boxes_crop[i, 3] = torch.clamp(value[3], 0, max=h - value[1])
img_crop = im[rand_y:rand_y+h, rand_x:rand_x+w]
return img_crop, boxes_crop, labeles_crop
return im, boxes, labeles
2.3 图像预处理
图像预处理主要是包括:
- 标准化box属性,因为考虑后面的图像尺寸有可能发生变化,所以可以将box单位化,实际上表达的是在图片上的相对位置,所以图像的简单的等比例放大缩小就不会影响box属性了,但对于特定的图像变化,则需要同时对box属性进行处理,这部分放在后面介绍。
- 转换通道。由于opencv读取的图片通道格式为BGR,而pytorch处理图片则采取RGB的形式,所以需要通道转化。
- 统一尺寸,考虑卷积网络的第一层输入层应该为统一的输入图像尺寸,所以需要resize
- 减去均值,这一部分主要是为了更容易优化参数,具体可以自行百度(图像处理减去均值)
- 编码,这部分主要是将读取的标签信息处理成卷积网络最后一层的输出格式,方便计算损失函数,具体在下一小节说明。
程序如下:
import torch.utils.data as data
import os
import cv2
import numpy as np
import torch
class Dataset(data.Dataset):
def __init__(self, img_path, ann_path):
#...
def __getitem__(self, idx):
# 读入标签
#...
# 读入图像
#...
# 随机图像处理
#...
# 图像预处理
# 标准化box属性
boxes = torch.Tensor(boxes)
h, w, _ = img.shape
boxes /= torch.Tensor([w, h, w, h]).expand_as(boxes)
# 转换通道
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 统一尺寸
img = cv2.resize(img, (self.image_size, self.image_size))
# 减去均值
img = img - np.array([123, 117, 104])
# 编码
target = self.encoder(boxes, labels)
return img, target
2.4 标签编码
这一部分主要是将预处理好的图像和box进行整合编码,与卷积网络最后一层输出层格式相同。
输入变量为两个:boxes 和 labels
输出变量应为17x17x95的张量。
17x17为划分的网格尺寸。
在本文所使用的数据集中,总分类数为90,考虑每个网格只有一个box属性,包括box中心点两个坐标值,box长和宽值和判定概率五个参数,所以共计95个参数。
编码的整体思路就是:
循环boxes和labels
读取box属性
确定中心点所在方格
计算中心点所在方格的相对坐标
按照变量顺序依次写入编码张量
程序如下:
class Dataset(data.Dataset):
def __init__(self, img_path, ann_path):
#...
def __getitem__(self, idx):
#...
# 编码
target = self.encoder(boxes, labels)
def __len__(self):
return self.num_samples
def encoder(self, boxes, labels):
target = torch.zeros((self.grid_num, self.grid_num, 95))
cell_size = 1 / self.grid_num
for box, label in zip(boxes, labels):
# box 中心点坐标
cen_loc = box[:2] + box[2:]/2
# 中心点所在方格位置
ij = np.ceil((cen_loc/cell_size))-1
# 中心点相对坐标
loc_xy = (cen_loc - ij*cell_size)/cell_size
# 写入编码
target[int(ij[1]), int(ij[0]), :2] = loc_xy
target[int(ij[1]), int(ij[0]), 2:4] = box[2:]
target[int(ij[1]), int(ij[0]), 4] = 1
target[int(ij[1]), int(ij[0]), label] = 1
return target
注意到程序中多了一个 __len__函数,表征的是图像总个数,self.num_samples直接在init里面定义为总图像个数即可。
2.5 产生数据子集
这里用到的就是pytorch框架里面的DataLoader函数,具体详解可以百度,这里直接调用即可
dataset = Dataset(img_path='E:/DATA/COCO2014/train2014/train2014/', ann_path='E:/DATA/COCO2014/label/')
train_loader = DataLoader(dataset, batch_size=64, shuffle=False, num_workers=0)
这样,batch数据的任务也就完成了
通过上述流程,也就可以进行自己数据集的建立和导入,从而进行自己数据的训练任务了。
本文中还会有很多错误,还请大家积极指出共同讨论~