LSTM: A Search Space Odyss论文学习
Abstract
自从1995年长短记忆神经网络结构第一次被提出,到现在它已经有了若干个变体。近些年来,这些网络已经成为许多机器学习问题解决方案的state of the art 的模型。这需要人们去进一步地认识、理解LSTM及其变体的作用和其各种计算组成。这篇论文中,我们对3个任务上的8个LSTM变体进行了详细的分析:语音识别、手写字识别、复调音乐建模。对于每个任务,所有LSTM变体的超参数都通过随机搜索单独进行了优化。我们通过fANOVA框架来评估它们的重要性。我们一共归纳了5400个实验(约15年的CPU运行时间),应该是针对LSTM网络最广泛的研究了。结果显示,没有一个变体可以明显地超越标准的LSTM架构,证明遗忘门和输出激活函数是LSTM最重要的组成部分。我们进一步发现,超参数事实上是独立的。
1. Introduction
带有长短记忆的递归神经网络(我们直接称作LSTM)已经成为众多序列数据学习任务上非常有效可靠的模型。早期解决这些问题的方法要么只能解决某一特殊问题,要么就无法处理长时间的依赖。而LSTM在获取长时间依赖上泛化能力很强,也很高效。它不会遇到简单递归网络(SRN)碰到的优化障碍,在许多困难的问题上都取得了state of the art的成效。这其中包括手写字的识别和生成、语言建模和翻译、语音建模、语音合成、蛋白质第二结构预测、音频分析、视频数据等。
LSTM背后的核心思想就是一个可以随着时间变化而保持其状态的记忆细胞,以及非线性的gating units,控制信息流在细胞中的输入和输出。绝大多数当前的研究都加入了对LSTM的改进。但是,LSTM现在经常应用在与那些改进无论在尺度还是本质都差异很大学习任务上。我们缺乏一个对LSTM不同计算组成的系统研究。这篇论文就填补了这个空白,系统地解决LSTM架构提升的开放性问题。
我们在3个benchmark问题上评价了最流行的LSTM架构(Vanilla LSTM,第二部分)以及8个不同的变体:语音建模、手写字识别、复调音乐建模。每一个变体都对vanilla LSTM有一处改动。这允许我们在网络性能上剥离出每一个改动的影响。对于每个问题上的变体网络,我们使用了随机搜索来找到最佳表现的超参数。使得不同变体之间的比较是可靠的。我们也通过fANOVA给出关于了这些超参数以及它们之间相互作用的思考。
2. VANILLA LSTM
学术文献中最常用的LSTM最开始是由Graves和Schmidhuber提出。我们将之称作为vanilla LSTM,并用它和所有的变体进行比较。Vanilla LSTM在原来的LSTM中加入了一些改动,使用全梯度来训练。第三章描述了这些LSTM主要的变动之处。
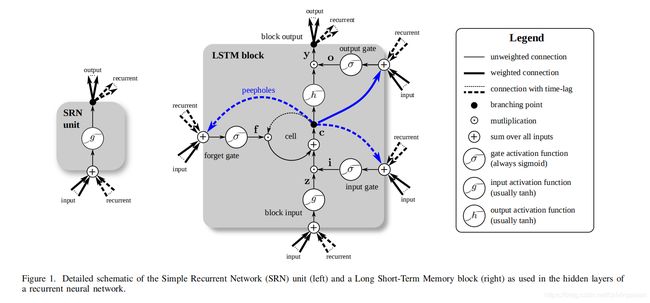
Vanilla LSTM模块的结构可以参考图1。它主要有3个gates(输入,遗忘,输出)、模块输入、一个单细胞、一个输出激活函数,以及窥视孔连接(peephole connections)。该模块的输出以递归的方式连接至该模块的输入和所有的gates。
A. Forward Pass
x t x^t xt是 t t t时刻的输入向量, N N N是LSTM模块的个数, M M M是输入的个数。然后我们得到如下的LSTM层的权重:
- 输入权重: W z , W i , W f , W o ∈ R N × M W_z, W_i, W_f, W_o \in R^{N\times M} Wz,Wi,Wf,Wo∈RN×M
- 递归权重: R z , R i , R f , R o ∈ R N × N R_z, R_i, R_f, R_o \in R^{N\times N} Rz,Ri,Rf,Ro∈RN×N
- Peephole权重: p i , p f , p o ∈ R N p_i, p_f, p_o \in R^N pi,pf,po∈RN
- 偏置权重: b z , b i , b f , b o ∈ R N b_z, b_i,b_f, b_o \in R^N bz,bi,bf,bo∈RN
那么,vanilla LSTM层前向传播的向量公式就可以写作:
z ‾ t = W z x t + R z y t − 1 + b z \overline z^t = W_z x^t + R_z y^{t-1} + b_z zt=Wzxt+Rzyt−1+bz
z t = g ( z ‾ t ) z^t = g(\overline z^t) \quad\quad\quad\quad\quad\quad \quad\quad\quad\quad\quad\quad zt=g(zt)block input
i ‾ t = W i x t + R i y t − 1 + p i ⨀ c t − 1 + b i \overline i^t = W_i x^t + R_i y^{t-1} + p_i\bigodot c^{t-1} + b_i it=Wixt+Riyt−1+pi⨀ct−1+bi
i t = σ ( i ‾ t ) i^t = \sigma(\overline i^t) \quad\quad\quad\quad\quad\quad \quad\quad\quad\quad\quad\quad it=σ(it) input gate
f ‾ t = W f x t + R f y t − 1 + p f ⨀ c t − 1 + b f \overline f^t = W_f x^t + R_f y^{t-1} + p_f \bigodot c^{t-1} + b_f ft=Wfxt+Rfyt−1+pf⨀ct−1+bf
f t = σ ( f ‾ t ) f^t = \sigma(\overline f^t) \quad\quad\quad\quad\quad\quad \quad\quad\quad\quad\quad\quad ft=σ(ft) forget gate
c t = z t ⨀ i t + c t − 1 ⨀ f t c^t = z^t \bigodot i^t + c^{t-1}\bigodot f^t \quad\quad\quad\quad\quad\quad\quad ct=zt⨀it+ct−1⨀ft cell
o ‾ t = W o x t + R o y t − 1 + p o ⨀ c t + b o \overline o^t = W_o x^t + R_o y^{t-1} + p_o \bigodot c^t + b_o ot=Woxt+Royt−1+po⨀ct+bo
o t = σ ( o ‾ t ) o^t = \sigma(\overline o^t) \quad\quad\quad\quad\quad\quad \quad\quad\quad\quad\quad\quad ot=σ(ot) output gate
y t = h ( c t ) ⨀ o t y^t = h(c^t) \bigodot o^t \quad\quad\quad\quad\quad\quad \quad\quad\quad\quad yt=h(ct)⨀ot block output
其中, σ , g , h \sigma, g, h σ,g,h分别是point-wise 非线性激活函数。Logistic sigmoid( σ ( x ) = 1 1 + e − x \sigma(x) = \frac{1}{1+e^{-x}} σ(x)=1+e−x1)
用作gate激活函数,双曲正切函数(g(x)=h(x)=tanh(x))作为模块的输入和输出激活函数使用。两个向量的Pointwise相乘用 ⨀ \bigodot ⨀表示。
B. Backpropagation Through Time
LSTM模块内的 δ \delta δ’s计算如下:
δ y t = Δ t + R z T δ z t + 1 + R i T δ i t + 1 + R f T δ f t + 1 + R o T δ o t + 1 \delta y^t = \Delta^t + R_z^T \delta z^{t+1} + R^T_i \delta i^{t+1} + R_f^T \delta f^{t+1} + R^T_o \delta o^{t+1} δyt=Δt+RzTδzt+1+RiTδit+1+RfTδft+1+RoTδot+1
δ o ‾ t = δ y t ⨀ h ( c t ) ⨀ σ ′ ( o ‾ t ) \delta \overline o^t = \delta y^t \bigodot h(c^t) \bigodot \sigma' (\overline o^t) δot=δyt⨀h(ct)⨀σ′(ot)
δ c t = δ y t ⨀ o t ⨀ h ′ ( c t ) + p o ⨀ δ o ‾ t + p i ⨀ δ i ‾ t + 1 + p f ⨀ δ f ‾ t + 1 + δ c t + 1 ⨀ f t + 1 \delta c^t = \delta y^t \bigodot o^t \bigodot h'(c^t)+p_o \bigodot \delta \overline o^t + p_i \bigodot \delta \overline i^{t+1} + p_f \bigodot \delta \overline f^{t+1} + \delta c^{t+1} \bigodot f^{t+1} δct=δyt⨀ot⨀h′(ct)+po⨀δot+pi⨀δit+1+pf⨀δft+1+δct+1⨀ft+1
δ f ‾ t = δ c t ⨀ c t − 1 ⨀ σ ′ ( f ‾ t ) \delta \overline f^t = \delta c^t \bigodot c^{t-1} \bigodot \sigma' (\overline f^t) δft=δct⨀ct−1⨀σ′(ft)
δ i ‾ t = δ c t ⨀ z t ⨀ σ ′ ( i ‾ t ) \delta \overline i^t = \delta c^t \bigodot z^t \bigodot \sigma'(\overline i^t) δit=δct⨀zt⨀σ′(it)
δ z ‾ t = δ c t ⨀ i t ⨀ g ′ ( z ‾ t ) \delta \overline z^t =\delta c^t \bigodot i^t \bigodot g'(\overline z^t) δzt=δct⨀it⨀g′(zt)
这里, Δ t \Delta^t Δt是从上面的层传递过来的 δ \delta δ’s向量。如果 E E E是损失函数,它就对应着 ∂ E ∂ y t \frac{\partial E}{\partial y^t} ∂yt∂E,但不包括递归依赖项。如果它下面存在着一层需要训练,我们才需要输入的 δ \delta δ’s,计算如下:
δ x t = W z T δ z ‾ t + W i T δ i ‾ t + W f T δ f ‾ t + W o T δ o ‾ T \delta x^t = W_z^T \delta \overline z^t + W_i^T \delta \overline i^t + W^T_f \delta \overline f^t +W_o^T \delta \overline o^T δxt=WzTδzt+WiTδit+WfTδft+WoTδoT
最终,权重的梯度计算如下, ⋆ \star ⋆可以是 { z ‾ , i ‾ , f ‾ , o ‾ } \{\overline z, \overline i, \overline f, \overline o\} {z,i,f,o}中的任一个, ⟨ ⋆ 1 , ⋆ 2 ⟩ \langle \star_1, \star_2 \rangle ⟨⋆1,⋆2⟩表示两个向量的外积:
δ W ⋆ = ∑ t = 0 T ⟨ δ ⋆ t , x t ⟩ \delta W_{\star} = \sum_{t=0}^T \langle \delta_{\star}^t, x^t \rangle δW⋆=∑t=0T⟨δ⋆t,xt⟩
δ p i = ∑ t = 0 T − 1 c t ⨀ δ i ‾ t + 1 \delta p_i = \sum_{t=0}^{T-1} c^t \bigodot \delta \overline i^{t+1} δpi=∑t=0T−1ct⨀δit+1
δ R ⋆ = ∑ t = 0 T − 1 ⟨ δ ⋆ t + 1 , y t ⟩ \delta R_{\star} = \sum_{t=0}^{T-1} \langle \delta_{\star}^{t+1}, y^t \rangle δR⋆=∑t=0T−1⟨δ⋆t+1,yt⟩
δ p f = ∑ t = 0 T − 1 c t ⨀ δ f ‾ t + 1 \delta p_f = \sum_{t=0}^{T-1} c^t \bigodot \delta \overline f^{t+1} δpf=∑t=0T−1ct⨀δft+1
δ b ⋆ = ∑ t = 0 T δ ⋆ t \delta b_{\star} = \sum_{t=0}^T \delta_{\star}^t δb⋆=∑t=0Tδ⋆t
δ p o = ∑ t = 0 T c t ⨀ δ o ‾ t \delta p_o = \sum_{t=0}^T c^t \bigodot \delta \overline o^t δpo=∑t=0Tct⨀δot
3. History of LSTM
起初版本的LSTM包括细胞、输入和输出门,没有遗忘门,没有peephole连接。在特定的实验中,输出门,unit bias,或者输入激活函数都被省去了。人们使用实时的递归学习(RTRL)和跨时反向传播(BPTT)的混合策略来训练模型。只有细胞的梯度会被传播回去,其他递归连接的梯度都被剪掉。因此,该研究没有使用实际的梯度来训练。该版本的另一个特征就是使用了full gate 递归,即除了从模块输出而来的递归输入,所有的gates也都接收上一时间点所有gates的递归输入。这个特征在后续的论文中都没有出现过。
A. Forget Gate
第一篇对LSTM结构作出变动的论文提出了遗忘门,使得LSTM可以重新设置它的状态。这允许我们去学习连续的任务,如embedded Reber grammar.
B. Peephole Connections
Gers和Schmidhuber 指出,要想学习准确的时间,细胞需要控制这些门。到目前为止,我们只能通过一个开放的输出门来实现。在网络结构中增加了Peephole 连接(由细胞到gates的连接,图1中的蓝线),使得时间更容易学习。此外,他们省去了输出激活函数,因为没有证据表明它对问题的解决特别重要。
C. Full Gradient
Graves 和 Schmidhuber对vanilla LSTM作了最终的调整。该研究提出了对于LSTM网络的跨时间的完全反向传播(BPTT)训练,结构如第二章所述,在TIMIT benchmark上列出了结果。使用完全的BPTT有一项额外的优点,即LSTM梯度可以通过有限的差异来校对,使得实际实现更加可靠。
D. Other Variants
自从LSTM被提出,vanilla LSTM 已经成为最常用的结构,人们也有提出其他的变体结构。在完全BPTT训练提出以前,Gers等人使用了一个基于扩展卡尔慢滤波的训练方法,在几个病理学案例上训练LSTM,计算复杂度极高。Schmidhuber 等人提出使用一种混合的、基于进化的方法来训练,而非BPTT,但效果和vanilla LSTM结构差不多。
Bayer等人演化出了不同的LSTM模块结构,在上下文-敏感的语法上最大化其拟合程度。Jozefowicz等人随后进行了更大规模的研究。Sak等人提出了一个线性映射层,在递归和前向连接之前,将LSTM层的输出映射下去,降低LSTM网络的超参数个数。通过对gate激活函数的梯度引入一个可训练的缩放参数,Doetsch等人在线下手写字识别数据集上提升了LSTM的表现。Otte等人通过在单个模块的各门之间增加递归连接,改进了LSTM收敛的速度,他们称之为Dynamic Cortex Memory。
Cho等人提出了一个LSTM结构的简化版本,称作Gated Recurrent Unit(GRU)。他们既不使用peephole连接,也没使用输出激活函数,将输入和遗忘门耦合为一个update gate。最终,它们的输出gate(称为reset gate)只控制模块输入( W z W_z Wz)的递归连接。Chung等人对GRU和vanilla LSTM做了比较,报告了其结果。
4. EVALUATION SETUP
Pls read paper for more details.