Fast Online Object Tracking and Segmentation: A Unifying Approach 论文学习
Fast Online Object Tracking and Segmentation: A Unifying Approach
- Abstract
- 1. Introduction
- 2. Related Work
- Visual Object Tracking
- Semi-supervised Video Object Segmentation
- 3. Methodology
- 3.1 全卷积 Siamese 网络
- SiamFC
- SiamRPN
- 3.2 SiamMask
- Loss Function
- Mask Representation
- Two Variants
- Box Generation
- 3.3 实现细节
- 网络结构
- 训练
- 推理
- 4. 实验
论文地址:https://arxiv.org/abs/1812.05050
代码地址:https://github.com/foolwood/SiamMask
Abstract
在这篇论文,作者阐述了如何进行实时且单阶段的目标追踪和视频中的物体分割。他们把这个方法命名为 SiamMask,用一个二元分割任务增强损失函数,优化目前流行的全卷积Siamese方法的线下训练。在训练过程中,SiamMask 只需初始化边框,然后通过线上操作,产生与类别无关的物体分割masks以及边框,速度为35帧每秒。此方法很简洁,速度快,它在VOT-2018上也能和 state of art 的追踪器相比较,表现极具竞争力,在半监督视频物体分割任务DAVIS-2016和DAVIS-2017上,它的速度是最快的。项目网址是:http://www.robots.ox.ac.uk/~qwang/SiamMask
1. Introduction
在视频应用上进行物体追踪是一个很基础的任务,它需要在不同帧之间建立物体的联系。在自动监控,车辆导航,视频标注,人机交互,以及活动识别上有着广泛的应用场景。视觉物体追踪的目的是,给定第一帧画面中某物体的位置,它需要找到在接下来所有帧上的位置预测。
在许多应用上,跟踪需要做到线上运行(视频一边播放,跟踪同时进行)。也就是说,跟踪器不可以利用未来帧来推理出当前位置。这就是物体跟踪benchmarks 上所需要的场景,通过边框坐标来表现目标物体。这种标注方法让数据标注成本很低;而且,它允许用户迅速而简单地完成目标的初始化。

和物体追踪类似,半监督的视频物体分割(VOS)需要预测第一帧中选定的任意物体的位置。但是,在VOS中,物体的呈现是由一个二元分割mask构成,也就是某个像素点是否属于目标物体。这对需要像素级别信息的应用很有帮助。但是,与简单的边框相比,生成像素级的预测需要更多的算力资源。因此,VOS方法都很慢,每一帧要处理几秒钟。近来,虽然有一些更快的方法被提出,但是就是最快的也做不到实时。
这篇论文中,我们旨在通过SiamMask缩小物体跟踪和VOS的差距,SiamMask是一个简单的多任务学习方法,可用于解决这两个问题。全卷积Siamese网络在物体跟踪上比较成功,速度较快,它在几百万对视频帧上进行线下训练;而且近来也有了像素级标注的数据集如YoTube-VOS,我们受它们启发提出了SiamMask。我们意图保留这些方法线下的可训练性,以及线上的速度;同时,极大地改善它们对目标物体的表现力。
为了实现这个想法,我们在3个任务上同时训练Siamese网络,每一个任务对应着不同的策略,这样在新的画面上,不同的目标物体和候选区域之间建立联系。与 Bertinetto 的全卷积方法类似,我们的一个任务是以滑动窗口的方式,学习目标物体和候选区的相似度。输出是一个 dense response map,它只表明物体的位置,而没有提供任何的空间范围信息。为了优化此信息,我们同时学习两个额外的任务:利用RPN进行的边框回归,以及二元分割。二元标签只在线下训练的时候用到,用于计算分割损失,而在追踪时候没有使用。在我们提出的网络结构中,每一个任务由一个分支来表现,它们都基于一个共享的CNN,最后由一个最终损失值汇总计算。
训练的时候,SiamMask 仅需要初始化一个物体边框,然后进行线上操作,生成物体分割的 masks 和物体边框,速度为35帧每秒。尽管它很简洁,速度也很快,SiamMask 在 VOT-2018实时物体跟踪任务上是 state of art 的。而且,在DAVIS-2016和DAVIS-2017上,此方法和最近的半监督VOS方法相比,也极具竞争力。SiamMask 只需要初始化一个物体边框,不需要其它VOS方法采用的计算成本很高的操作,如 fine-tune, 数据增强,optical flow等。
第二节简述最近在视觉物体跟踪和VOS上的其它工作;第三节简述我们的方法;第四节在4个benchmarks 上对我们的方法进行评估;第五节总结此论文。
2. Related Work
Visual Object Tracking
直到最近,最主流的用于物体跟踪的方法仍然是在线训练一个分类器,基于视频第一帧的真值信息,然后在线更新它。这个策略通常被称作"tracking-by-detection"。在过去几年,相关滤波器(Correlation Filter)成为解决 tracking-by-detection 的一个快速而有效的策略,快速滤波器可以辨别任意物体的模板和它的2D变形。
最近,有人提出了一个完全不同的方法。它不在线学习一个判别分类器,而是线下训练相似度函数,基于每一对的视频帧。在新的视频上测试时,这个函数能被简单地评价,每次一帧。全卷积Siamese方法的改进版通过region proposals, hard negative mining, ensembling, 和 memory networks,极大地提升了追踪性能。
绝大多数的追踪器都使用一个矩形框来初始化目标物体,然后在接下来的画面上预测位置。尽管很方便,但是一个简单的矩形框通常无法很好地表现一个物体。这促使我们提出一个能够生成二元分割mask的追踪器,而它只需要初始化一个物体边框。
Semi-supervised Video Object Segmentation
物体跟踪 benchmarks 假设跟踪器以连续的方式获取输入帧。而且,它们的方法通常关注在速度上,要超过视频的帧率。但是,半监督的VOS算法则更关注在准确的物体表现上。
为了获得最高的准确性,在测试时VOS方法通常会使用算力要求很高的技术,如 finetune, 数据增强和optical flow等。因此,它们的帧率都很低,无法在线运行。
3. Methodology
为了实现在线可操作性以及速度要求,我们采用全卷积Siamese 网络,用SiamFC和SiamRPN作为代表例子。
3.1 全卷积 Siamese 网络
SiamFC
Bertinetto 建议使用一个线下训练的全卷积Siamese网络,作为追踪系统里基础的模块,它将一个样例图片 z z z和一个搜索图片 x x x进行比较,获取一个dense response map。 z z z是一个 w × h w\times h w×h的裁剪图片,以目标物体为中心; x x x是一个更大的裁剪图片,以目标物体为中心。这两个输入由同一个CNN f θ f_\theta fθ处理,产生两个特征图,
g θ ( z , x ) = f θ ( z ) ⋆ f θ ( x ) . g_\theta (z,x) = f_\theta (z) \star f_\theta (x). gθ(z,x)=fθ(z)⋆fθ(x).
在这篇论文,我们将response map上的每个空间元素(上述公式左边)称作 response of a candidate window(RoW)。例如, g θ n ( z , x ) g_\theta ^n (z,x) gθn(z,x)将样例 z z z和 x x x中的第 n n n个候选窗口的相似度进行编码。对于SiamFC,response map 上的最大值就对应着目标物体在搜索区域 x x x上的位置。为了让每一个RoW都能包含目标物体的丰富信息,我们将上述等式中的 simple cross-correlation替换为depth-wise cross correlation,产生一个多通道的 response map。SiamFC 在几百万个视频画面上进行线下训练,用了 Logistic 损失 — L s i m L_{sim} Lsim。
SiamRPN
Li 极大地提升了SiamFC的表现,通过RPN,它能通过高宽比变动的边框来预测目标物体的位置。尤其,在SiamRPN中,每一个RoW都编码着一组 k k k个 anchor box候选区以及对应的物体/背景置信度。因而,SiamRPN输出边框预测以及分类置信度。这两个输出分支通过 Smooth L1 和交叉熵损失来训练。我们用 L b o x L_{box} Lbox和 L s c o r e L_{score} Lscore来分别表述它们。
3.2 SiamMask
与现有依赖于低可靠度的物体表现方法不同,我们认为生成每一帧的二元分割mask很重要。我们证明,除了相似性置信度和边框坐标之外,用全卷积Siamese网络的RoW也能对必要的信息进行编码,产生像素级的二元mask。我们可以用一个额外的分支和损失函数扩展现有的Siamese跟踪器来实现。
我们通过一个简单的两层神经网络 h ϕ h_\phi hϕ和学习参数 ϕ \phi ϕ来预测 w × h w\times h w×h的二元masks(每个RoW都有一个)。用 m n m_n mn表示预测的mask,对应着第 n n n个RoW。
m n = h ϕ ( g θ n ( z , x ) ) m_n = h_\phi (g_\theta ^n (z,x)) mn=hϕ(gθn(z,x))
从上述等式,我们可以发现mask的预测是一个函数,此函数由用于分割 x x x的图像和 z z z中的目标物体组成。这样, z z z可以引导分割的过程,这样任意类别的物体都可被追踪到。这就很清楚地表明,给定一个图像 z z z,网络就可对 x x x生成一个不同的分割mask。
Loss Function
在训练过程中,每一个RoW都标注有一个真值二元标签 y n ∈ { ± 1 } y_n \in \{\pm 1\} yn∈{±1},以及一个像素级的真值 mask c n c_n cn,大小是 w × h w\times h w×h。让 c n i j ∈ { ± 1 } c_n^{ij}\in \{\pm 1\} cnij∈{±1}表示第n个RoW物体mask里的像素点KaTeX parse error: Can't use function '\(' in math mode at position 1: \̲(̲i,j\)的对应标签。损失函数 L m a s k L_{mask} Lmask是一个覆盖所有RoWs的二元logistic回归损失:
L m a s k ( θ , ϕ ) = ∑ n ( 1 + y n 2 w h ∑ i j l o g ( 1 + e − c n i j m n i j ) . L_{mask}(\theta, \phi) = \sum_n (\frac{1+y_n}{2wh}\sum_{ij} log(1+ e^{-c_n ^{ij} m_n^{ij}}). Lmask(θ,ϕ)=n∑(2wh1+ynij∑log(1+e−cnijmnij).
因此, h ϕ h_\phi hϕ的分类层有 w × h w\times h w×h个分类器,每一个表示某像素点是否属于候选框内的物体。注意, L m a s k L_{mask} Lmask仅针对正的RoWs考虑(即 y n = 1 y_n=1 yn=1)。
Mask Representation
与语义分割方法如 a-la FCN和 Mask R-CNN不同,它们在整个网络上保留明显的空间信息,而我们则由一个平面的物体特征来产生 masks。尤其,这个特征对应着一个 1 × 1 × 256 1\times 1\times 256 1×1×256的RoW,此RoW由 f θ ( z ) f_\theta (z) fθ(z)和 f θ ( x ) f_\theta (x) fθ(x)之间的 depth-wise cross-correlation 产生。分割任务中的 h θ h_\theta hθ网络有两个 1 × 1 1\times 1 1×1的卷积层组成,一个有256通道,另一个有 6 3 2 63^2 632个通道。这允许每一个像素分类利用整个RoW内的信息,因此对 x x x内的候选窗口有着更全面的了解,这可以消除那些与目标物体类似的对象所造成的影响。为了产生更加准确的物体masks,我们将低分辨率和高分辨率的特征融合起来,通过多个由上采样层和 skip connections构成的 refinement 模块实现。
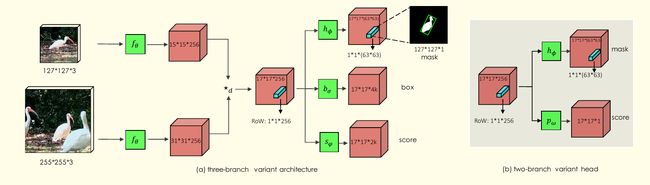
Two Variants
对于我们的实验,我们增强了SiamFC和SiamRPN的结构,通过分割分支和损失函数 L m a s k L_{mask} Lmask,得到了两个SiamMask的 two-branch 和 three-branch 变体。它们分别优化多任务损失函数 L 2 B L_{2B} L2B和 L 3 B L_{3B} L3B:
L 2 B = λ 1 ⋅ L m a s k + λ 2 ⋅ L s i m L_{2B} = \lambda_1 \cdot L_{mask} + \lambda_2 \cdot L_{sim} L2B=λ1⋅Lmask+λ2⋅Lsim
L 3 B = λ 1 ⋅ L m a s k + λ 2 ⋅ L s c o r e + λ 3 ⋅ L b o x L_{3B} = \lambda_1 \cdot L_{mask} + \lambda_2 \cdot L_{score} + \lambda_3 \cdot L_{box} L3B=λ1⋅Lmask+λ2⋅Lscore+λ3⋅Lbox
对于 L 3 B L_{3B} L3B,如果RoW的一个 anchor box与真值边框的IOU大于等于0.6,那么它被认为正的( y n = 1 y_n = 1 yn=1),否则就是负的( y n = − 1 y_n = -1 yn=−1)。超参数 λ 1 = 32 , λ 2 = λ 3 = 1 \lambda_1=32, \lambda_2=\lambda_3=1 λ1=32,λ2=λ3=1。针对边框和置信度的输出分支由两个 1 × 1 1\times 1 1×1的卷积层组成。图2是两个SiamMask的变体。
Box Generation
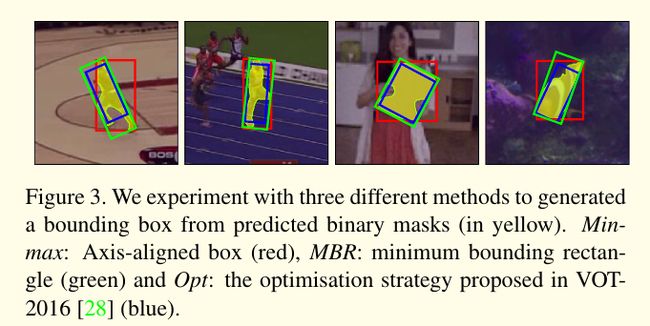
注意,VOS benchmarks需要二元masks,通常追踪benchmarks如VOT需要一个边框作为目标物体最终的呈现。我们考虑了3个不同的策略来从二元mask上产生物体边框:
- axis-aligned 边框(Min-max)
- rotated minimum 边框(MBR)
- 用于VOT-2016的自动边框生成的优化策略(Opt)
3.3 实现细节
网络结构
对于变体,我们使用了Res-50一直到主干网络 f θ f_\theta fθ第四阶段最后的卷积层。为了在较深的层获得较高的空间分辨率,我们通过步长为1的卷积降低输出步长至8。而且,我们通过膨胀卷积增加了感受野。在我们的模型中,我们在共用的主干网络 f θ f_\theta fθ上增加了一个非共享的调节层( 1 × 1 1\times 1 1×1卷积,256个输出)。为了简洁,我们在等式1中省略了它。
训练
和SiamFC类似,我们使用的样例图片为 127 × 127 127\times 127 127×127,搜索图片为 255 × 255 255\times 255 255×255。在训练过程中,我们随机调换样例和搜索图片。特别地,我们对图片采取了随机变换( ± 8 \pm 8 ±8)和改变大小(对样例图片 2 ± 1 / 8 2^{\pm 1/8} 2±1/8,对搜索图片 2 ± 1 / 4 2^{\pm 1/4} 2±1/4)的方式。
网络主干在ImangeNet-1k上进行预训练。我们使用SGD以及一个warmup阶段,即在前五个epochs上学习率开始从 1 0 − 3 10^{-3} 10−3增加到 5 × 1 0 − 3 5\times 10^{-3} 5×10−3,然后在接下来的15个epochs上对数降低至 5 × 1 0 − 4 5\times 10^{-4} 5×10−4。我们用COCO, ImageNet-VID和YouTube-VOS来训练所有的模型。
推理
在追踪时,SiamMask 每一帧评估一次,不作任何改变。在两个变体上,我们通过坐标选择输出的mask,该坐标可以得到分类分支上的最高得分。然后,通过逐个像素点的 sigmoid计算,我们对mask 分支输出进行二值化,阈值设为0.5。对于two-branch变体,在第一帧后的每一帧,我们将输出mask用Min-max边框进行调节,然后用它来裁剪下一帧的搜索区域。然而,在three-branch变体,我们发现边框分支上最高置信度的输出是最有效的。
SiamMask是用PyTorch实现的。代码和预训练模型很快将被放出来。
4. 实验
Pls read paper for more details.