KMP算法实现原理
KMP算法,是由Knuth,Morris,Pratt共同提出的模式匹配算法,其对于任何模式和目标序列,都可以在线性时间内完成匹配查找,而不会发生退化,是一个非常优秀的模
式匹配算法。其算法的主要功能就是寻找在给定的母串中寻找是否含有一个给定的连续字符串。下面举个例子,如图一所示:
图一:

我们需要在上面的目标串中寻找是否存在一个ABCDABD的字串,在这里我们将图一的长串称为目标串,短串叫做搜索串。图一示例了一般的寻找过程:我们从第一个字符
串开始寻找,如果第一个字符串不匹配,我们就继续检查下一个字符串是否匹配,如图2所示:
图二:

但是假设我们如果在目标串中找到了部分匹配字符,如下图所示:
图三:
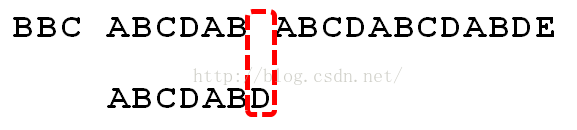
从上图可以看出只有D字符与上面的目标串不一样,遇到这样的情况,如果我们还是将比较串向后移动一位的话,那么我们之前的ABCDAB就会重复搜索,这样效率就会降
低。当我们确定D不匹配时,前面6个字符是匹配的,那么我们可不可以利用这个信息来避免将搜索串一位一位向右移动以期待寻找在目标串中和搜索串第一个字符匹配的位
置,因为要确定搜索串是否存在于目标串中的第一步就是要找到两个字符串的公共字符,在上述的例子中就是字符A。那么为了解决这个问题,Knuth,Morris,Pratt利用一张
表来存放一个叫部分匹配值的数组,如下:
图四:

这个表的得到方法我们暂且不讨论,上表是基于“前缀”和“后缀”这两个概念,“前缀”是除了最后一个字符串意外,从第一个字符串开始长度依次递增1的字符串序列;“后
缀”则刚好相反;一下是前缀串和后缀串集合的产生过程:
图五:

那么知道了部分匹配数组是怎么来的,它的作用究竟是什么?在写博客之前,看过不少的人写文章来分析这个算法,但是觉得写得好的可能只有
http://www.ruanyifeng.com/blog/2013/05/Knuth–Morris–Pratt_algorithm.html,这篇博客很详细的介绍了算法的原理和部分匹配值数组的来历。下面就结合这篇博客和个人理解
来说说部分匹配值数组的作用。对于这种问题,我们一般的解决方案是将搜索串ABCDABD相对于目标串向右一位一位地移动,如果找在目标串中找到一个和搜索串的第一个字
符A相等的位置的话,我们会暂停将搜索串继续向右移动,而是继续比较它们的第二个字符串B,如果搜索串从头到尾都存在于目标串中,那么算法结束,否则继续将搜索串向右
移动。但在图三所示的情况,如果继续将搜索串向右一位一位移动以期待寻找在目标串中和搜索串第一个字符匹配的位置(因为要确定搜索串是否存在于目标串中的第一步就是
要找到两个字符串的公共字符)的话效率很低。为了确定搜索串的第一个字符在目标串的下一次出现位置(在常规的算法中,我们向右一位一位移动搜索串就是认为它们的公共字
符A在下一个位置出现),我们利用部分匹配值表来标记。还是上面的例子,我么匹配到D的时候失败了,但ABCDAB这些是匹配的,那么从部分匹配值表中可以知道,ABCDAB
这个符串中最后匹配位B的值为2,然后搜索串向后移动的位数=当前匹配的位数(6)-最后匹配字符的部分匹配值(B,2),这是什么意思????结合前面的前缀和后缀来看,2代表在
ABCDAB中,从第一个字符A开始与包含最后一个字符B为止的所有字符串集合中,它们所形成的最大公共子符串长度为2.移动的位数(4)=当前匹配的位数(6)-最后匹配字符的部
分匹配值(B,2)这个公式就代表将搜索串向后移动4个位置后又可以使目标串和搜索串的第一个字符相等(这样我们就可以后续的比较)。下面就用一张图来解释:

我们可以看到左右方框的字符长度相等且内容相等,那么将左边方框子符串向右移动(黑色区域的总长-方框字符长度)个单位后,就会重合。重合的位置的起点刚好是搜索串
的起点,这个起点的位置也是下一次搜索串的首字符和目标串当前位置相等的字符。所以现在关键的任务是求出部分匹配值表!!!!!
算法实现(c++):
vectorget_partial_match_table(string &s){
int size = s.size(),pre;
vectortab(size,0);
if (size == 1)return tab;
if (s[0] == s[1])tab[1] = 1;
else tab[1] = 0;
for (int i = 2; i < size;i++){
if (s[i] == s[tab[i - 1]])tab[i] = tab[i - 1] + 1;
else{
if (s[i] == s[0])tab[i] = 1;
}
}
return tab;
} 算法利用动态规划方法。一开始我么将表的所有元素都置为0,我们还是用ABCDABD为例子:
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| char | A | B | C | D | A | B | D |
| value | 0 | 0 | 0 | 0 | 1 | 2 | 0 |
A,AB,ABC,ABCD
它的后缀集合是:
A,DA,CDA,BCDA,因为有一个A是一样的,所以tab[4]=1;
如果这时候我们把B(i=5)加进来,那么对于前缀来说就是增加了一项ABCDA,那么现在的前缀变成:
A,AB,ABC,ABCD,ABCDA;
后缀变成:
B,AB,DAB,CDAB,BCDAB;
那么他们的公共最长字符串就是AB,所以tab[5]=2;
总结来说就是:如果第i-1项的值为n,可以知道截止到第i-1位为止,它们的公共字符串长度为n,那么在新形成的后缀集
合中所有的字串的后面都加第i个字符,且增加一个以第i个字符单个形成的子集(以上面的字符B为例子),在新形成的前缀结
合中增加一个ABCDA即可。
下面是完整代码:
#include
#include
#include 测试用例:
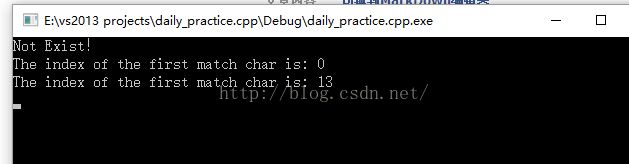
BBBBBBBBBBBB
AAAA
BBBBBB
BB
BBCABCDABABCDABCDABDE
ABCDABD