自学Python之Python基础:(四)Python多线程
转载的老板请注明出处:http://blog.csdn.net/cc_xz/article/details/78689998万分感谢!
在本篇中,你将了解到:
1.多线程和多进程的基本概念。
2.一些常用的线程锁。
3.如何实现线程间通信。
4.Python的进程和进程池。
多线程/进程的基本概念:
Python是运行在Python虚拟机种,而创建的多线程只是在Python虚拟机中的虚拟线程,而不是在操作系统中的真正的线程。也就是说,Python中的多线程,是由Python虚拟机来进行轮询调度,而不是操作系统。这极大的降低了Python多线程的可用性。
多线程可以使同程序同时执行多个任务。线程在执行过程中与进程存在区别,在每个独立的线程中,都分别存在程序运行的入口、顺序执行序列以及程序的出口。并且线程必须依附在某个程序中,由程序来控制多个线程的运行。
线程的基本操作:
线程具有5种状态,状态转换的过程如下:
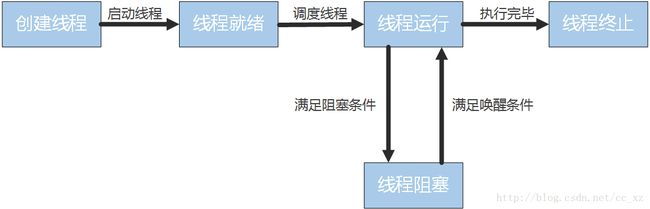
而线程和进程都是操作系统控制程序运行的基本单位,系统可以利用这两个特性对程序实现高并发。而线程和进程的主要区别如下:
1、一个程序至少有一个进程;一个进程中至少包含一个线程。
2、进程在内存中拥有独立的存储空间,而多个线程则共享它所依赖的进程的存储空间。
3、进程和线程对操作系统的资源管理的方式不同。
3.1、由于多个线程共享一个进程的存储空间(内存地址),也就是说多个线程是共享堆栈和局部变量的。即:多个线程只是一个进程中不同的执行路径(例如由多个线程执行同一个类),所以在进程中,一个线程崩溃就等于整个进程都崩溃掉了(共享一个存储空间)。
3.2、而由于进程具有独立的存储空间,所以当一个进程崩溃后,如果此进程没有其他交互式操作,是不会对其他进程产生影响的。(例如A进程负责读取,B进程负责写入,B进程所写入的数据是由A进程提供的,当A进程崩溃后,B进程没有正确的数据源,这就是影响到了B进程。而当B进程崩溃后,由于A进程是提供数据的,它无需考虑关于写入的问题,所以对A进程不会产生影响。)
而Python多线程的问题在于GIL的存在。在CPython(使用最广泛的Python解释器)中,GIL是一个全局线程锁。即:在解释器执行任何代码时,都必须获得这把锁。所以虽然CPython的线程库是直接封装了操作系统的原生线程/进程,但CPython的线程/进程作为一个整体,同一时间只能有一个线程运行在解释器中,而其他线程都处于等待着GIL将锁释放。
使用_thread模块创建线程:
Python中的多线程有两种使用方法,使用函数或用类包装线程对象。例如:
import _thread
import time
def print_time(threadName, delay):
count = 0
while count < 5: # 每个线程执行5次。
time.sleep(delay) # 给线程延时
count += 1 # 线程没执行一次,就记录一次。
print(threadName,
time.ctime(time.time())) # 分别输出线程名称和当前时间。
def start_thread():
"""
调用_thread库创建两个线程,第一个参数为该线程所需实现的功能,将函数做为参数。
值得注意的是:
当调用一个函数时,函数后带有括号,表示调用函数执行后返回的结果(return)
当调用函数不带有括号时,则表示调用这个函数本身。
接着分别输入线程名称和执行线程时延时的时间。注意,这两个参数仍然会被print_time获得并调用。
"""
_thread.start_new_thread(print_time, ("Thread-1", 1))
_thread.start_new_thread(print_time, ("Thread-2", 3))
start_thread()
time.sleep(30) # 主线程延时30秒,否则主线程迅速结束,子线程自然被销毁。输出结果为:
Thread-1 Tue Oct 10 18:29:52 2017
Thread-1 Tue Oct 10 18:29:53 2017
Thread-1 Tue Oct 10 18:29:54 2017
Thread-2 Tue Oct 10 18:29:54 2017
Thread-1 Tue Oct 10 18:29:55 2017
Thread-1 Tue Oct 10 18:29:56 2017
Thread-2 Tue Oct 10 18:29:57 2017
Thread-2 Tue Oct 10 18:30:00 2017
Thread-2 Tue Oct 10 18:30:03 2017
Thread-2 Tue Oct 10 18:30:06 2017
使用Threading模块创建线程:
使用Threading模块创建线程,直接从threading.Thread继承,然后重写__init__方法和run方法即可:
import time
import threading
"""
*threading.Thread* 新建一个类,继承自threading.Thread类,通过该类创建多线程。
"""
class MyThread(threading.Thread):
"""
*threadID* 在初始化MyThread对象时,为新线程(对象)指定的ID号。
*name* 同理,为新线程(对象)指定的名称。
*counter* 在线程运行时,使用延时来模拟线程工作,定义每次线程执行延时多久,单位是秒。
"""
def __init__(self, threadID, name, counter):
# 调用父类的初始化方法,将子类(自身)作为参数。
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.counter = counter
"""
重写父类的方法,启动新线程时将执行此方法,并且线程执行何种任务需要在此方法中定义。
现有新线程分别在开始运行和结束运行时输出当前线程名称。
另外,执行自定义的print_time()方法。
"""
def run(self):
print("Starting " + self.name)
self.print_time(self.name, self.counter, 3)
print("Exiting " + self.name)
"""
print_time()方法是线程实际执行的任务。
*threadName* 自定义的当前线程名称。
*delay* 线程延时秒数。
*counter* 线程执行次数。
while用于循环执行线程,当counter的值大于0时,则一直循环线程。而每次循环结束后,都将counter的值减1。
在执行过程中进行延时和输出当前时间。
"""
def print_time(self, threadName, delay, counter):
while counter:
time.sleep(delay)
print(threadName, time.ctime(time.time()))
counter -= 1
# 创建对象
thread1 = MyThread(1, "Thread-1", 1)
thread2 = MyThread(2, "Thread-2", 2)
# 启动新线程。
thread1.start()
thread2.start()
# 同直接调用_thread不同,继承自threading.Thread的子类,可以在主线程结束后继续执行。
print("退出主线程")输出结果为:
Starting Thread-1
Starting Thread-2
退出主线程
Thread-1 Wed Oct 11 12:30:02 2017
Thread-2 Wed Oct 11 12:30:03 2017
Thread-1 Wed Oct 11 12:30:03 2017
Thread-1 Wed Oct 11 12:30:04 2017
Exiting Thread-1
Thread-2 Wed Oct 11 12:30:05 2017
Thread-2 Wed Oct 11 12:30:07 2017
Exiting Thread-2
线程锁:
使用多线程的好处是,当你开启多个任务后,在宏观上看来,这些任务是同时执行的。但是由于多线程是共享其所属进程的存储空间,这就产生了数据共享的问题。例如:
当多个线程同时访问一个资源时,就会发生竞争,这是因为当一个文件被A线程打开并进行持续修改,这事如果被线程B打开,B线程看到的文件将是不完成的(A线程还没有修改完毕),若此时B线程再对文件进行修改,就会造成异常。所以当同一个文件在同一时间只能由一个线程来打开或修改,这便叫线程锁。
线程锁有两种状态,锁定和未锁定。当一个线程需要访问一个公共变量时,就必须获得这个变量的锁(提前定义),当变量被其他线程占用时(锁定状态),即将访问这个变量的进程就进入同步阻塞状态,只有等待其他线程释放锁时,此线程才会被唤醒。
同步是用于控制不同线程之间的进行的操作顺序。而通信是指线程之间如何传递信息,在Python中实现同步最简单的方式是使用“锁”的机制。实现通信的简单方案是使用“Event”。
为了避免这种情况,需要在线程进入临界区时加锁。
临界资源:
临界资源是一次仅允许一个进程、线程使用的共享资源,各进程线程之间采用互斥的方式来使用的资源被称为临界资源。典型的临界资源如:打印机、变量、数组等。
临界区:
每个线程中访问临界资源的那段代码称为 临 界 区 ,每次只允许一个线程进入临界区,在当前线程没有释放之前,不允许其他线程再次进入。
如果有多个线程试图同时访问临界区,那么在有一个线程进入后其他试图访问临界区的线程都将被挂起,并一直持续到已经进入临界区的线程离开。临界区被释放后,其他线程可以继续抢占,并以此达到共享资源的目的。使用临界区时,一般不允许其运行时间过长,若有多个试图进入临界区的线程被挂起,将影响程序的运行性能。
线程与锁交互流程示意图::
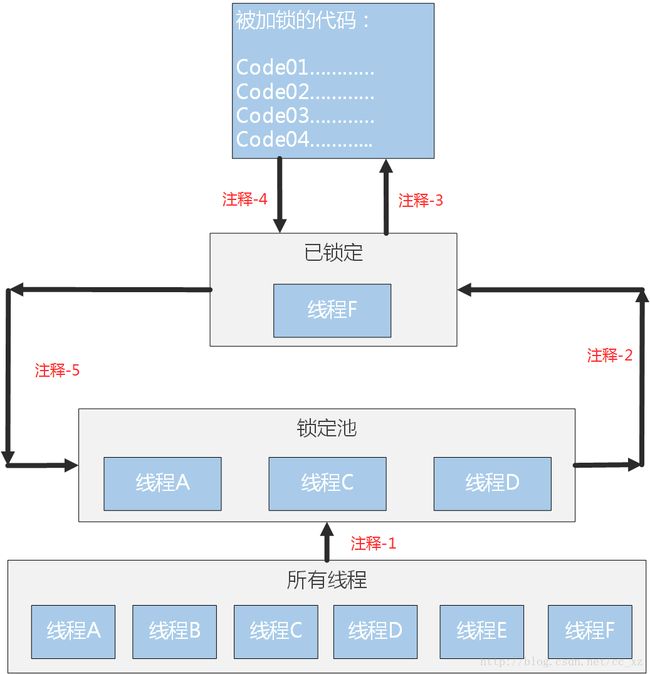
在上图中的注释如下:
注释-1:
在使用多线程时,如果对特定的代码加锁,那么此段代码同时只能有一个线程对其进行操作。在上述概念图中,一共有6个线程,在这些线程中如果需要对加锁代码进行访问,则需要进入到锁定池中,通过Python解释器进行调度。
注释-2:
当多个线程全部进入锁定池后, 这些线程都将处于阻塞状态,直到Python解释器将其设置为已锁定状态,才可以对加锁代码进行操作。
注释-3:
当某个线程进入已锁定状态后,对加锁代码进行操作,但在同一段加锁代码中,同时只能有一个线程为已锁定状态(操作)。
注释-4:
当代码执行一次后,将根据实际部署的代码决定此线程是否重新执行代码,若需要再次执行,则执行注释3中的步骤,若无需执行,或需要其他线程执行,则执行注释5中的步骤。
注释-5:
当当前的已锁定线程对加锁代码完成操作后,由Python解释器解除其已加锁状态,并根据实际代码决定该线程是否进入锁定池中。同时将根据实际情况重复注释2中的步骤。
指令锁-Lock():
Lock(指令锁)是Python中提供的最低级的锁,Lock包含两种状态—锁定和非锁定。可以理解为Lock维护着一个锁定池,当线程请求锁定时,就将该线程放置到锁定池中(此时未锁定);当当前已被锁定的线程执行完毕后,将解除锁定状态;这时锁定池中的其他线程,将有GIL调度,选择一个进程将其设置为锁定状态;直至锁定池中没有其他线程。
import threading
import time
lock = threading.Lock()
def func(name): # 从方法将被不同的线程调用。
# 当输出此项时,表示线程已开始执行func()函数。
print('%s 是当前获取Lock的线程...' % name)
# 使用lock.acquire()将以下的代码锁定,使其同时只能一个线程进入。将后续尝试进入此段代码的线程阻塞。
# 由此行代码开始,所有试图继续访问下述代码的线程,都将进入锁定池中。往往第一个访问到此处的线程,则更优先的进入锁定状态。
lock.acquire()
print('%s 进入已锁定状态。' % name) # 输出当前进入Lock(指令锁)中的线程名称。
time.sleep(1) # 模拟函数中所执行的代码。
print('%s 解除已锁定状态,现在其他线程可以执行上述代码啦...' % name) # 输出即将推出Lock中的线程名称。
# 释放Lock(指令锁),但在释放Lock的代码前,必须有.acquire()表示上述代码已被锁定。否则将报出异常。
lock.release()
thread01 = threading.Thread(target=func, args=("thread01",))
thread02 = threading.Thread(target=func, args=("thread02",))
thread03 = threading.Thread(target=func, args=("thread03",))
thread01.start()
thread02.start()
thread03.start()输出结果为:
Output
可重入线程锁-RLock():
在threading模块中定义了多种类型的锁,其中的Lock和RLock。他们之间的区别是,RLock允许在同一个线程中被多次acquire(创建线程锁),当然,acquire和release必须成对出现,即:调用了几次acquire就必须调用release才能真正的释放被“锁住”的代码。而Lock则不允许连续(一个acquire后必须是release)出现acquire,否则将出现死锁。
可以认为RLock包含一个锁定池和一个初始值为0的计数器,每次成功调用 acquire()/release(),计数器将+1/-1,为0时锁处于未锁定状态。
import threading
import time
RLock = threading.RLock() #获取RLock()对象
def CriticalResource(threadName):#此方法用于模拟实际操作,例如代码中,是将一段字符串打印到屏幕中。
for name in threadName: #将字符串分别取出后打印。
time.sleep(0.2) #延时操作
print(name,end=' ') #打印后将默认的“\n”换行符改成空格。
class Thread(threading.Thread): #多线程类。
def __init__(self,threadName,counter): #在创建多线程(初始化)时,需要给出线程名称和线程执行的次数。
threading.Thread.__init__(self) #初始化父类,相当于Java中的Super方法。
self.ThreadName = threadName #创建两个变量,将__init__中的局部变量赋值给Thread类中新创建的全局变量。
self.Counter = counter
print("启动新线程-->",self.ThreadName)
def run(self): #此方法是重写父类的,当启动线程后,将执行该方法中的代码。
RLock.acquire() #此时获得第一把递归锁,从此行代码开始,后续的代码同时只能有一个线程访问。
while self.Counter: #创建一个循环,只要Counter中的值不为0时,将持续循环。
RLock.acquire() #此时获取第二把递归锁。
CriticalResource(self.ThreadName) #调用实际执行的方法。
RLock.release() #释放第一把递归锁。
self.Counter -= 1 #每执行一次循环,则将Counter的值减1。
RLock.release() #释放第二把递归锁,从此行开始,后续的代码可以同时由多个线程访问。”
print(self.ThreadName,"执行完毕。")
#分别使用Thread类创建多个新线程。之后使用start()方法将线程启动。
Thread01 = Thread("Thread01",2)
Thread02 = Thread("Thread02",2)
Thread03 = Thread("Thread03",2)
Thread01.start()
Thread02.start()
Thread03.start()输出结果为:
启动新线程--> Thread01
启动新线程--> Thread02
启动新线程--> Thread03
T h r e a d 0 1 T h r e a d 0 1 Thread01 执行完毕。
T h r e a d 0 3 T h r e a d 0 3 Thread03 执行完毕。
T h r e a d 0 2 T h r e a d 0 2 Thread02 执行完毕。在上述代码中,如果不添加全局解释器锁部分的代码,输出结果则为:
启动新线程--> Thread01
启动新线程--> Thread02
启动新线程--> Thread03
T T T h h h r r r e e e a a a d d d 0 0 0 1 2 3 T T T h h h r r r e e e a a a d d d 0 0 0 3 Thread03 执行完毕。
1 Thread01 执行完毕。
2 Thread02 执行完毕。
信号量-Semaphore():
Semaphore(信号量)管理一个内置的计数器,每当调用acquire()函数时,给计数器的值”-1”,调用release()时,给计数器的值”+1”。而计数器的值不能小于0,这是因为,当计数器的值为0时,acquire()函数将当前线程阻塞,直到其他线程调用release()。
而基于Semaphore的BoundeSemaphore,会在每次调用release()时检查计数器的值是否超过了计数器的初始值,如果超过,则抛出一个异常。
import threading
import time
# 创建Semaphore()信号量函数,它接受一个int类型的参数,该参数表明了同时可以有多少个线程访问临界区。
# 现实中的打印机,在打印队列中可能会有大于1个的文件等待打印,但正在打印的文件只能有一个,否则将会把多个文件中的内容打印到一篇中。
# 而printer()函数模拟了打印机的功能,它允许同时打印两篇文章,于是出现了将内容打印到一起的问题。
# 但这种情况同不加锁的情况不一样,在第三个需要打印的文章被放到队列中等待了。
Semaphore = threading.Semaphore(2)
def printer(name, file):
print("[{0}]所打印的文件已进入打印机队列中.....".format(name))
Semaphore.acquire()
print("开始打印[{0}]的文档:".format(name))
for x in file:
time.sleep(0.1) # 对打印操作进行延时,否则由于操作时间太短,无法体现出效果。
print(x, end=" ")
print("\n")
# 当前两个线程执行了第一个acquire()时,Semaphore计数器中的值已经为0,再次执行acquire()值小于0,所有正在进行的线程都被阻塞了。
Semaphore.acquire()
print("[{0}]的文档打印结束:\n".format(name))
Semaphore.release()
ThreadA = threading.Thread(target=printer, args=["王大锤", "你好我是王大锤"])
ThreadB = threading.Thread(target=printer, args=["王二锤", "你好我是王二锤"])
ThreadC = threading.Thread(target=printer, args=["王三锤", "你好我是王三锤"])
ThreadA.start()
ThreadB.start()
ThreadC.start()输出结果为:
[王大锤]所打印的文件已进入打印机队列中.....
开始打印[王大锤]的文档:
[王二锤]所打印的文件已进入打印机队列中.....
开始打印[王二锤]的文档:
[王三锤]所打印的文件已进入打印机队列中.....
你 你 好 好 我 我 是 是 王 王 大 二 锤
锤
条件延迟锁-Condition():
上述的两种锁都可以完成线程同步的目的,但在一些比较复杂的环境中,可能还需要对当前的线程锁进行一些条件判断。在使用Condition对象可以在某些触发性事件或达到特定条件后才开始执行线程(线程将通信)。这是因为Condition对象除了具有acquire()(获取)函数和release()(释放)函数外,还提供了wait()(阻塞)和notify()(唤醒)函数。
Condition条件变量锁通常需要关联多个线程,从而可以统一的对线程的执行阻塞或唤醒。也就是说,Condition会维护一个等待池,根据实际的代码控制,将不同的线程放入等待池中进行等待(被阻塞。)
import threading, time
# 分别创建两个多线程类,并且各自初始化,但要注意的是,两个多线程类接收一个Condition()对象。从而实现两个线程间的同步以及线程等待。
"""
两个run()函数中代码执行顺序以及含义如下:
test01-01:首先进行延时操作,错开两个线程(现在还未进行线程同步)的执行时间,先执行test02线程。
test02-01:使用condition对象开启线程中的test02线程中的线程锁。注意,只有开启线同步(锁)才能实现线程等待(wait和notify)功能。
但本案例中两个多线程类只分别对应一个线程,若每个线程类对应多个线程(创建多个对象)则可以体现出线程锁的功能,本案例着重同步及等待。
test02-02:此时调用wait()函数,阻塞当前线程,由于线程同步,所以当前test02线程进入睡眠状态,等待其他线程执行notify()将其唤醒。
test01-02:同样使用condition对象(同test02线程使用的是同一个线程锁)开启test01的线程锁(同步)。
test01-03:输出定义好的内容。
test01-04:使用notify()将已睡眠的线程唤醒,即此时test02线程可以继续执行。
test01-05:在唤醒其他线程后,test01线程将进入睡眠状态。
test02-03:在test02线程被唤醒后,输出定义好的内容。
test02-04:之后唤醒已睡眠的test01线程。
test02-05:接着使用wait()使本线程进入睡眠状态。
.....
后续的操作皆为可执行的线程输出文本信息,唤醒其他已睡眠的线程,再使本线程进入睡眠状态。如此循环。
这样可实现的效果则是,明明可以异步执行的两个线程,在同步执行的过程中,还不断的唤醒对方线程,阻塞本线程。从而实现两个线程好像一个线程一样的执行。
"""
class test01(threading.Thread):
def __init__(self, cond):
super(test01, self).__init__()
self.cond = cond
def run(self):
time.sleep(0.5) # test01-01
# 需要注意的是,在两个run()中都要先执行acquire()函数开启线程同步,然后才可以执行wait()(睡眠)和notify()(唤醒)操作。
self.cond.acquire() # test01-02
print("我说你好!") # test01-03
self.cond.notify() # test01-04
self.cond.wait() # test01-05
print("你不问候我吗?")
self.cond.notify()
self.cond.wait()
print("是的我也好。")
self.cond.notify()
self.cond.release()
class test02(threading.Thread):
def __init__(self, cond):
super(test02, self).__init__()
self.cond = cond
def run(self):
self.cond.acquire() # test02-01
self.cond.wait() # test02-02
print("好的谢谢!") # test02-03
self.cond.notify() # test02-04
self.cond.wait() # test02-05
print("好的,你也好吗?")
self.cond.notify()
self.cond.wait()
print("无聊的对话。")
self.cond.notify()
self.cond.release()
#另外,两个线程使用的是同一个condition对象,若分别使用不同的条件延迟锁,则无法实现目标功能(各锁个的将毫无意义)。
condition = threading.Condition()
test01 = test01(condition)
test02 = test02(condition)
test01.start()
test02.start()输出结果为:
我说你好!
好的谢谢!
你不问候我吗?
好的,你也好吗?
是的我也好。
无聊的对话。在上述的代码中,Condition所提供的新函数含义如下:
wait():调用这个函数将使当前线程进入等待池中进行等待,并释放当前已获得的锁“已锁定”。但使用此函数前,对应的线程必须处于已锁定状态,否则将报出异常。
notify():调用此函数后,将从等待池中选出一个当前被阻塞线程,为其调用acquire()函数并尝试获得锁定(进入锁定池);此函数只对一个线程生效。
另外,由于notify()函数不会释放当前已锁定的线程,所以必须在其他线程中(当前已锁定的线程)释放锁定状态。
notifyAll():同notify()不同的是,notifyAll()会通知等待池中所有的线程,使这些线程全部进入到锁定池中尝试获得锁定。
延时启动函数-Timer():
import threading
# 通过Timer所执行的函数。
def printer(name):
print("[{0}]调用了printer()函数.....".format(name))
# 每个线程要执行的函数。
def timer(name,time):
# Timer(定时器)是Thread的派生类,用于在指定时间后调用一个方法,它接受两个参数:
# 首先指定在多久后调用目标函数,然后定义要调用哪个函数。
Timer = threading.Timer(time,printer,args=[name])
# 可以通过Timer中的run()函数启动Timer,也可以调用Thread中的start()函数启动Timer。
Timer.run()
ThreadA = threading.Thread(target=timer,args=["王大锤",1])
ThreadB = threading.Thread(target=timer,args=["王二锤",3])
ThreadC = threading.Thread(target=timer,args=["王三锤",5])
ThreadA.start()
ThreadB.start()
ThreadC.start()输出结果为:
[王大锤]调用了printer()函数.....
[王二锤]调用了printer()函数.....
[王三锤]调用了printer()函数.....
线程间通信:
但使用多线程可能会出现一种尴尬的情况,例如:在程序中创建了一个List,但默认此List为空,而线程A负责对List填充数据,线程B负责获取List中的数据。但很可能会出现线程A还没来得及进行数据填充,而线程B就开始获取数据了,这种时候往往需要报出一个异常。在7.2.3.中的代码和这个例子有些相似,但采用锁的方式会使代码非常臃肿。因为线程B根本不知道何时才是获取数据的最佳时机。而实现线程间的通信,则可以解决这个问题。
Queue对象使线程通信
如果程序中存在多个线程,那么这些线程则不可避免的会相互通信(传输数据)。从一个线程向另一个线程发送数据可以使用队列(queue)来完成,而且有queue库来完成,它是线程安全的队列。
from threading import Thread
from queue import Queue # 导入线程安全的队列。
def write(queue):
queue.put(("第一段", "第二段", "第三段")) # put()为用于写入数据的函数,可以接受元组、列表、字典、字符串等。
def read(queue):
for v in queue.get(): # get()为获取queue中的数据,使用for进行迭代。(对get()获取到的元组进行迭代)
print(v)
queue = Queue() # 初始化队列对象。
"""
创建两个多线程实例。
target是定义需要该线程执行的函数,args定义需执行的函数的参数。以元组的类型添加。
"""
writeThread = Thread(target=write, args=(queue,))
readThread = Thread(target=read, args=(queue,))
writeThread.start() # 先执行写入函数。
readThread.start() # 再执行读取函数。输出结果为:
第一段
第二段
第三段
Python进程:
Python中的多线程并无法充分利用多核CPU的资源,如果希望充分利用多核CPU,则需要使用多进程。Python提供了multiprocessing包,只需要定义一个函数,则可以完成多线程工作。
使用Process创建子进程
# Process:用于创建多进程的类。
# cpu_count:查看CPU核心数。
# active_children:查看当前的子进程,返回一个列表,其中包含子进程的名字。
from multiprocessing import Process, cpu_count, active_children
import time
def worker(interval, name): # 创建一个函数,用于子线程的执行。
print(name + '【start】')
time.sleep(interval)
print(name + '【end】')
# 如果希望创建子进程,则必须在主进程中创建。
if __name__ == "__main__":
process01 = Process(target=worker, args=(1, "第1个进程"), name="大锤")
process02 = Process(target=worker, args=(2, "第2个进程"))
process03 = Process(target=worker, args=(3, "第3个进程"))
process01.start()
process02.start()
process03.start()
print("CPU的核心数是:" + str(cpu_count())) # 输出当前CPU的核心数。
for p in active_children(): # 迭代子进程列表。
print("子线程:" + p.name + ",id为:" + str(p.pid)) # 输出当前子进程名称和PID。
print("主线程结束。")输出结果为:
CPU的核心数是:4
子线程:Process-2,id为:9380
子线程:Process-3,id为:428
子线程:大锤,id为:7220
主线程结束。
第1个进程【start】
第2个进程【start】
第3个进程【start】
第1个进程【end】
第2个进程【end】
第3个进程【end】
使用类创建进程
from multiprocessing import Process, cpu_count, active_children
import time
class MyProcess(Process):
def __init__(self, interval, name):
super(MyProcess, self).__init__()
self.interval = interval
self.name = name
def run(self):
print(self.name + '【start】')
time.sleep(self.interval)
print(self.name + '【end】')
if __name__ == "__main__":
process01 = MyProcess(2, "王大锤")
process02 = MyProcess(2, "王二锤")
process03 = MyProcess(2, "王三锤")
process01.start()
process02.daemon = True # 如果子进程的daemon属性为True,当主进程结束后,子进程也会结束。
print(process01.daemon) # 输出daemon属性,默认为False。
process02.start()
process03.start()
# process03.join() # join()用来阻塞当前进程(主进程),直到调用join()的进程执行完毕后,再继续执行当前进程。
print("CPU的核心数是:" + str(cpu_count()))
for p in active_children():
print("子线程:" + p.name + ",id为:" + str(p.pid))
print("主线程结束。")输出结果为:
False
CPU的核心数是:4
子线程:王大锤,id为:1388
子线程:王三锤,id为:11212
子线程:王二锤,id为:10504
主线程结束。
王大锤【start】
王二锤【start】
王大锤【end】
王二锤【end】
进程池
from multiprocessing import Pool
import time, os, random
def longTimeTask(name): # 用于进程执行的函数。
print("进程名称为:{0},进程的PID为:{1}".format(name, os.getpid()))
startTime = time.time() # 定义进程开始时间。
time.sleep(random.randint(1, 5)) # 在进程中进行延时操作。
endTime = time.time() # 定义进程结束时间。
print("进程{0}运行了{1}秒".format(name, endTime - startTime))
if __name__ == "__main__": # 运行进程时需要通过if判断当前的进程。
print("主进程的PID为:{0}".format(os.getpid())) # 输出当前进程的PID。
processPool = Pool(4) # 使用Pool创建进程池,并定义最大可同时执行多少的进程。
for x in range(20): # 由于同时只能存在4个进程,但程序一共会生成20个进程,所以会同时执行4个进程,当进程结束后,再开始执行新进程。
processPool.apply_async(longTimeTask, args=(x,)) # 申请异步进程。
processPool.close() # 关闭进程池,使之不会再有新进程开启。
processPool.join() # 使当前主进程等待所有子进程,在执行完毕后再结束主进程。
print("主进程结束。")输出结果为:
主进程的PID为:8188
进程名称为:0,进程的PID为:8808
进程名称为:1,进程的PID为:8352
进程名称为:2,进程的PID为:7800
进程名称为:3,进程的PID为:6620
进程2运行了1.0000572204589844秒
进程名称为:4,进程的PID为:7800
进程1运行了2.0001144409179688秒
.........省略部分结果..........
进程18运行了5.000285863876343秒
主进程结束。
进程间通信
from multiprocessing import Process, Queue
import time, os, random
def processWrite(queue): # 写入数据的函数。
print("写入进程的PID为:{0}".format(os.getpid()))
for value in ["1", "2", "3", "4"]:
print("写入Queue的值为:{0}".format(value))
queue.put(value) # 在遍历中写入函数。
time.sleep(random.randint(1, 3)) # 进程延时。
# pRead.terminate() # 如果是类函数,则可以调用sele将读取进程强行终止掉。
def processRead(queue):
print("读取进程的PID为:{0}".format(os.getpid()))
"""
在读取时,关键在于,在while循环中会一直试图读取get()。
如果get()不返回任何值(没有新值),程序不会继续执行,也不会报出任何异常。直到出现新值,才会继续执行。
所以如果实现不知道Queue,则可以在写入数据处定义代码,在数据全部写完后,将读取的进程强行终止。
"""
while True:
value = queue.get()
# queue.qsize() # 获取queue剩余的长度。
# queue.empty() # 如果queue已为空,则返回True。
print("从Queue中读取到的值为:{0}".format(value))
if __name__ == "__main__": # 运行进程时需要通过if判断当前的进程。
queue = Queue()
pWrite = Process(target=processWrite, args=(queue,))
pRead = Process(target=processRead, args=(queue,))
pWrite.start()
pRead.start()
pWrite.join()
pRead.terminate() # 在本案例中,在最后强行终止读取进程。输出结果为:
写入进程的PID为:7212
写入Queue的值为:1
读取进程的PID为:3260
从Queue中读取到的值为:1
写入Queue的值为:2
从Queue中读取到的值为:2
写入Queue的值为:3
从Queue中读取到的值为:3
写入Queue的值为:4
从Queue中读取到的值为:4