爬虫介绍02:爬取第一个站点
为了搜刮某个站点,第一步我们需要下载该站包含有用信息的页面,也就是我么尝尝提到的爬取过程。爬站的方式多种多样,我们需要根据目标站点的结构选择合适的爬站方案。下面讨论如何安全的爬站,以及常用的三种方法:
- Crawling a sitemap
- Iterating the database IDs of each web page
- Following web page links
1. 下载一个Web页面
爬取网页前,首先需要下载他们。下面的Python脚本,使用了Python的 urllib2 模块下载一个URL:
import urllib2
def download(url):
return urllib2.urlopen(url).read()这个 download 方法会下载传入的URL指向的页面,并返回HTML。 这段代码存在的问题是,当下载页面遇到错误时,我们无法加以掌控。例如: 被请求的页面可能已经不存在了。该情况下,urllib2 会抛出异常,并退出脚本。 安全起见,下面是这个程序的健壮版本,可以捕获异常:
import urllib2
def download(url):
print 'Downloading:', url
try:
html = urllib2.urlopen(url).read()
except urllib2.URLError as e:
print 'Download error:', e.reason
html = None
return html现在,如果脚本出现异常,异常信息会被抓取,并返回 None。
1.1 下载重试
有时候,下载过程的遇到的错误只是临时的,例如 Web Server 过载并返回了一个 503 服务不可用的报错。 对于这类错误,可以选择重新下载,可能问题就解决了。但是,并不是所有的错误都可以用下载重试解决,比如 404 找不到资源的错误,这类错误,重试多少遍都是一样的结果。
完整的 HTTP 错误清单由 Internet Engineering Task Force 来定义,详情见: https://tools.ietf.org/html/ rfc7231#section-6。从文档中的描述可以知道 4xx 的错误往往是因为我们的请求有问题,5xx 的错误是因为服务器端出了问题。 因此我们限制爬虫只针对 5xx 的错误发起下载重试。下面是支持该功能的脚本:
def download(url, num_retries=2):
print 'Downloading:', url
try:
html = urllib2.urlopen(url).read()
except urllib2.URLError as e:
print 'Download error:', e.reason
html = None
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
# recursively retry 5xx HTTP errors
return download(url, num_retries-1)
return html现在当下载遇到 5XX 错误时,download 方法会递归的调用自身。download方法通过参数 num_retries 设定重试的次数,这里默认是2次。之所以设置有限的重试次数,是因为 Server 的问题不一定及时回复。可以用下面的URL来做该方法的测试,http://httpstat.us/500,它会返回一个 500 代码的错误:
>>> download('http://httpstat.us/500')
Downloading: http://httpstat.us/500
Download error: Internal Server Error
Downloading: http://httpstat.us/500
Download error: Internal Server Error
Downloading: http://httpstat.us/500
Download error: Internal Server Error正如预期的那样,下载函数尝试下载页面,在收到 500 错误后,它会在放弃之前再重试两次。
1.2 设置 User Agent
默认情况下,urllib2 使用 User Agent Python-urllib/2.7 下载页面内容。2.7 是你所用的Python版本。有些站点会封掉咱们的默认User Agent 请求。例如,下面的内容是使用默认 User Agent 爬取网站
http://www.meetup.com/ 返回的响应:
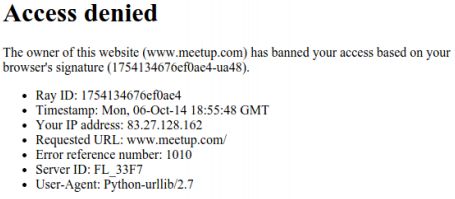
因此,为了使下载更可靠,我们需要对 User Agent 加以控制。下面的程序段加入了相关功能的更新,将默认 User Agent 改成了 wswp (Web Scraping with Python):
def download(url, user_agent='wswp', num_retries=2):
print 'Downloading:', url
headers = {'User-agent': user_agent}
request = urllib2.Request(url, headers=headers)
try:
html = urllib2.urlopen(request).read()
except urllib2.URLError as e:
print 'Download error:', e.reason
html = None
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
# retry 5XX HTTP errors
return download(url, user_agent, num_retries-1)
return html现在我们有了一个灵活的download方法,在后面的操作中我们将复用这个例子。
2. Sitemap 爬虫
第一个爬虫,我们将利用在 example website 上发现的 robots.txt 来下载所有页面。 为了解析 sitemap 文件内容,我们使用简单的正则表达式来提取 标签里的 URL 。 除了正则表达式,我们还可以使用一个更加健壮的解析方法(CSS 选择器)。下面是我们第一个 example 爬虫:
def crawl_sitemap(url):
# download the sitemap file
sitemap = download(url)
# extract the sitemap links
links = re.findall('(.*?) ', sitemap)
# download each link
for link in links:
html = download(link)
# scrape html here
# ...现在我们运行这个 sitemap crawler 去从 example website 下载所有 countries 相关的页面:
>>> crawl_sitemap('http://example.webscraping.com/sitemap.xml')
Downloading: http://example.webscraping.com/sitemap.xml
Downloading: http://example.webscraping.com/view/Afghanistan-1
Downloading: http://example.webscraping.com/view/Aland-Islands-2
Downloading: http://example.webscraping.com/view/Albania-3值得提醒的是,Sitemap 并不能保证包含所有的页面。下一小节,我们介绍另外一种爬虫,这个爬虫不需要依赖 Sitemap 文件。
3. ID 迭代爬虫
这一节,我们利用站点结构的漏洞来轻松访问内容。 下面是一些 sample countries 的 URL:
- http://example.webscraping.com/view/Afghanistan-1
- http://example.webscraping.com/view/Aland-Islands-2
- http://example.webscraping.com/view/Albania-3
URL 之间只有最后不同,国家的名字(URL 中的 slug)和 ID(URL后面的数字)。 一般而言,网站服务器会忽略 slug(第三个URL的粗体部分),仅仅通过后面的 ID 来匹配数据库中的数据。我们删掉 slug 只带上 ID 访问一下URL: http://example.webscraping.com/view/1
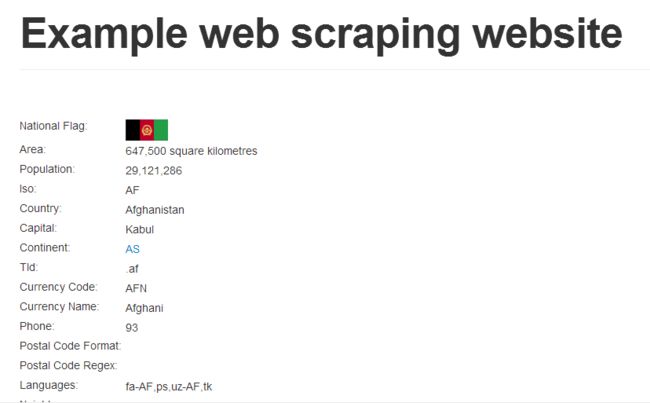
仍然可以加载页面!如此一来,我们可以忽略 slug ,仅仅使用 ID 来下载所有国家页面。看看下面的这段代码:
import itertools
for page in itertools.count(1):
url = 'http://example.webscraping.com/view/-%d' % page
html = download(url)
if html is None:
break
else:
# success - can scrape the result
pass这里,我们迭代 ID 直到遇到下载报错,也就意味着没有尚未下载的页面了。这样做有个缺点,如果 ID 为 5 的那条记录被删除了,那么 5 以后的数据,我们都爬不到了。 下面的代码加入了改进内容,允许爬虫在遇到连续 N 次的下载错误后才退出:
# maximum number of consecutive download errors allowed
max_errors = 5
# current number of consecutive download errors
num_errors = 0
for page in itertools.count(1):
url = 'http://example.webscraping.com/view/-%d' % page
html = download(url)
if html is None:
# received an error trying to download this webpage
num_errors += 1
if num_errors == max_errors:
# reached maximum number of
# consecutive errors so exit
break
else:
# success - can scrape the result
# ...
num_errors = 0现在爬虫要遇到连续的五次下载错误,才会退出,降低了因部分记录删除引起的提前停止爬取内容。这种方式还是不够健壮。例如,有些网站会对 slug 做校验, 如果请求的 URL 中没有 slug 就会返回 404 错误信息。还有的网站的 ID 是不连续的或是非数字的。Amazon 使用 ISBNs 作为图书的 ID,每个 ISBN 最少有8位数字组成。这样就让爬取工作显得很尴尬了。
4. 链接爬虫
前面两种爬虫实现简单,但往往并不具备一定的通用性,健壮性也不够。
对于其他网站,我们期望爬虫表现的更像是一个典型用户,根据链接爬取有趣的内容。例如我们要爬取某个论坛的用户账户详细信息,仅需要爬取该网站的账号详情页面。链接爬虫,可以使用正则表达式来决定哪些页面需要被下载。下面是这个爬虫的初始版本的代码:
import re
def link_crawler(seed_url, link_regex):
"""Crawl from the given seed URL following links matched by link_regex
"""
crawl_queue = [seed_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
# filter for links matching our regular expression
for link in get_links(html):
if re.match(link_regex, link):
crawl_queue.append(link)
def get_links(html):
"""Return a list of links from html
"""
# a regular expression to extract all links from the webpage
webpage_regex = re.compile(']+href=["\'](.*?)["\']' ,
re.IGNORECASE)
# list of all links from the webpage运行爬虫,调用 link_crawler function即可,传入要爬取站点的 URL 和正则表达式用于过滤目标 URL。 这里,我们要爬取国家的列表和国家信息。
索引连接符合以下格式:
- http://example.webscraping.com/index/1
- http://example.webscraping.com/index/2
国家页面符合以下格式:
- http://example.webscraping.com/view/Afghanistan-1
- http://example.webscraping.com/view/Aland-Islands-2
我们需要的匹配一上两种格式的正则表达式就是:/(index|view)/
如果我们运行爬虫,会报下载错误:
>>> link_crawler('http://example.webscraping.com',
'example.webscraping.com/(index|view)/')
Downloading: http://example.webscraping.com
Downloading: /index/1
Traceback (most recent call last):
...
ValueError: unknown url type: /index/1/index/1 知识页面的相对路径,完整的URL包括协议和服务器。为了使 urllib2 定位网页,我们需要把这个相对链接转化为绝对地址。幸运的是,Python 中有个模块叫做 urlparse 可以做到这一点。下面是包含 urlparse 的链接爬虫的改进代码:
import urlparse
def link_crawler(seed_url, link_regex):
"""Crawl from the given seed URL following links matched by link_regex
"""
crawl_queue = [seed_url]
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
for link in get_links(html):
if re.match(link_regex, link):
link = urlparse.urljoin(seed_url, link)
crawl_queue.append(link)运行这段代码不再报错了,但是还有一个问题。由于页面直间的互通性,往往会重复下载已经处理的页面。为了防止爬取重复的链接,我们需要跟踪已经爬取的页面。 下面是改进后的代码:
def link_crawler(seed_url, link_regex):
crawl_queue = [seed_url]
# keep track which URL's have seen before
seen = set(crawl_queue)
while crawl_queue:
url = crawl_queue.pop()
html = download(url)
for link in get_links(html):
# check if link matches expected regex
if re.match(link_regex, link):
# form absolute link
link = urlparse.urljoin(seed_url, link)
# check if have already seen this link
if link not in seen:
seen.add(link)
crawl_queue.append(link)运行这个脚本,终于如愿抓取了想要的内容,有了一个可以正常工作的爬虫了!
4.1 高级功能
4.1.1 解析 robots.txt
首先,我们需要解析 robots.txt ,避免下载 Blocked URLs。Python 中有个叫做 robotparser 的模块,可以帮我们完成这个工作:
>>> import robotparser
>>> rp = robotparser.RobotFileParser()
>>> rp.set_url('http://example.webscraping.com/robots.txt')
>>> rp.read()
>>> url = 'http://example.webscraping.com'
>>> user_agent = 'BadCrawler'
>>> rp.can_fetch(user_agent, url)
False
>>> user_agent = 'GoodCrawler'
>>> rp.can_fetch(user_agent, url)
Truerobotparser 模块加载 robots.txt 文件,然后提供了 can_fetch()
方法,可以告知我们某个特定的 User Agent 是否被目标站允许访问。上面,当把 user agent 设置为 ‘BadCrawler’, robotparser 模块告诉我们这个页面不能爬。正如 robots.txt 中事先定义好的。
把这个功能集成到爬虫,我们需要在爬去循环内添加校验:
...
while crawl_queue:
url = crawl_queue.pop()
# check url passes robots.txt restrictions
if rp.can_fetch(user_agent, url):
...
else:
print 'Blocked by robots.txt:', url4.1.2 支持代理
有些网站,我们只能通过代理访问,比如 Netflix,它不允许美国以外的IP访问。让 urllib2 支持代理不是太容易 (比较友好的是 requests 模块,可以参考文档 http://docs.python-requests.org/)。下面的代码展示了如何让 urllib2 支持代理:
proxy = ...
opener = urllib2.build_opener()
proxy_params = {urlparse.urlparse(url).scheme: proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
response = opener.open(request)下面是支持代理的升级版 download 方法:
def download(url, user_agent='wswp', proxy=None, num_retries=2):
print 'Downloading:', url
headers = {'User-agent': user_agent}
request = urllib2.Request(url, headers=headers)
opener = urllib2.build_opener()
if proxy:
proxy_params = {urlparse.urlparse(url).scheme: proxy}
opener.add_handler(urllib2.ProxyHandler(proxy_params))
try:
html = opener.open(request).read()
except urllib2.URLError as e:
print 'Download error:', e.reason
html = None
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
# retry 5XX HTTP errors
html = download(url, user_agent, proxy,
num_retries-1)
return html4.1.3 减速下载
如果我们的爬虫下载过快,会导致IP被封或过载服务器。为了避免此类事件发生,我们可以在两个下载中间加入延迟操作:
class Throttle:
"""Add a delay between downloads to the same domain
"""
def __init__(self, delay):
# amount of delay between downloads for each domain
self.delay = delay
# timestamp of when a domain was last accessed
self.domains = {}
def wait(self, url):
domain = urlparse.urlparse(url).netloc
last_accessed = self.domains.get(domain)
if self.delay > 0 and last_accessed is not None:
sleep_secs = self.delay - (datetime.datetime.now() -
last_accessed).seconds
if sleep_secs > 0:
# domain has been accessed recently
# so need to sleep
time.sleep(sleep_secs)
# update the last accessed time
self.domains[domain] = datetime.datetime.now()Throttle 类确保了两次访问同一个 domain 的时间间隔大于等于指定值。我们可以在爬虫的下载方法前,加入 Throttle:
throttle = Throttle(delay)
...
throttle.wait(url)
result = download(url, headers, proxy=proxy,
num_retries=num_retries)4.1.4 规避爬虫陷阱
比如有个提供万年历服务的网站,日历是一天指向一天,年复一年往后排,如果爬去到这些链接,会没完没了,明后年还没到的这些链接,就构成了爬虫陷阱。
这里,我们用爬取深度 depth 来做控制。看关联到某个页面链接数,如果打到设定的深度,就不再将链接到当前页面的子页面加入爬取队列。为了实现这个功能,我们修改 seen 变量,它当前被用来追踪已访问的页面,在字典中记录着访问的这些页面的深度:
def link_crawler(..., max_depth=2):
max_depth = 2
seen = {}
...
depth = seen[url]
if depth != max_depth:
for link in links:
if link not in seen:
seen[link] = depth + 1
crawl_queue.append(link)有了这个特性,我们可以确保爬虫最后一定会结束。如果要关闭这个功能,只需要将 max_depth设置为负值。当前深度用于不会等于它。
4.1.5 最终版本的程序
包含高级特性的最终程序下载地址:https://bitbucket.org/wswp/code/src/tip/chapter01/link_crawler3.py
测试的话,我们设置 user agent为 BadCrawler,这个在 robots.txt 里定义的是需要禁止的UserAgent。正如预期,爬虫被封,立刻停止了:
>>> seed_url = 'http://example.webscraping.com/index'
>>> link_regex = '/(index|view)'
>>> link_crawler(seed_url, link_regex, user_agent='BadCrawler')
Blocked by robots.txt: http://example.webscraping.com/下面换个User Agent,把最大深度设置为1,运行爬虫,预期应该能爬取首页第一页的所有内容:
>>> link_crawler(seed_url, link_regex, max_depth=1)
Downloading: http://example.webscraping.com//index
Downloading: http://example.webscraping.com/index/1
Downloading: http://example.webscraping.com/view/Antigua-and-Barbuda-10
Downloading: http://example.webscraping.com/view/Antarctica-9
Downloading: http://example.webscraping.com/view/Anguilla-8
Downloading: http://example.webscraping.com/view/Angola-7
Downloading: http://example.webscraping.com/view/Andorra-6
Downloading: http://example.webscraping.com/view/American-Samoa-5
Downloading: http://example.webscraping.com/view/Algeria-4
Downloading: http://example.webscraping.com/view/Albania-3
Downloading: http://example.webscraping.com/view/Aland-Islands-2
Downloading: http://example.webscraping.com/view/Afghanistan-1正如预期,爬虫停掉了,下载了第一页关于国家的所有信息。
下一节,我们将讨论如何在爬到的页面中提取数据。