kaldi-yesno例子
"yesno"语料库是一个非常小打一个人的录音数据集,测试集在单声道阶段完全被识别
WER(WordError Rate)是字错误率,是一个衡量语音识别系统的准确程度的度量。
其计算公式是WER=(I+D+S)/N,
I代表被插入的单词个数
D代表被删除的单词个数
S代表被替换的单词个数
通俗来讲是把识别出来的结果中,多认的,少认的,认错的全都加起来,除以总单词数。这个数字当然是越低越好。
总共60个wav文件,采样率都是8k,wav文件里每一个单词要么”ken”要么”lo”(“yes”和”no”)的发音,所以每个文件有8个发音,文件命名中的1代表yes发音,0代表no的发音.
借鉴https://blog.csdn.net/shichaog/article/details/73264152?locationNum=9&fps=1
数据预处理
wav文件预处理
local/prepare_data.sh waves_yesno
local/prepare_dict.sh
utils/prepare_lang.sh --position-dependent-phones false data/local/dict "" data/local/lang data/lang
local/prepare_lm.sh - 生成wavelist文件
ls -1 $waves_dir > data/local/waves_all.list上述shell命令就是把waves_yeno目录下的文件名全部保存到waves_all.list中.
local/create_yesno_waves_test_train.pl waves_all.list waves.test waves.train- 生成waves.test和waves.train
- 将waves_all.list中的60个wav文件,分成两拨,各30个,分别放在waves.test和waves.train中.
如waves.train文件内容如下:
0_0_0_0_1_1_1_1.wav- 生成test_yesno_wav.scp和train_yesno_wav.scp
根据waves.test 和waves.train又会生成test_yesno_wav.scp和train_yesno_wav.scp两个文件.
这两个文件内容排列格式如下
如:
0_0_0_0_1_1_1_1 waves_yesno/0_0_0_0_1_1_1_1.wav 其中由于训练的scp文件如下:
- 生成train_yesno.txt和test_yesno.txt
这两个文件存放的是发音id和对应的文本.
如:
0_0_1_1_1_1_0_0 NO NO YES YES YES YES NO NO
- 生成utt2spk和spk2utt
这个两个文件分别是发音和人对应关系,以及人和其发音id的对应关系.由于只有一个人的发音,所以这里都用global来表示发音.
utt2spk
0_0_1_0_1_0_1_1 global
utt2spk
此外还可能会有如下文件(这个例子没有用到):
- segments
包括每个录音的发音分段/对齐信息
只有在一个文件包括多个发音时需要 - reco2file_and_channel
双声道录音情况使用到 - spk2gender
将说话人和其性别建立映射关系,用于声道长度归一化.
以上生成的文件经过辅助操作均在:
data/train_yesno/
data/test_yesno/
目录结构如下:
data
├───train_yesno
│ ├───text
│ ├───utt2spk
│ ├───spk2utt
│ └───wav.scp
└───test_yesno
├───text
├───utt2spk
├───spk2utt
└───wav.scp
字典准备
构建语言学知识-词汇和发音词典.需要用到steps和utils目录下的工具。这可以通过修改该目录下的path.sh文件进行更新。
首先创建词典目录
mkdir -p data/local/dict这个简单的例子只有两个单词:YES和NO,为简单起见,这里假设这两个单词都只有一个发音:Y和N。这个例子直接拷贝了相关的文件,非语言学的发音,被定义为SIL。
data/local/dict/lexicon.txt
SIL
YES Y
NO N - lexicon.txt,完整的词位-发音对
- lexicon_words.txt,单词-发音对
- silence_phones.txt, 非语言学发音
- nonsilence_phones.txt,语言学发音
- optional_silence.txt ,备选非语言发音
最后还要把字典转换成kaldi可以接受的数据结构-FST(finit state transducer)。这一转换使用如下命令:
utils/prepare_lang.sh --position-dependent-phones false data/local/dict "" data/local/lang data/lang 由于语料有限,所以将位置相关的发音disable。这个命令的各行意义如下:
utils/prepare_lang.sh --position-dependent-phones false - OOV存放的是词汇表以外的词,这里就是静音词(非语言学发声意义的词)
发音字典是二进制的OpenFst 格式,可以使用如下命令查看:
gsc@X250:~/kaldi/egs/yesno/s5$ ~/kaldi/tools/openfst-1.6.2/bin/fstprint --isymbols=data/lang/phones.txt --osymbols=data/lang/words.txt data/lang/L.fst
0 1 0.693147182
0 1 SIL 0.693147182
1 1 SIL
1 1 N NO 0.693147182
1 2 N NO 0.693147182
1 1 Y YES 0.693147182
1 2 Y YES 0.693147182
1
2 1 SIL
语言学模型
这里使用的是一元文法语言模型,同样要转换成FST以便kaldi接受。该语言模型原始文件是data/local/lm_tg.arpa,生成好的FST格式的。是字符串和整型值之间的映射关系,kaldi里使用整型值。
gsc@X250:~/kaldi/egs/yesno/s5$ head -5 data/lang/phones.txt
0
SIL 1
Y 2
N 3
#0 4
gsc@X250:~/kaldi/egs/yesno/s5$ head -5 data/lang/words.txt
0
1
NO 2
YES 3
#0 4 可以使用如下命令查看生成音素的树形结构:
phone 树
~/kaldi/src/bin/draw-tree data/lang/phones.txt exp/mono0a/tree | dot -Tps -Gsize=8,10.5 | ps2pdf - ./tree.pdf
LM(language model)在data/lang_test_tg/。
local/prepare_lm.sh查看拓扑结构
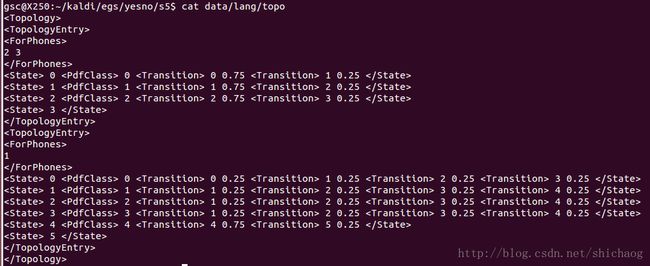
在
之间的数字,1表示silcense,2,3分别表示Y和N,这从拓扑图里也可以看出来。
指定了三个状态从左到右的HMM以及默认的转变概率。为silence赋予5个状态。
0.mdl的内容如上:
转移模型
2 3
0 0 0 0.75 1 0.25
1 1 1 0.75 2 0.25
2 2 2 0.75 3 0.25
3
1
0 0 0 0.25 1 0.25 2 0.25 3 0.25
1 1 1 0.25 2 0.25 3 0.25 4 0.25
2 2 1 0.25 2 0.25 3 0.25 4 0.25
3 3 1 0.25 2 0.25 3 0.25 4 0.25
4 4 4 0.75 5 0.25
5
音素 hmm状态
11
1 0 0
1 1 1
1 2 2
1 3 3
1 4 4
2 0 5
2 1 6
2 2 7
3 0 8
3 1 9
3 2 10
高斯模型
如下的20+1个log概率对应于11个phone(0-10)。
[ 0 -1.386294 ... ]
接下来是高斯模型的维度39维(没有能量),对角GMM参数总共11个。
39 11
在接下来就是对角高斯参数的均值方差权重等参数:
[ -79.98567 ]
[ 1 ]
[
0.001624335 ...]
[
0.006809053 ... ] 编译训练图

为每一个训练的发音编译FST,为训练的发句编码HMM结构。
kaldi 中表的概念
表是字符索引-对象的集合,有两种对象存储于磁盘
“scp”(script)机制:.scp文件从key(字串)映射到文件名或者pipe
“ark”(archive)机制:数据存储在一个文件中。
Kaldi 中表
一个表存在两种形式:”archive”和”script file”,他们的区别是archive实际上存储了数据,而script文件内容指向实际数据存储的索引。
从表中读取索引数据的程序被称为”rspecifier”,向表中写入字串的程序被称为”wspecifier”。
| rspecifier | meaning |
|---|---|
| ark:- | 从标准输入读取到的数据做为archive |
| scp:foo.scp | foo.scp文件指向了去哪里找数据 |
冒号后的内容是wxfilename 或者rxfilename,它们是pipe或者标准输入输出都可以。
表只包括一种类型的对象(如,浮点矩阵)
respecifier和wspecifier可以包括一些选项:
- 在respecifier中,ark,s,cs:- ,表示当从标准输入读操作时,我们期望key是排序过的(s),并且可以确定它们将会按排序过的顺序读取,(cs)意思是我们知道程序将按照排序过的方式 对其进行访问(如何条件不成立,程序会crash),这是得Kaldi不要太多内存下可以模拟随机访问。
* 对于数据源不是很大,并且结果和排序无关的情形时,rspecifier可以忽略s,cs。
* scp,p:foo.scp ,p表示如果scp索引的文件存在不存在的情况,程序不crash(prevent of crash)。
* 对于写,选项t表示文本模式。
script文件格式是,utt1 /foo/bar/utt1.mat
从命令行传递的参数指明如何读写表(scp,ark)。对于指示如何读表的字串称为“rspecifier”,而对写是”wspecifier”。
写表的实例如下:
| wspecifier | 意义 |
|---|---|
| ark:foo.ark | 写入归档文件foo.ark |
| scp:foo.scp | 使用映射关系写入foo.scp |
| ark:- | 将归档信息写入stdout |
| ark,t:|gzip -c > foo.gz | 将文本格式的归档写入foo.gz |
| ark,t:- | 将文本格式的归档写入 stdout |
| srk,scp:foo.ark, foo.scp | 写归档和scp文件 |
读表:
| rspecifier | 意义 |
|---|---|
| ark:foo.ark | 读取归档文件foo.ark |
| scp:foo.scp | 使用映射关系读取foo.scp |
| scp,p:foo.scp | 使用映射关系读取foo.scp,p:如果文件不存在,不报错 |
| ark:- | 从标准输入读取归档 |
| ark:gunzip -c foo.gz| | 从foo.gz读取归档信息 |
| ark,s,cs:- | 从标准输入读取归档后排序 |
特征提取和训练
特征提取,这里是做mfcc。
steps/make_mfcc.sh --nj
--nj 是处理器单元数
训练语料所在目录
这个目录下记录了make_mfcc的执行log
是mfcc特征输出目录 for x in train_yesno test_yesno; do
steps/make_mfcc.sh --nj 1 data/$x exp/make_mfcc/$x mfcc
steps/compute_cmvn_stats.sh data/$x exp/make_mfcc/$x mfcc
utils/fix_data_dir.sh data/$x
done该脚本主要执行的命令是:
gsc@X250:~/kaldi/egs/yesno/s5$ head -3 exp/make_mfcc/train_yesno/make_mfcc_train_yesno.1.log
#compute-mfcc-feats --verbose=2 --config=conf/mfcc.conf scp,p:exp/make_mfcc/train_yesno/wav_train_yesno.1.scp ark:- | copy-feats --compress=true ark:- ark,scp:/home/gsc/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.ark,/home/gsc/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.scp
copy-feats --compress=true ark:- ark,scp:/home/gsc/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.ark,/home/gsc/kaldi/egs/yesno/s5/mfcc/raw_mfcc_train_yesno.1.scp
compute-mfcc-feats --verbose=2 --config=conf/mfcc.conf scp,p:exp/make_mfcc/train_yesno/wav_train_yesno.1.scp ark:-archive文件存放的是每个发音对应的特征矩阵(帧数X13大小)。
第一个参数scp:...
指示在[dir]/wav1.scp里罗列的文件。
通常在做NN训练时,提取的是40维度,包括能量和上面的一阶差分和二阶差分。
~/kaldi/src/featbin/copy-feats ark:raw_mfcc_train_yesno.1.ark ark:- |~/kaldi/src/featbin/add-deltas ark:- ark,t:- | head然后归一化导谱特征系数
steps/compute_cmvn_stats.sh data/$x exp/make_mfcc/$x mfcc生成的文件最终在mfcc目录下:
cmvn_test_yesno.ark
cmvn_train_yesno.ark
raw_mfcc_test_yesno.1.ark
raw_mfcc_train_yesno.1.ark
cmvn_test_yesno.scp
cmvn_train_yesno.scp
raw_mfcc_test_yesno.1.scp
raw_mfcc_train_yesno.1.scp详细各个命令意义,参考kaldi官网文档http://kaldi-asr.org/doc/tools.html
单音节训练
steps/train_mono.sh --nj --cmd
--cmd ,如果使用本机资源,使用utils/run.pl。
steps/train_mono.sh --nj 1 --cmd "$train_cmd" \
--totgauss 400 \
data/train_yesno data/lang exp/mono0a 这将生成语言模型的FST,
使用如下命令可以查看输出:
fstcopy 'ark:gunzip -c exp/mono0a/fsts.1.gz|' ark,t:- | head -n 20
其每一列是(Q-from, Q-to, S-in, S-out, Cost)
解码和测试
图解码
首先测试文件也是按此生成。
然后构建全连接的FST。
utils/mkgraph.sh data/lang_test_tg exp/mono0a exp/mono0a/graph_tgpr解码
# Decoding
steps/decode.sh --nj 1 --cmd "$decode_cmd" \
exp/mono0a/graph_tgpr data/test_yesno exp/mono0a/decode_test_yesno这将会生成lat.1.gz,该文件包括发音格。exp/mono/decode_test_yesno/wer_X并且也计算了词错误率。exp/mono/decode_test_yesno/scoring/X.tra是文本。X是语言模型权重LMWT。当然也可以在调用score.sh添加参数--min_lmwt 和 --max_lmwt进行修改。
结果查看
for x in exp/*/decode*; do [ -d $x ] && grep WER $x/wer_* | utils/best_wer.sh; done