Multimodal Deep Learning for Robust RGB-D Object Recognition 论文阅读
为了以后的学习方便,把几篇计算机视觉的论文放上来,仅为自己的学习方便。期间有参考了很多博客和文献,但是我写的仍然很粗糙。这篇文章仅作为入门读文献的台阶,并不作为研究的方向,以后不更了。
这篇文章是第一次阅读文献,有些抓不住重点,总结的也很乱。排版对手机端不友好。
原文地址:Multimodal Deep Learning for Robust RGB-D Object Recognition
研究问题的背景
物体识别(Object Recognition)是计算机视觉(Computer Vision)领域的一种技术,旨在检测、分类图像以及视频中感兴趣的目标。针对于该技术,很多的学者已经开展了很多的研究。例如Kaiming He等人[1]提出连接在最后一层卷积层的SPP(Spatial Pyramid Pooling)层以解决一般的CNN结构中对图片进行裁剪(crop)和拉伸(warp)时造成原始图片扭曲的问题;Manen S等人[2]研究了Randomized Prim’s算法,使用类似与SelectiveSearch 的特征,但是使用了一个随机的超像素合并过程来学习所有的可能等。
深度学习是机器学习的一个重要分支,它以简化的方式模拟人脑复杂的神经系统,近些年来已被广泛用于语音识别、计算机视觉、自然语言处理等领域。深度学习的核心是特征学习,旨在通过分层网络获取分层次的特征信息,其包括的算法有CNN卷积神经网络、AutoEncoder自动编码器、RBM限制波尔兹曼机、RNN多层反馈循环神经网络神经网络以及DBN深信度网络等重要算法。其中卷积神经网络是一种前馈神经网络,它的人工神经元可以响应一部分覆盖范围内的周围单元,对于大型图像处理有出色表现。
论文的研究内容
该篇论文基于先前研究的Convolutional Neural Networks(CNNs)提出了一种结合RGB-D图像的物体识别,其中RGB-D包括RGB三通道彩色图像和Depth图像。
该篇论文中的架构由两个独立的CNN网络流组成,并于后期增加了融合层将双流的特征融合,最后进行物体分类,如图1所示。
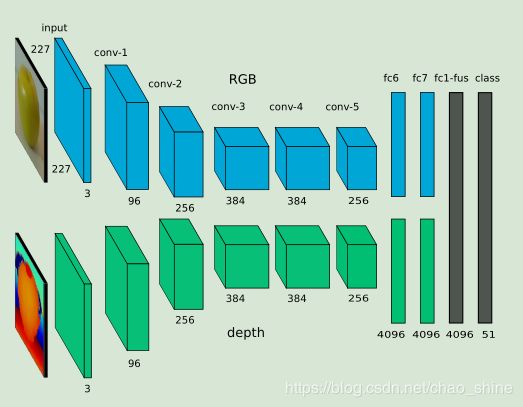
图1 结合RGB-D图像实现的双流网络
该结构与论文[3][4][5]中体现的结构有一定的相似性,其中论文[3]中是利用时间域和空间域的视频识别双流网络架构,如图2所示。

图2 基于时域和空域的视频分类的双流网络
1、论文中涉及的知识点
A、RGB-D图像
Depth图像类似于灰度图像,它的每个像素值是传感器距离物体的实际距离。通常RGB图像和Depth图像是配准的,因而像素点之间具有一一对应关系。RGB-D传感器因不需要复杂的硬件系统,并有开源的软件支撑,现已经普遍运用到实际的机器人系统的应用中。RGB-D图像不仅提供了RGB图像中包含的物体表面和结构信息,并且深度图像中包含了物体的形状信息等,其中深度图像的体现信息不受光线和色彩的影响。
因实际得到的传感器数据不是完全理想,经常会因为遮挡和传感器本身的噪声而产生一些不理想的数据。为充分利用现实生活中通过传感器得到的数据,本文利用双流网络(分别对RGB图像和Depth图像进行训练)在后期进行融合。针对于Depth图像,该篇论文提出了两种方法来处理Depth图像数据。
一、针对于Depth图编码
该论文提出了一种有效的编码方式,可以从竟可能少的数据中学习更多的特征。该方法首先将深度图数值进行标准化到0-255,然后,在给定图像上应用喷射色彩图,将输入从单个图像转换为三个通道图像。对于Depth图像中的每个像素将距离映射到从红色(近)到绿色到蓝色(远)的颜色值,基本上在所有三个RGB通道上分布深度信息。
不同编码方式的结果图如图3所示:

图3 不同方法下对Depth图像编码的效果
图3中编码方法从左到右依次为RGB、Depth-gray、suface-normals[6]、HHA[7]、论文中的方法。从论文中的数据可以看出,该论文提出的方法效果比较好,具体原因未搞明白。
二、Depth图数据增强
通过腐蚀从现实环境中采样的缺失数据模式的Depth数据,来增强可用的训练示例,具体操作在论文中没有体现。
B、数据预处理
该篇论文使用CaffeNet框架[8]对网络进行训练,但是需要的输入数据是像素大小为227*227RGB图像。该论文针对此问题提出了一种裁剪的方法:保持目标的最长边不变,对目标的最短边进行裁剪,得到一个N*256或256*N像素的图像。对比结果图如图4所示:
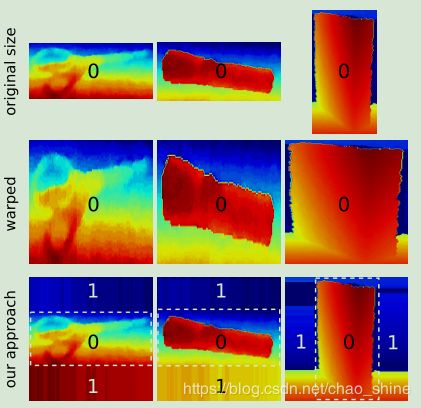
图4 不同的裁剪方法效果图
个人考虑想法:是否可以运用文献[1]中的方法对图片进行预处理。
C、网络训练(这部分产生的问题最多,并且对论文理解不到位,现只写了自己产生的问题以及部分解决方法)
⑴ CNN的原理和每个步骤的作用;卷积层、池化层、全连接层以及softmax分类层的原理和作用?
⑵ 神经网络的参数和偏差是什么,干什么用的,个数怎么确定的;
⑶ 预训练的原理和步骤;
上面三个问题参考了该网址,现在理解的不是很透彻,里面讲的一些原理性知识在结合机械工业出版社出版的《深度学习与计算机视觉 算法原理、框架应用与代码实现》一书理解学习。
文章中参数用到了假设为来自利用CaffeNet训练得到的,但是没有给出理由。
⑷ RGB-D物体识别的融合的方法和作用;
⑸ 融合权重是怎么确定的?
在该论文的III.B.⑵ Training the fusion network 中提到了利用softmax权重将他们融合到一起,并在softmax分类层进行分类,这里没有看懂。
⑹ 分类层怎么做的分类?
这里没看懂。
2、文献的主要贡献
⑴ 提出了利用双流网络来提高物体识别的准确率,并为适合运用CaffeNet对数据进行了预处理(是否可以结合文献[1])。
⑵ 对Depth图像进行了合理的着色编码和数据增强,提高了物体识别的准确率,并提高了对噪声容错率。(原因没有搞懂)
3、结论
论文介绍了一种用于RGB-物体识别的新型多模态神经网络架构,经在RGB-D对象数据集上测试,该架构体现了先进的性能。论文通过提出一个双流卷积神经网络,可以在分类之前自动融合来自RGB和深度的信息,通过两方面的特征信息,提高了物体识别的准确率。通过利用从深度到图像数据的有效编码方法,使得该论文的方法可以利用在ImageNet数据集上训练用于物体识别的较复杂的卷积神经网络(CNN)。论文提出了一种Depth数据增强方法,旨在提高在嘈杂的真实世界设置中的识别能力。论文使用文献提供的数据[1][9],提供了大量的实验结果,证明了方法是准确的——能够从RGB和Depth域学习更多的特征。通过在真实环境[9]的实验,论文提出噪声感知训练展示了强大的物体识别功能,提高了RGB-D场景数据集的识别精度。
参考文献
- He K, Zhang X, Ren S, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
- Manen S, Guillaumin M, Van Gool L, et al. Prime Object Proposals with Randomized Prim's Algorithm[C]. international conference on computer vision, 2013: 2536-2543.
- Simonyan K, Zisserman A. Two-Stream Convolutional Networks for Action Recognition in Videos[J]. neural information processing systems, 2014: 568-576.
- Srivastava N, Salakhutdinov R. Multimodal learning with deep Boltzmann machines[J]. Journal of Machine Learning Research, 2014, 15(1): 2949-2980.
- Hariharan B, Arbelaez P, Girshick R B, et al. Simultaneous Detection and Segmentation[J]. european conference on computer vision, 2014: 297-312.
- Bo L, Ren X, Fox D. Unsupervised Feature Learning for RGB-D Based Object Recognition[M]. Experimental Robotics. Springer International Publishing, 2013:387-402.
- Gupta S, Girshick R B, Arbelaez P, et al. Learning Rich Features from RGB-D Images for Object Detection and Segmentation[J]. european conference on computer vision, 2014: 345-360.
- Jia Y, Shelhamer E, Donahue J, et al. Caffe: Convolutional Architecture for Fast Feature Embedding[J]. acm multimedia, 2014: 675-678.
- K. Lai, L. Bo, X. R. Ren, and D. Fox, “Detection-based object labeling in 3d scenes,” in Proc. of the IEEE Int. Conf. on Robotics & Automation (ICRA), 2012.