网络爬虫:各种模板
运行BeautifulSoup
import urllib.request
import urllib.error
from bs4 import BeautifulSoup
def get_title(url):
try:
req=urllib.request.Request(url)
response=urllib.request.urlopen(req)
except (urllib.error.HTTPError,urllib.error.URLError) as e:
#网页在服务器不存在,或者服务器不存在
print(e)
return None
try:
html = response.read().decode("utf-8")
soup = BeautifulSoup(html, "html.parser")
title=soup.body.h1
except AttributeError as e:
#标签不存在
return None
return title
if __name__=="__main__":
url="http://www.pythonscraping.com/exercises/exercise1.html"
title=get_title(url)
if title == None:
print("Title could not be found")
else:
print(title)我们创建了一个getTitle函数,可以返回网页的标题,如果获取网页的时候遇到问题就返回一个None对象。在getTitle函数里,检查了HTTPError,还检查了由于URL输入错误引起的URLError,然后把BeautifulSoup代码封装在一个try语句里面。这两行中的任何一行有问题,AttributeError 都可能被抛出(如果服务器不存在,html就是一个None对象,html.read()就会抛出AttributeError )。其实,我们可以在try语句里面放任意多行代码,或者放一个在任何位置都可以抛出AttributeError 的函数。
运行BeautifulSoup的find()和findAll()
# nameList = bsObj.findAll("span", {"class":"green"})
nameList = bsObj.findAll("span", class_="green")
for name in nameList:
print(name.get_text())更详细见:http://blog.csdn.net/chaowanghn/article/details/54646683
处理子标签、兄弟标签和父标签
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html, "html.parser")
for child in bsObj.find("table",{"id":"giftList"}).children:
print(child)from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html, "html.parser")
for sibling in bsObj.find("table",{"id":"giftList"}).tr.next_siblings:
print(sibling) from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html, "html.parser")
print(bsObj.find("img",{"src":"../img/gifts/img1.jpg"}).parent.previous_sibling.get_text())查找图片
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
html = urlopen("http://www.pythonscraping.com/pages/page3.html")
bsObj = BeautifulSoup(html, "html.parser")
images = bsObj.findAll("img", {"src":re.compile("\.\.\/img\/gifts/img.*\.jpg")})
for image in images:
print(image["src"])
#print(image.attrs["src"])
查找网址链接
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
def getLinks(articleUrl):
html = urlopen("http://en.wikipedia.org/wiki/Kevin_Bacon")
bsObj = BeautifulSoup(html, "html.parser")
links=bsObj.find("a")
# links=bsObj.find("div", {"id":"bodyContent"}).findAll("a", href=re.compile("^(/wiki/)((?!:).)*$"))
for link in links:
if "href" in link.attrs:
print (link.attrs["href"])更换请求头
# 增加headers,模拟登陆,而不是对服务器识别为机器登陆。使用移动设备浏览网站时,通常会看到一个没有广告的、Flash以及其他干扰的简化的网站版本。
url="http://baidu.com"
headers={}
headers["User-Agent"]="Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) AppleWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 Mobile/11D257 Safari/9537.53"
req=urllib.request.Request(url,headers=headers)
# req=urllib.request.Request(url,data,headers)
#或者使用Request.add_header(key,value)
# req=urllib.request.Request(url,data)
# req.add_header("User-Agent","Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X) AppleWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 Mobile/11D257 Safari/9537.53")
response=urllib.request.urlopen(req)
html=response.read().decode("utf-8")
print (html)URL管理器— urllib.request下载网页:添加特殊情景的处理器
urllib.request.HTTPCookieProcessor添加cookie登录
urllib.request.ProxyHandler添加代理
urllib.request.HTTPSHandler处理https加密访问的网页
urllib.request.HTTPRedirectHandler处理URL相互自动的跳转关系
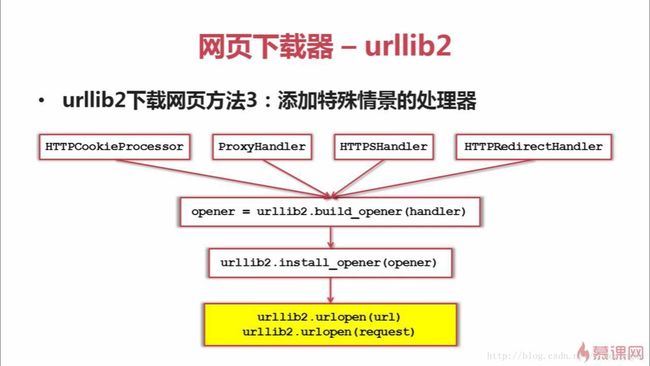
#比如使用cookie访问网页
import urllib.request, http.cookiejar
from bs4 import BeautifulSoup
#创建cookie容器
cj=http.cookiejar.CookieJar()
#创建1个opener
opener=urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
#给urllib安装opener
urllib.request.install_opener(opener)
#使用带有cookie的urllib访问网页
#response=urllib.request.urlopen("http://www.baidu.com")
url="http://www.baidu.com"
request = urllib.request.Request(url)
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
soup = BeautifulSoup(html, "html.parser")
print (soup.prettify())#_*_ coding:utf-8 _*_
import urllib.request
import http.cookiejar
url="http://www.baidu.com"
print ("测试第一种方法")
response1=urllib.request.urlopen(url)
print (response1.getcode())
print (len(response1.read()))
print ("测试第二种方法")
req2=urllib.request.Request(url)
req2.add_header("User-Agent","Mozilla/5.0")
response2=urllib.request.urlopen(req2)
print (response2.getcode())
print (len(response2.read()))
print ("测试第三种方法")
#创建cookie容器
cj=http.cookiejar.CookieJar()
#创建1个opener
opener=urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cj))
#给urllib安装opener
urllib.request.install_opener(opener)
#使用带有cookie的urllib访问网页
response3=urllib.request.urlopen(url)
print (response3.getcode())
print (len(response3.read()))
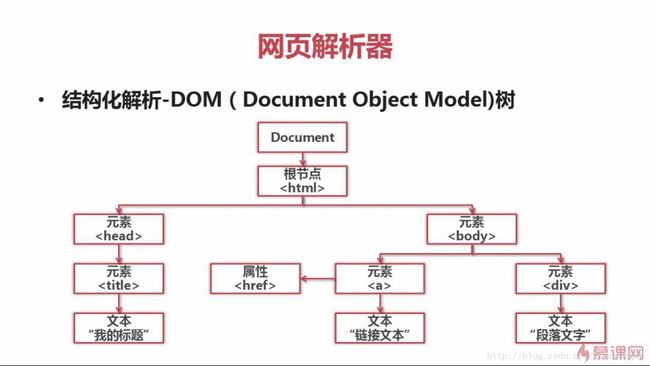
print (cj) #打印cookie的内容网页解析器
网页解析器
网页解析器:从网页中提取有价值数据的工具
网页解析器方法:正则表达式、html.parse、BeautifulSoup、lxml