Python Http Server (简易网站)二
首先,先了解一下 HTTP REQUEST 即 http 请求的类型:
![]()
由上一节我们搭建的 http 服务器。在运行后我们用浏览器访问时,可以看到服务器这边会有访问信息的输出。
解释一下,大概就是IP,日期,还有 HTTP 请求的类型了。
GET 就是请求方式, 紧接着是请求文件的相对路径。 这个和 HTML 代码有关。
这里的 favicon.ico 其实是默认访问的网页图标。我们忽略它。
有时在 HTML 代码中指定了 CSS 、JPG 、 JS 等文件的话,浏览器都会循环嵌套跟服务器逐一请求这些文件。
所以,我们需要做 url 的解析来解决不同文件的识别,返回的问题。
最后则是 请求的协议类型 HTTP/1.1 然后就是状态码了。
首先,我定义了一个函数来获取请求的文件类型,来得到对应所需要返回的 HTTP 回复的类型。
def get_file_type(self):
my_dict = {"tml": "text/html", "css": "text/css", "jpg": "image/jpg", "ico": None,
".js": "application/x-javascript"}
if len(self.path) > 3 and self.path[-3:] in my_dict:
return my_dict[self.path[-3:]]
return "text/html"这个应该蛮好理解。主要是为了方便客户端/浏览器识别 HTTP 回复的类型。
如果请求文件是 HTML 为后缀,那么就应该返回 HTML 代码。所以 content-type 的内容就是 "text/html"。
如果请求文件是 CSS 为后缀, 那么就应该返回 CSS 文件内容。所以 content-type 的内容就是 "text/css"。
浏览器就会靠 content-type 的内容来知道返回数据的类型。
定义了一个函数来获取请求文件真正的相对路径。
def get_file_name(self):
if self.path != '/':
path = '.' + self.path
return path
return './src/index.html'
这个是根据我实际的文件路径来决定的。我想做到当浏览器没有访问文件时,自动返回主页给浏览器。
而对路径做的字符串处理只是为了方便在相对路径下直接返回文件。
接下来重写我们的 do_GET()。
这里的意思大概就是获取访问文件类型,如果不是图片,则把其内容转化为二进制返回。
如果是图片,则直接读取二进制数据,返回。
这样,我们就能够根据网页里具体请求的文件类型,实现文件的访问了。
我们也就算是搭建了一个简易的网站。
def do_GET(self):
if self.path == "/favicon.ico":
return
file_type = self.get_file_type()
if file_type is not None and file_type != "image/jpg":
f = open(self.get_file_name(), encoding="utf-8")
fw = f.read()
f.close()
self.wfile.write(bytes(fw, "utf-8"))
return
elif file_type == "image/jpg":
f = open(self.get_file_name(), "rb")
fw = f.read()
f.close()
self.wfile.write(fw)
return(当然你得把自己准备好的文件放到对应的目录。)
我给主页准备了一个简易的 index.html 文件。内容如下:
Hello World!
click me
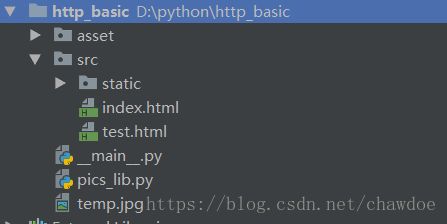
文件夹结构如上。可以看看我们的效果:
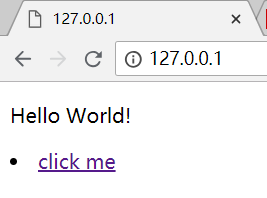
由于此时路径为空,我们之前的函数转换路径生效了,直接跳到了 /src/index.html。
恭喜你,离全栈工程师不远了。