android高级面试题(二)
Android高级面试题 (⭐⭐⭐)
一、性能优化
1、做过哪些性能优化?是怎么评测和具体优化的?
一、App启动速度优化

开放问题:如果提高启动速度,设计一个延迟加载框架或者sdk的方法和注意的问题
二、App绘制优化
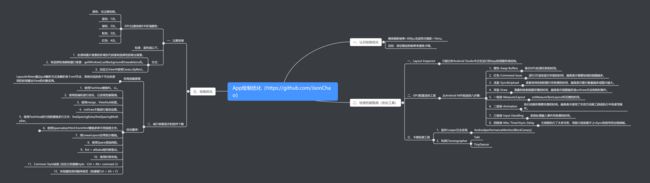
三、App内存优化
内存抖动(代码注意事项):
内存抖动是由于短时间内有大量对象进出新生区导致的,它伴随着频繁的GC,gc会大量占用ui线程和cpu资源,会导致app整体卡顿。
避免发生内存抖动的几点建议:
- 尽量避免在循环体内创建对象,应该把对象创建移到循环体外。
- 注意自定义View的onDraw()方法会被频繁调用,所以在这里面不应该频繁的创建对象。
- 当需要大量使用Bitmap的时候,试着把它们缓存在数组或容器中实现复用。
- 对于能够复用的对象,同理可以使用对象池将它们缓存起来。
四、App瘦身
五、App电量优化
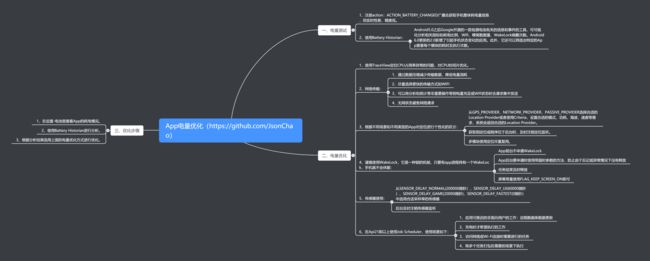
六、网络优化
移动端获取网络数据优化的几个点
-
1、连接复用:节省连接建立时间,如开启 keep-alive。于Android来说默认情况下HttpURLConnection和HttpClient都开启了keep-alive。只是2.2之前HttpURLConnection存在影响连接池的Bug。
-
2、请求合并:即将多个请求合并为一个进行请求,比较常见的就是网页中的CSS Image Sprites。如果某个页面内请求过多,也可以考虑做一定的请求合并。
-
3、减少请求数据的大小:对于post请求,body可以做gzip压缩的,header也可以做数据压缩(不过只支持http 2.0)。 返回数据的body也可以做gzip压缩,body数据体积可以缩小到原来的30%左右(也可以考虑压缩返回的json数据的key数据的体积,尤其是针对返回数据格式变化不大的情况,支付宝聊天返回的数据用到了)。
-
4、根据用户的当前的网络质量来判断下载什么质量的图片(电商用的比较多)。
-
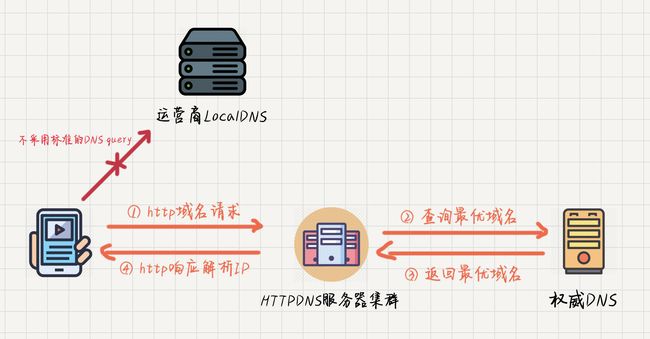
5、使用HttpDNS优化DNS:DNS存在解析慢和DNS劫持等问题,DNS 不仅支持 UDP,它还支持 TCP,但是大部分标准的 DNS 都是基于 UDP 与 DNS 服务器的 53 端口进行交互。HTTPDNS 则不同,顾名思义它是利用 HTTP 协议与 DNS 服务器的 80 端口进行交互。不走传统的 DNS 解析,从而绕过运营商的 LocalDNS 服务器,有效的防止了域名劫持,提高域名解析的效率。
参考文章
客户端网络安全实现
七、安卓的安全优化
提高app安全性的方法?
安卓的app加固如何做?
安卓的混淆原理是什么?
谈谈你对安卓签名的理解。
2、为什么WebView加载会慢呢?
这是因为在客户端中,加载H5页面之前,需要先初始化WebView,在WebView完全初始化完成之前,后续的界面加载过程都是被阻塞的。
优化手段围绕着以下两个点进行:
- 预加载WebView。
- 加载WebView的同时,请求H5页面数据。
因此常见的方法是:
- 全局WebView。
- 客户端代理页面请求。WebView初始化完成后向客户端请求数据。
- asset存放离线包。
除此之外还有一些其他的优化手段:
- 脚本执行慢,可以让脚本最后运行,不阻塞页面解析。
- DNS链接慢,可以让客户端复用使用的域名与链接。
- React框架代码执行慢,可以将这部分代码拆分出来,提前进行解析。
3、如何优化自定义View
为了加速你的view,对于频繁调用的方法,需要尽量减少不必要的代码。先从onDraw开始,需要特别注意不应该在这里做内存分配的事情,因为它会导致GC,从而导致卡顿。在初始化或者动画间隙期间做分配内存的动作。不要在动画正在执行的时候做内存分配的事情。
你还需要尽可能的减少onDraw被调用的次数,大多数时候导致onDraw都是因为调用了invalidate().因此请尽量减少调用invaildate()的次数。如果可能的话,尽量调用含有4个参数的invalidate()方法而不是没有参数的invalidate()。没有参数的invalidate会强制重绘整个view。
另外一个非常耗时的操作是请求layout。任何时候执行requestLayout(),会使得Android UI系统去遍历整个View的层级来计算出每一个view的大小。如果找到有冲突的值,它会需要重新计算好几次。另外需要尽量保持View的层级是扁平化的,这样对提高效率很有帮助。
如果你有一个复杂的UI,你应该考虑写一个自定义的ViewGroup来执行他的layout操作。与内置的view不同,自定义的view可以使得程序仅仅测量这一部分,这避免了遍历整个view的层级结构来计算大小。
4、FC(Force Close)什么时候会出现?
Error、OOM,StackOverFlowError、Runtime,比如说空指针异常
解决的办法:
- 注意内存的使用和管理
- 使用Thread.UncaughtExceptionHandler接口
5、Java多线程引发的性能问题,怎么解决?
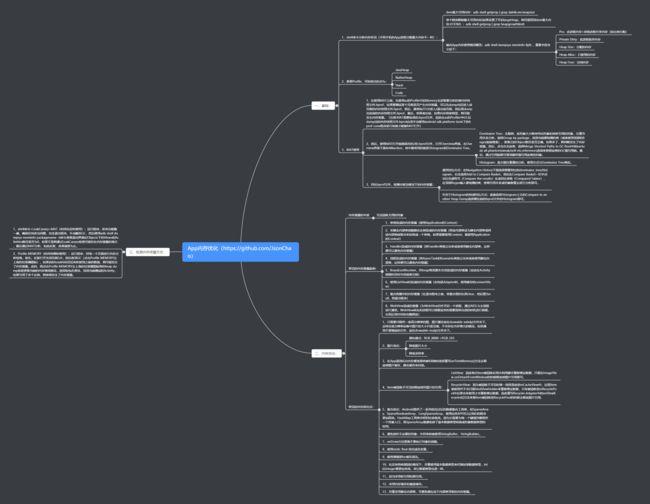
二、Android Framework相关
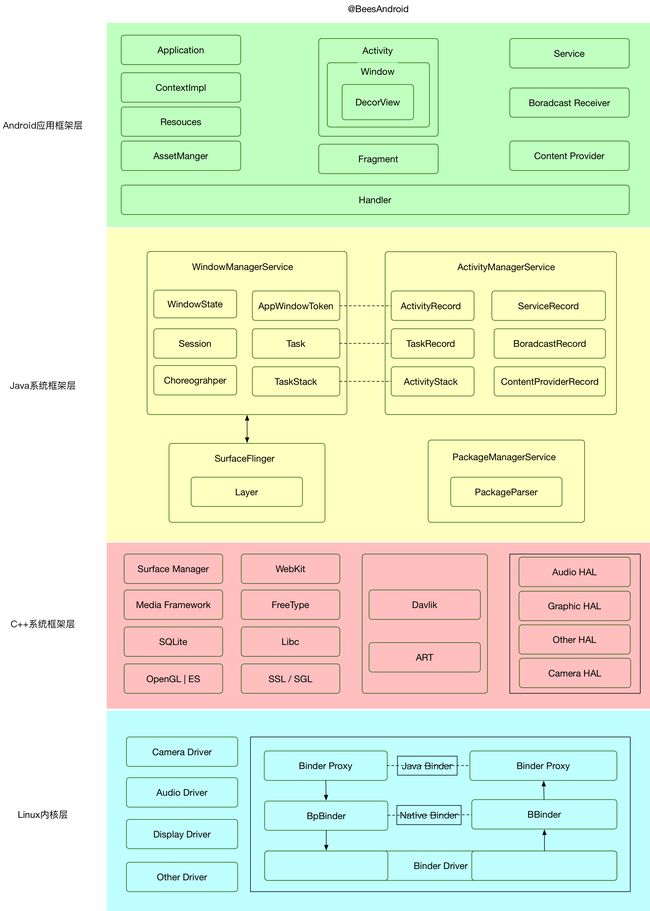
1、Android系统架构

Android 是一种基于 Linux 的开放源代码软件栈,为广泛的设备和机型而创建。下图所示为 Android 平台的五大组件:
1.应用程序
Android 随附一套用于电子邮件、短信、日历、互联网浏览和联系人等的核心应用。平台随附的应用与用户可以选择安装的应用一样,没有特殊状态。因此第三方应用可成为用户的默认网络浏览器、短信 Messenger 甚至默认键盘(有一些例外,例如系统的“设置”应用)。
系统应用可用作用户的应用,以及提供开发者可从其自己的应用访问的主要功能。例如,如果您的应用要发短信,您无需自己构建该功能,可以改为调用已安装的短信应用向您指定的接收者发送消息。
2、Java API 框架
您可通过以 Java 语言编写的 API 使用 Android OS 的整个功能集。这些 API 形成创建 Android 应用所需的构建块,它们可简化核心模块化系统组件和服务的重复使用,包括以下组件和服务:
- 丰富、可扩展的视图系统,可用以构建应用的 UI,包括列表、网格、文本框、按钮甚至可嵌入的网络浏览器
- 资源管理器,用于访问非代码资源,例如本地化的字符串、图形和布局文件
- 通知管理器,可让所有应用在状态栏中显示自定义提醒
- Activity 管理器,用于管理应用的生命周期,提供常见的导航返回栈
- 内容提供程序,可让应用访问其他应用(例如“联系人”应用)中的数据或者共享其自己的数据
开发者可以完全访问 Android 系统应用使用的框架 API。
3、系统运行库
1)原生 C/C++ 库
许多核心 Android 系统组件和服务(例如 ART 和 HAL)构建自原生代码,需要以 C 和 C++ 编写的原生库。Android 平台提供 Java 框架 API 以向应用显示其中部分原生库的功能。例如,您可以通过 Android 框架的 Java OpenGL API 访问 OpenGL ES,以支持在应用中绘制和操作 2D 和 3D 图形。如果开发的是需要 C 或 C++ 代码的应用,可以使用 Android NDK 直接从原生代码访问某些原生平台库。
2)Android Runtime
对于运行 Android 5.0(API 级别 21)或更高版本的设备,每个应用都在其自己的进程中运行,并且有其自己的 Android Runtime (ART) 实例。ART 编写为通过执行 DEX 文件在低内存设备上运行多个虚拟机,DEX 文件是一种专为 Android 设计的字节码格式,经过优化,使用的内存很少。编译工具链(例如 Jack)将 Java 源代码编译为 DEX 字节码,使其可在 Android 平台上运行。
ART 的部分主要功能包括:
- 预先 (AOT) 和即时 (JIT) 编译
- 优化的垃圾回收 (GC)
- 更好的调试支持,包括专用采样分析器、详细的诊断异常和崩溃报告,并且能够设置监视点以监控特定字段
在 Android 版本 5.0(API 级别 21)之前,Dalvik 是 Android Runtime。如果您的应用在 ART 上运行效果很好,那么它应该也可在 Dalvik 上运行,但反过来不一定。
Android 还包含一套核心运行时库,可提供 Java API 框架使用的 Java 编程语言大部分功能,包括一些 Java 8 语言功能。
4、硬件抽象层 (HAL)
硬件抽象层 (HAL) 提供标准界面,向更高级别的 Java API 框架显示设备硬件功能。HAL 包含多个库模块,其中每个模块都为特定类型的硬件组件实现一个界面,例如相机或蓝牙模块。当框架 API 要求访问设备硬件时,Android 系统将为该硬件组件加载库模块。
5、Linux 内核
Android 平台的基础是 Linux 内核。例如,Android Runtime (ART) 依靠 Linux 内核来执行底层功能,例如线程和低层内存管理。使用 Linux 内核可让 Android 利用主要安全功能,并且允许设备制造商为著名的内核开发硬件驱动程序。
对于Android应用开发来说,最好能手绘下面的系统架构图:
2、View的事件分发机制?滑动冲突怎么解决?
了解Activity的构成
一个Activity包含了一个Window对象,这个对象是由PhoneWindow来实现的。PhoneWindow将DecorView作为整个应用窗口的根View,而这个DecorView又将屏幕划分为两个区域:一个是TitleView,另一个是ContentView,而我们平时所写的就是展示在ContentView中的。
触摸事件的类型
触摸事件对应的是MotionEvent类,事件的类型主要有如下三种:
- ACTION_DOWN
- ACTION_MOVE(移动的距离超过一定的阈值会被判定为ACTION_MOVE操作)
- ACTION_UP
View事件分发本质就是对MotionEvent事件分发的过程。即当一个MotionEvent发生后,系统将这个点击事件传递到一个具体的View上。
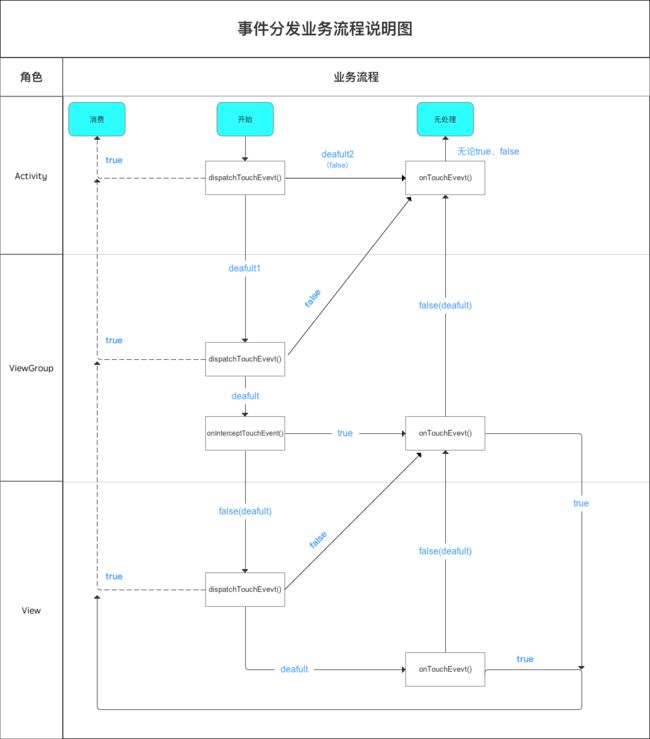
事件分发流程
事件分发过程由三个方法共同完成:
dispatchTouchEvent:方法返回值为true表示事件被当前视图消费掉;返回为super.dispatchTouchEvent表示继续分发该事件,返回为false表示交给父类的onTouchEvent处理。
onInterceptTouchEvent:方法返回值为true表示拦截这个事件并交由自身的onTouchEvent方法进行消费;返回false表示不拦截,需要继续传递给子视图。如果return super.onInterceptTouchEvent(ev), 事件拦截分两种情况:
- 1.如果该View存在子View且点击到了该子View, 则不拦截, 继续分发 给子View 处理, 此时相当于return false。
- 2.如果该View没有子View或者有子View但是没有点击中子View(此时ViewGroup 相当于普通View), 则交由该View的onTouchEvent响应,此时相当于return true。
注意:一般的LinearLayout、 RelativeLayout、FrameLayout等ViewGroup默认不拦截, 而 ScrollView、ListView等ViewGroup则可能拦截,得看具体情况。
onTouchEvent:方法返回值为true表示当前视图可以处理对应的事件;返回值为false表示当前视图不处理这个事件,它会被传递给父视图的onTouchEvent方法进行处理。如果return super.onTouchEvent(ev),事件处理分为两种情况:
- 1.如果该View是clickable或者longclickable的,则会返回true, 表示消费 了该事件, 与返回true一样;
- 2.如果该View不是clickable或者longclickable的,则会返回false, 表示不 消费该事件,将会向上传递,与返回false一样。
注意:在Android系统中,拥有事件传递处理能力的类有以下三种:
- Activity:拥有分发和消费两个方法。
- ViewGroup:拥有分发、拦截和消费三个方法。
- View:拥有分发、消费两个方法。
三个方法的关系用伪代码表示如下:
public boolean dispatchTouchEvent(MotionEvent ev) {
boolean consume = false;
if (onInterceptTouchEvent(ev)) {
consume = onTouchEvent(ev);
} else {
coonsume = child.dispatchTouchEvent(ev);
}
return consume;
}
通过上面的伪代码,我们可以大致了解点击事件的传递规则:对应一个根ViewGroup来说,点击事件产生后,首先会传递给它,这是它的dispatchTouchEvent就会被调用,如果这个ViewGroup的onInterceptTouchEvent方法返回true就表示它要拦截当前事件,接着事件就会交给这个ViewGroup处理,这时如果它的mOnTouchListener被设置,则onTouch会被调用,否则onTouchEvent会被调用。在onTouchEvent中,如果设置了mOnCLickListener,则onClick会被调用。只要View的CLICKABLE和LONG_CLICKABLE有一个为true,onTouchEvent()就会返回true消耗这个事件。如果这个ViewGroup的onInterceptTouchEvent方法返回false就表示它不拦截当前事件,这时当前事件就会继续传递给它的子元素,接着子元素的dispatchTouchEvent方法就会被调用,如此反复直到事件被最终处理。
一些重要的结论:
1、事件传递优先级:onTouchListener.onTouch > onTouchEvent > onClickListener.onClick。
2、正常情况下,一个时间序列只能被一个View拦截且消耗。因为一旦一个元素拦截了此事件,那么同一个事件序列内的所有事件都会直接交给它处理(即不会再调用这个View的拦截方法去询问它是否要拦截了,而是把剩余的ACTION_MOVE、ACTION_DOWN等事件直接交给它来处理)。特例:通过将重写View的onTouchEvent返回false可强行将事件转交给其他View处理。
3、如果View不消耗除ACTION_DOWN以外的其他事件,那么这个点击事件会消失,此时父元素的onTouchEvent并不会被调用,并且当前View可以持续收到后续的事件,最终这些消失的点击事件会传递给Activity处理。
4、ViewGroup默认不拦截任何事件(返回false)。
5、View的onTouchEvent默认都会消耗事件(返回true),除非它是不可点击的(clickable和longClickable同时为false)。View的longClickable属性默认都为false,clickable属性要分情况,比如Button的clickable属性默认为true,而TextView的clickable默认为false。
6、View的enable属性不影响onTouchEvent的默认返回值。
7、通过requestDisallowInterceptTouchEvent方法可以在子元素中干预父元素的事件分发过程,但是ACTION_DOWN事件除外。
记住这个图的传递顺序,面试的时候能够画出来,就很详细了:
ACTION_CANCEL什么时候触发,触摸button然后滑动到外部抬起会触发点击事件吗,再滑动回去抬起会么?
- 一般ACTION_CANCEL和ACTION_UP都作为View一段事件处理的结束。如果在父View中拦截ACTION_UP或ACTION_MOVE,在第一次父视图拦截消息的瞬间,父视图指定子视图不接受后续消息了,同时子视图会收到ACTION_CANCEL事件。
- 如果触摸某个控件,但是又不是在这个控件的区域上抬起(移动到别的地方了),就会出现action_cancel。
点击事件被拦截,但是想传到下面的View,如何操作?
重写子类的requestDisallowInterceptTouchEvent()方法返回true就不会执行父类的onInterceptTouchEvent(),即可将点击事件传到下面的View。
如何解决View的事件冲突?举个开发中遇到的例子?
常见开发中事件冲突的有ScrollView与RecyclerView的滑动冲突、RecyclerView内嵌同时滑动同一方向。
滑动冲突的处理规则:
- 对于由于外部滑动和内部滑动方向不一致导致的滑动冲突,可以根据滑动的方向判断谁来拦截事件。
- 对于由于外部滑动方向和内部滑动方向一致导致的滑动冲突,可以根据业务需求,规定何时让外部View拦截事件,何时由内部View拦截事件。
- 对于上面两种情况的嵌套,相对复杂,可同样根据需求在业务上找到突破点。
滑动冲突的实现方法:
- 外部拦截法:指点击事件都先经过父容器的拦截处理,如果父容器需要此事件就拦截,否则就不拦截。具体方法:需要重写父容器的onInterceptTouchEvent方法,在内部做出相应的拦截。
- 内部拦截法:指父容器不拦截任何事件,而将所有的事件都传递给子容器,如果子容器需要此事件就直接消耗,否则就交由父容器进行处理。具体方法:需要配合requestDisallowInterceptTouchEvent方法。
加深理解,GOGOGO
3、View的绘制流程?
DecorView被加载到Window中
- 从Activity的startActivity开始,最终调用到ActivityThread的handleLaunchActivity方法来创建Activity,首先,会调用performLaunchActivity方法,内部会执行Activity的onCreate方法,从而完成DecorView和Activity的创建。然后,会调用handleResumeActivity,里面首先会调用performResumeActivity去执行Activity的onResume()方法,执行完后会得到一个ActivityClientRecord对象,然后通过r.window.getDecorView()的方式得到DecorView,然后会通过a.getWindowManager()得到WindowManager,最终调用其addView()方法将DecorView加进去。
- WindowManager的实现类是WindowManagerImpl,它内部会将addView的逻辑委托给WindowManagerGlobal,可见这里使用了接口隔离和委托模式将实现和抽象充分解耦。在WindowManagerGlobal的addView()方法中不仅会将DecorView添加到Window中,同时会创建ViewRootImpl对象,并将ViewRootImpl对象和DecorView通过root.setView()把DecorView加载到Window中。这里的ViewRootImpl是ViewRoot的实现类,是连接WindowManager和DecorView的纽带。View的三大流程均是通过ViewRoot来完成的。
了解绘制的整体流程
绘制会从根视图ViewRoot的performTraversals()方法开始,从上到下遍历整个视图树,每个View控件负责绘制自己,而ViewGroup还需要负责通知自己的子View进行绘制操作。
理解MeasureSpec
MeasureSpec表示的是一个32位的整形值,它的高2位表示测量模式SpecMode,低30位表示某种测量模式下的规格大小SpecSize。MeasureSpec是View类的一个静态内部类,用来说明应该如何测量这个View。它由三种测量模式,如下:
- EXACTLY:精确测量模式,视图宽高指定为match_parent或具体数值时生效,表示父视图已经决定了子视图的精确大小,这种模式下View的测量值就是SpecSize的值。
- AT_MOST:最大值测量模式,当视图的宽高指定为wrap_content时生效,此时子视图的尺寸可以是不超过父视图允许的最大尺寸的任何尺寸。
- UNSPECIFIED:不指定测量模式, 父视图没有限制子视图的大小,子视图可以是想要的任何尺寸,通常用于系统内部,应用开发中很少用到。
MeasureSpec通过将SpecMode和SpecSize打包成一个int值来避免过多的对象内存分配,为了方便操作,其提供了打包和解包的方法,打包方法为makeMeasureSpec,解包方法为getMode和getSize。
普通View的MeasureSpec的创建规则如下:
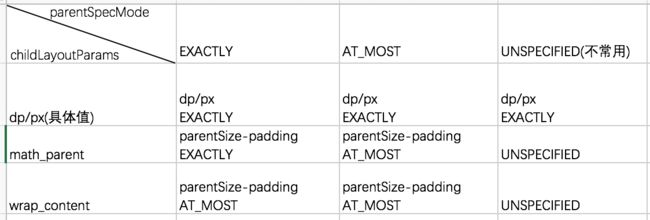
对于DecorView而言,它的MeasureSpec由窗口尺寸和其自身的LayoutParams共同决定;对于普通的View,它的MeasureSpec由父视图的MeasureSpec和其自身的LayoutParams共同决定。
View绘制流程之Measure
- 首先,在ViewGroup中的measureChildren()方法中会遍历测量ViewGroup中所有的View,当View的可见性处于GONE状态时,不对其进行测量。
- 然后,测量某个指定的View时,根据父容器的MeasureSpec和子View的LayoutParams等信息计算子View的MeasureSpec。
- 最后,将计算出的MeasureSpec传入View的measure方法,这里ViewGroup没有定义测量的具体过程,因为ViewGroup是一个抽象类,其测量过程的onMeasure方法需要各个子类去实现。不同的ViewGroup子类有不同的布局特性,这导致它们的测量细节各不相同,如果需要自定义测量过程,则子类可以重写这个方法。(setMeasureDimension方法用于设置View的测量宽高,如果View没有重写onMeasure方法,则会默认调用getDefaultSize来获得View的宽高)
getSuggestMinimumWidth分析
如果View没有设置背景,那么返回android:minWidth这个属性所指定的值,这个值可以为0;如果View设置了背景,则返回android:minWidth和背景的最小宽度这两者中的最大值。
自定义View时手动处理wrap_content时的情形
直接继承View的控件需要重写onMeasure方法并设置wrap_content时的自身大小,否则在布局中使用wrap_content就相当于使用match_parent。此时,可以在wrap_content的情况下(对应MeasureSpec.AT_MOST)指定内部宽/高(mWidth和mHeight)。
LinearLayout的onMeasure方法实现解析(这里仅分析measureVertical核心源码)
系统会遍历子元素并对每个子元素执行measureChildBeforeLayout方法,这个方法内部会调用子元素的measure方法,这样各个子元素就开始依次进入measure过程,并且系统会通过mTotalLength这个变量来存储LinearLayout在竖直方向的初步高度。每测量一个子元素,mTotalLength就会增加,增加的部分主要包括了子元素的高度以及子元素在竖直方向上的margin等。
在Activity中获取某个View的宽高
由于View的measure过程和Activity的生命周期方法不是同步执行的,如果View还没有测量完毕,那么获得的宽/高就是0。所以在onCreate、onStart、onResume中均无法正确得到某个View的宽高信息。解决方式如下:
- Activity/View#onWindowFocusChanged:此时View已经初始化完毕,当Activity的窗口得到焦点和失去焦点时均会被调用一次,如果频繁地进行onResume和onPause,那么onWindowFocusChanged也会被频繁地调用。
- view.post(runnable): 通过post可以将一个runnable投递到消息队列的尾部,始化好了然后等待Looper调用次runnable的时候,View也已经初始化好了。
- ViewTreeObserver#addOnGlobalLayoutListener:当View树的状态发生改变或者View树内部的View的可见性发生改变时,onGlobalLayout方法将被回调。
- View.measure(int widthMeasureSpec, int heightMeasureSpec):match_parent时不知道parentSize的大小,测不出;具体数值时,直接makeMeasureSpec固定值,然后调用view..measure就可以了;wrap_content时,在最大化模式下,用View理论上能支持的最大值去构造MeasureSpec是合理的。
View的绘制流程之Layout
首先,会通过setFrame方法来设定View的四个顶点的位置,即View在父容器中的位置。然后,会执行到onLayout空方法,子类如果是ViewGroup类型,则重写这个方法,实现ViewGroup中所有View控件布局流程。
LinearLayout的onLayout方法实现解析(layoutVertical核心源码)
其中会遍历调用每个子View的setChildFrame方法为子元素确定对应的位置。其中的childTop会逐渐增大,意味着后面的子元素会被放置在靠下的位置。
注意:在View的默认实现中,View的测量宽/高和最终宽/高是相等的,只不过测量宽/高形成于View的measure过程,而最终宽/高形成于View的layout过程,即两者的赋值时机不同,测量宽/高的赋值时机稍微早一些。在一些特殊的情况下则两者不相等:
- 重写View的layout方法,使最终宽度总是比测量宽/高大100px。
- View需要多次measure才能确定自己的测量宽/高,在前几次测量的过程中,其得出的测量宽/高有可能和最终宽/高不一致,但最终来说,测量宽/高还是和最终宽/高相同。
View的绘制流程之Draw
Draw的基本流程
绘制基本上可以分为六个步骤:
- 首先绘制View的背景;
- 如果需要的话,保持canvas的图层,为fading做准备;
- 然后,绘制View的内容;
- 接着,绘制View的子View;
- 如果需要的话,绘制View的fading边缘并恢复图层;
- 最后,绘制View的装饰(例如滚动条等等)。
setWillNotDraw的作用
如果一个View不需要绘制任何内容,那么设置这个标记位为true以后,系统会进行相应的优化。
- 默认情况下,View没有启用这个优化标记位,但是ViewGroup会默认启用这个优化标记位。
- 当我们的自定义控件继承于ViewGroup并且本身不具备绘制功能时,就可以开启这个标记位从而便于系统进行后续的优化。
- 当明确知道一个ViewGroup需要通过onDraw来绘制内容时,我们需要显示地关闭WILL_NOT_DRAW这个标记位。
Requestlayout,onlayout,onDraw,DrawChild区别与联系?
requestLayout()方法 :会导致调用 measure()过程 和 layout()过程,将会根据标志位判断是否需要ondraw。
onLayout()方法:如果该View是ViewGroup对象,需要实现该方法,对每个子视图进行布局。
onDraw()方法:绘制视图本身 (每个View都需要重载该方法,ViewGroup不需要实现该方法)。
drawChild():去重新回调每个子视图的draw()方法。
invalidate() 和 postInvalidate()的区别 ?
invalidate()与postInvalidate()都用于刷新View,主要区别是invalidate()在主线程中调用,若在子线程中使用需要配合handler;而postInvalidate()可在子线程中直接调用。
更详细的内容请点击这里
4、跨进程通信。
Android中进程和线程的关系?区别?
- 线程是CPU调度的最小单元,同时线程是一种有限的系统资源;而进程一般指一个执行单元,在PC和移动设备上指一个程序或者一个应用。
- 一般来说,一个App程序至少有一个进程,一个进程至少有一个线程(包含与被包含的关系),通俗来讲就是,在App这个工厂里面有一个进程,线程就是里面的生产线,但主线程(即主生产线)只有一条,而子线程(即副生产线)可以有多个。
- 进程有自己独立的地址空间,而进程中的线程共享此地址空间,都可以并发执行。
如何开启多进程?应用是否可以开启N个进程?
在AndroidManifest中给四大组件指定属性android:process开启多进程模式,在内存允许的条件下可以开启N个进程。
为何需要IPC?多进程通信可能会出现的问题?
所有运行在不同进程的四大组件(Activity、Service、Receiver、ContentProvider)共享数据都会失败,这是由于Android为每个应用分配了独立的虚拟机,不同的虚拟机在内存分配上有不同的地址空间,这会导致在不同的虚拟机中访问同一个类的对象会产生多份副本。比如常用例子(通过开启多进程获取更大内存空间、两个或者多个应用之间共享数据、微信全家桶)。
一般来说,使用多进程通信会造成如下几方面的问题:
- 静态成员和单例模式完全失效:独立的虚拟机造成。
- 线程同步机制完全失效:独立的虚拟机造成。
- SharedPreferences的可靠性下降:这是因为Sp不支持两个进程并发进行读写,有一定几率导致数据丢失。
- Application会多次创建:Android系统在创建新的进程时会分配独立的虚拟机,所以这个过程其实就是启动一个应用的过程,自然也会创建新的Application。
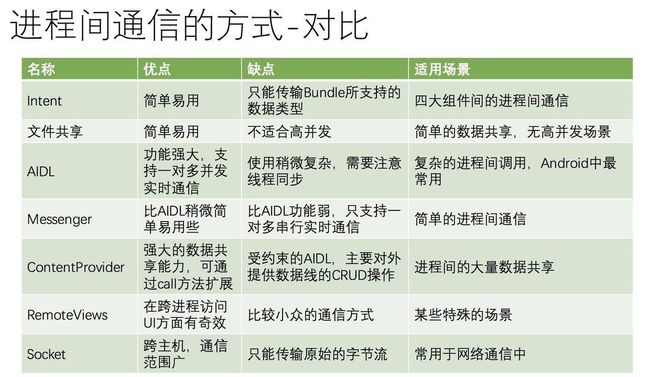
Android中IPC方式、各种方式优缺点?
讲讲AIDL?如何优化多模块都使用AIDL的情况?
AIDL(Android Interface Definition Language,Android接口定义语言):如果在一个进程中要调用另一个进程中对象的方法,可使用AIDL生成可序列化的参数,AIDL会生成一个服务端对象的代理类,通过它客户端可以实现间接调用服务端对象的方法。
AIDL的本质是系统提供了一套可快速实现Binder的工具。关键类和方法:
- AIDL接口:继承IInterface。
- Stub类:Binder的实现类,服务端通过这个类来提供服务。
- Proxy类:服务端的本地代理,客户端通过这个类调用服务端的方法。
- asInterface():客户端调用,将服务端返回的Binder对象,转换成客户端所需要的AIDL接口类型的对象。如果客户端和服务端位于同一进程,则直接返回Stub对象本身,否则返回系统封装后的Stub.proxy对象。
- asBinder():根据当前调用情况返回代理Proxy的Binder对象。
- onTransact():运行在服务端的Binder线程池中,当客户端发起跨进程请求时,远程请求会通过系统底层封装后交由此方法来处理。
- transact():运行在客户端,当客户端发起远程请求的同时将当前线程挂起。之后调用服务端的onTransact()直到远程请求返回,当前线程才继续执行。
当有多个业务模块都需要AIDL来进行IPC,此时需要为每个模块创建特定的aidl文件,那么相应的Service就会很多。必然会出现系统资源耗费严重、应用过度重量级的问题。解决办法是建立Binder连接池,即将每个业务模块的Binder请求统一转发到一个远程Service中去执行,从而避免重复创建Service。
工作原理:每个业务模块创建自己的AIDL接口并实现此接口,然后向服务端提供自己的唯一标识和其对应的Binder对象。服务端只需要一个Service并提供一个queryBinder接口,它会根据业务模块的特征来返回相应的Binder对象,不同的业务模块拿到所需的Binder对象后就可以进行远程方法的调用了。
为什么选择Binder?
为什么选用Binder,在讨论这个问题之前,我们知道Android也是基于Linux内核,Linux现有的进程通信手段有以下几种:
- 管道:在创建时分配一个page大小的内存,缓存区大小比较有限;
- 消息队列:信息复制两次,额外的CPU消耗;不合适频繁或信息量大的通信;
- 共享内存:无须复制,共享缓冲区直接附加到进程虚拟地址空间,速度快;但进程间的同步问题操作系统无法实现,必须各进程利用同步工具解决;
- 套接字:作为更通用的接口,传输效率低,主要用于不同机器或跨网络的通信;
- 信号量:常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。 不适用于信息交换,更适用于进程中断控制,比如非法内存访问,杀死某个进程等;
既然有现有的IPC方式,为什么重新设计一套Binder机制呢。主要是出于以上三个方面的考量:
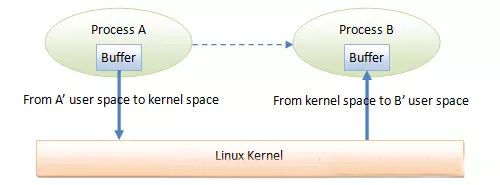
- 1、效率:传输效率主要影响因素是内存拷贝的次数,拷贝次数越少,传输速率越高。从Android进程架构角度分析:对于消息队列、Socket和管道来说,数据先从发送方的缓存区拷贝到内核开辟的缓存区中,再从内核缓存区拷贝到接收方的缓存区,一共两次拷贝,如图:
而对于Binder来说,数据从发送方的缓存区拷贝到内核的缓存区,而接收方的缓存区与内核的缓存区是映射到同一块物理地址的,节省了一次数据拷贝的过程,如图:
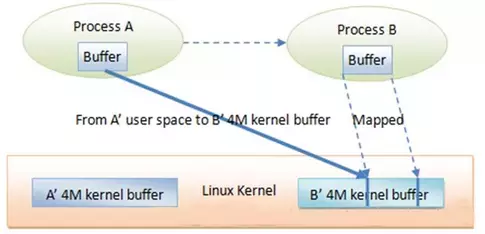
共享内存不需要拷贝,Binder的性能仅次于共享内存。
- 2、稳定性:上面说到共享内存的性能优于Binder,那为什么不采用共享内存呢,因为共享内存需要处理并发同步问题,容易出现死锁和资源竞争,稳定性较差。Socket虽然是基于C/S架构的,但是它主要是用于网络间的通信且传输效率较低。Binder基于C/S架构 ,Server端与Client端相对独立,稳定性较好。
- 3、安全性:传统Linux IPC的接收方无法获得对方进程可靠的UID/PID,从而无法鉴别对方身份;而Binder机制为每个进程分配了UID/PID,且在Binder通信时会根据UID/PID进行有效性检测。
Binder机制的作用和原理?
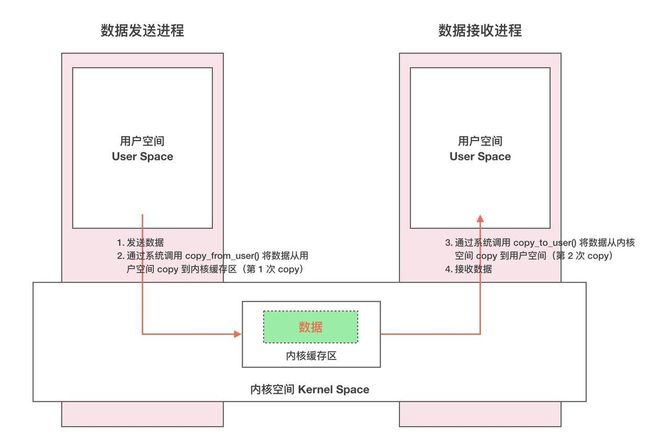
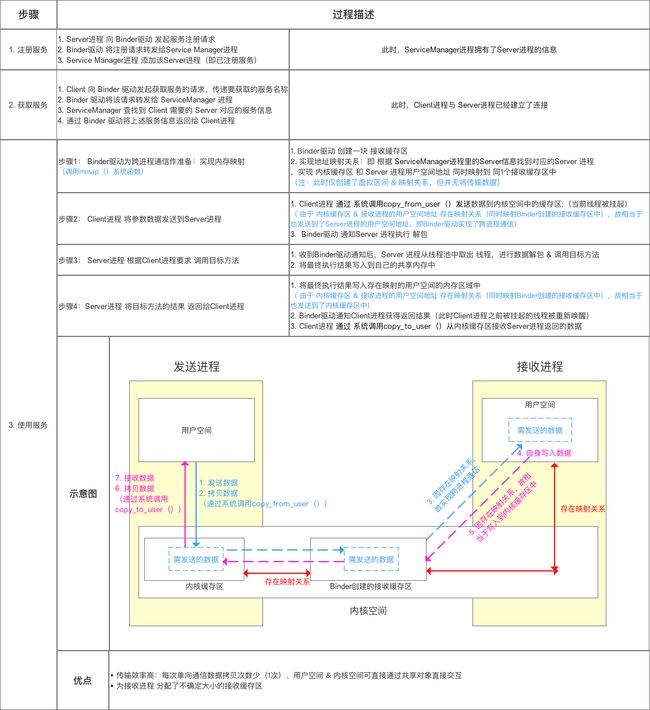
Linux系统将一个进程分为用户空间和内核空间。对于进程之间来说,用户空间的数据不可共享,内核空间的数据可共享,为了保证安全性和独立性,一个进程不能直接操作或者访问另一个进程,即Android的进程是相互独立、隔离的,这就需要跨进程之间的数据通信方式。普通的跨进程通信方式一般需要2次内存拷贝,如下图所示:
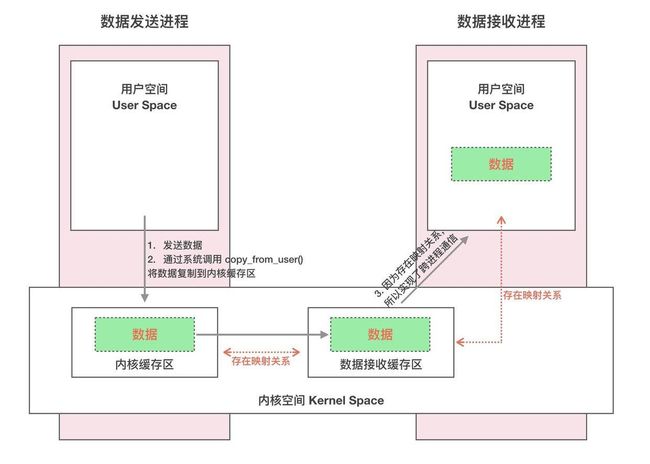
一次完整的 Binder IPC 通信过程通常是这样:
- 首先 Binder 驱动在内核空间创建一个数据接收缓存区。
- 接着在内核空间开辟一块内核缓存区,建立内核缓存区和内核中数据接收缓存区之间的映射关系,以及内核中数据接收缓存区和接收进程用户空间地址的映射关系。
- 发送方进程通过系统调用 copyfromuser() 将数据 copy 到内核中的内核缓存区,由于内核缓存区和接收进程的用户空间存在内存映射,因此也就相当于把数据发送到了接收进程的用户空间,这样便完成了一次进程间的通信。
Binder框架中ServiceManager的作用?
Binder框架 是基于 C/S 架构的。由一系列的组件组成,包括 Client、Server、ServiceManager、Binder驱动,其中 Client、Server、Service Manager 运行在用户空间,Binder 驱动运行在内核空间。如下图所示:
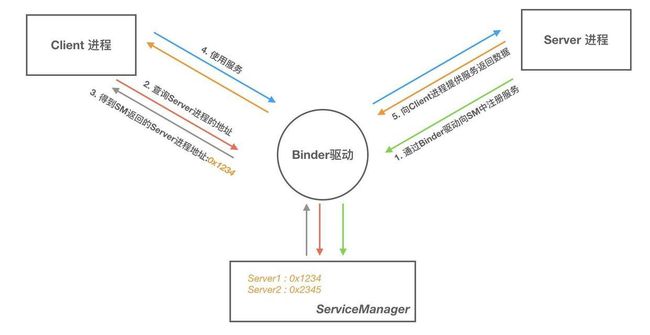
- Server&Client:服务器&客户端。在Binder驱动和Service Manager提供的基础设施上,进行Client-Server之间的通信。
- ServiceManager(如同DNS域名服务器)服务的管理者,将Binder名字转换为Client中对该Binder的引用,使得Client可以通过Binder名字获得Server中Binder实体的引用。
- Binder驱动(如同路由器):负责进程之间binder通信的建立,计数管理以及数据的传递交互等底层支持。
最后,结合Android跨进程通信:图文详解 Binder机制 的总结图来综合理解一下:
Binder 的完整定义
- 从进程间通信的角度看,Binder 是一种进程间通信的机制;
- 从 Server 进程的角度看,Binder 指的是 Server 中的 Binder 实体对象;
- 从 Client 进程的角度看,Binder 指的是 Binder 代理对象,是 Binder 实体对象的一个远程代理;
- 从传输过程的角度看,Binder 是一个可以跨进程传输的对象;Binder 驱动会对这个跨越进程边界的对象对一点点特殊处理,自动完成代理对象和本地对象之间的转换。
手写实现简化版AMS(AIDL实现)
与Binder相关的几个类的职责:
- IBinder:跨进程通信的Base接口,它声明了跨进程通信需要实现的一系列抽象方法,实现了这个接口就说明可以进行跨进程通信,Client和Server都要实现此接口。
- IInterface:这也是一个Base接口,用来表示Server提供了哪些能力,是Client和Server通信的协议。
- Binder:提供Binder服务的本地对象的基类,它实现了IBinder接口,所有本地对象都要继承这个类。
- BinderProxy:在Binder.java这个文件中还定义了一个BinderProxy类,这个类表示Binder代理对象它同样实现了IBinder接口,不过它的很多实现都交由native层处理。Client中拿到的实际上是这个代理对象。
- Stub:这个类在编译aidl文件后自动生成,它继承自Binder,表示它是一个Binder本地对象;它是一个抽象类,实现了IInterface接口,表明它的子类需要实现Server将要提供的具体能力(即aidl文件中声明的方法)。
- Proxy:它实现了IInterface接口,说明它是Binder通信过程的一部分;它实现了aidl中声明的方法,但最终还是交由其中的mRemote成员来处理,说明它是一个代理对象,mRemote成员实际上就是BinderProxy。
aidl文件只是用来定义C/S交互的接口,Android在编译时会自动生成相应的Java类,生成的类中包含了Stub和Proxy静态内部类,用来封装数据转换的过程,实际使用时只关心具体的Java接口类即可。为什么Stub和Proxy是静态内部类呢?这其实只是为了将三个类放在一个文件中,提高代码的聚合性。通过上面的分析,我们其实完全可以不通过aidl,手动编码来实现Binder的通信,下面我们通过编码来实现ActivityManagerService:
1、首先定义IActivityManager接口:
public interface IActivityManager extends IInterface {
//binder描述符
String DESCRIPTOR = "android.app.IActivityManager";
//方法编号
int TRANSACTION_startActivity = IBinder.FIRST_CALL_TRANSACTION + 0;
//声明一个启动activity的方法,为了简化,这里只传入intent参数
int startActivity(Intent intent) throws RemoteException;
}
2、然后,实现ActivityManagerService侧的本地Binder对象基类:
// 名称随意,不一定叫Stub
public abstract class ActivityManagerNative extends Binder implements IActivityManager {
public static IActivityManager asInterface(IBinder obj) {
if (obj == null) {
return null;
}
IActivityManager in = (IActivityManager) obj.queryLocalInterface(IActivityManager.DESCRIPTOR);
if (in != null) {
return in;
}
//代理对象,见下面的代码
return new ActivityManagerProxy(obj);
}
@Override
public IBinder asBinder() {
return this;
}
@Override
protected boolean onTransact(int code, Parcel data, Parcel reply, int flags) throws RemoteException {
switch (code) {
// 获取binder描述符
case INTERFACE_TRANSACTION:
reply.writeString(IActivityManager.DESCRIPTOR);
return true;
// 启动activity,从data中反序列化出intent参数后,直接调用子类startActivity方法启动activity。
case IActivityManager.TRANSACTION_startActivity:
data.enforceInterface(IActivityManager.DESCRIPTOR);
Intent intent = Intent.CREATOR.createFromParcel(data);
int result = this.startActivity(intent);
reply.writeNoException();
reply.writeInt(result);
return true;
}
return super.onTransact(code, data, reply, flags);
}
}
3、接着,实现Client侧的代理对象:
public class ActivityManagerProxy implements IActivityManager {
private IBinder mRemote;
public ActivityManagerProxy(IBinder remote) {
mRemote = remote;
}
@Override
public IBinder asBinder() {
return mRemote;
}
@Override
public int startActivity(Intent intent) throws RemoteException {
Parcel data = Parcel.obtain();
Parcel reply = Parcel.obtain();
int result;
try {
// 将intent参数序列化,写入data中
intent.writeToParcel(data, 0);
// 调用BinderProxy对象的transact方法,交由Binder驱动处理。
mRemote.transact(IActivityManager.TRANSACTION_startActivity, data, reply, 0);
reply.readException();
// 等待server执行结束后,读取执行结果
result = reply.readInt();
} finally {
data.recycle();
reply.recycle();
}
return result;
}
}
4、最后,实现Binder本地对象(IActivityManager接口):
public class ActivityManagerService extends ActivityManagerNative {
@Override
public int startActivity(Intent intent) throws RemoteException {
// 启动activity
return 0;
}
}
简化版的ActivityManagerService到这里就已经实现了,剩下就是Client只需要获取到AMS的代理对象IActivityManager就可以通信了。
请按顺序仔细阅读下列文章提升对Binder机制的理解程度:
写给 Android 应用工程师的 Binder 原理剖析
Binder学习指南
Binder设计与实现
老罗Binder机制分析系列或Android系统源代码情景分析Binder章节
5、Android系统启动流程是什么?(提示:init进程 -> Zygote进程 –> SystemServer进程 –> 各种系统服务 –> 应用进程)
Android系统启动的核心流程如下:
- 1、启动电源以及系统启动:当电源按下时引导芯片从预定义的地方(固化在ROM)开始执行,加载引导程序BootLoader到RAM,然后执行。
- 2、引导程序BootLoader:BootLoader是在Android系统开始运行前的一个小程序,主要用于把系统OS拉起来并运行。
- 3、Linux内核启动:当内核启动时,设置缓存、被保护存储器、计划列表、加载驱动。当其完成系统设置时,会先在系统文件中寻找init.rc文件,并启动init进程。
- 4、init进程启动:初始化和启动属性服务,并且启动Zygote进程。
- 5、Zygote进程启动:创建JVM并为其注册JNI方法,创建服务器端Socket,启动SystemServer进程。
- 6、SystemServer进程启动:启动Binder线程池和SystemServiceManager,并且启动各种系统服务。
- 7、Launcher启动:被SystemServer进程启动的AMS会启动Launcher,Launcher启动后会将已安装应用的快捷图标显示到系统桌面上。
需要更详细的分析请查看以下系列文章:
Android系统启动流程之init进程启动
Android系统启动流程之Zygote进程启动
Android系统启动流程之SystemServer进程启动
Android系统启动流程之Launcher进程启动
6、启动一个程序,可以主界面点击图标进入,也可以从一个程序中跳转过去,二者有什么区别?
是因为启动程序(主界面也是一个app),发现了在这个程序中存在一个设置为的activity, 所以这个launcher会把icon提出来,放在主界面上。当用户点击icon的时候,发出一个Intent:
Intent intent = mActivity.getPackageManager().getLaunchIntentForPackage(packageName);
mActivity.startActivity(intent);
跳过去可以跳到任意允许的页面,如一个程序可以下载,那么真正下载的页面可能不是首页(也有可能是首页),这时还是构造一个Intent,startActivity。这个intent中的action可能有多种view,download都有可能。系统会根据第三方程序向系统注册的功能,为你的Intent选择可以打开的程序或者页面。所以唯一的一点 不同的是从icon的点击启动的intent的action是相对单一的,从程序中跳转或者启动可能样式更多一些。本质是相同的。
7、AMS家族重要术语解释。
1.ActivityManagerServices,简称AMS,服务端对象,负责系统中所有Activity的生命周期。
2.ActivityThread,App的真正入口。当开启App之后,调用main()开始运行,开启消息循环队列,这就是传说的UI线程或者叫主线程。与ActivityManagerService一起完成Activity的管理工作。
3.ApplicationThread,用来实现ActivityManagerServie与ActivityThread之间的交互。在ActivityManagerSevice需要管理相关Application中的Activity的生命周期时,通过ApplicationThread的代理对象与ActivityThread通信。
4.ApplicationThreadProxy,是ApplicationThread在服务器端的代理,负责和客户端的ApplicationThread通信。AMS就是通过该代理与ActivityThread进行通信的。
5.Instrumentation,每一个应用程序只有一个Instrumetation对象,每个Activity内都有一个对该对象的引用,Instrumentation可以理解为应用进程的管家,ActivityThread要创建或暂停某个Activity时,都需要通过Instrumentation来进行具体的操作。
6.ActivityStack,Activity在AMS的栈管理,用来记录经启动的Activity的先后关系,状态信息等。通过ActivtyStack决定是否需要启动新的进程。
7.ActivityRecord,ActivityStack的管理对象,每个Acivity在AMS对应一个ActivityRecord,来记录Activity状态以及其他的管理信息。其实就是服务器端的Activit对象的映像。
8.TaskRecord,AMS抽象出来的一个“任务”的概念,是记录ActivityRecord的栈,一个“Task”包含若干个ActivityRecord。AMS用TaskRecord确保Activity启动和退出的顺序。如果你清楚Activity的4种launchMode,那么对这概念应该不陌生。
8、App启动流程(Activity的冷启动流程)。
点击应用图标后会去启动应用的Launcher Activity,如果Launcer Activity所在的进程没有创建,还会创建新进程,整体的流程就是一个Activity的启动流程。
Activity的启动流程图(放大可查看)如下所示:
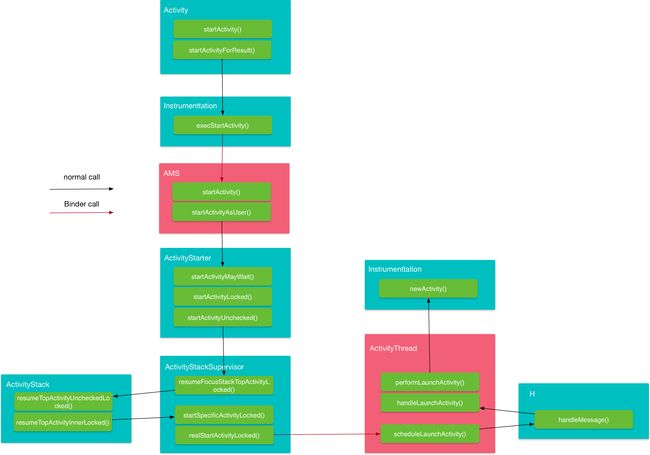
整个流程涉及的主要角色有:
- Instrumentation: 监控应用与系统相关的交互行为。
- AMS:组件管理调度中心,什么都不干,但是什么都管。
- ActivityStarter:Activity启动的控制器,处理Intent与Flag对Activity启动的影响,具体说来有:1 寻找符合启动条件的Activity,如果有多个,让用户选择;2 校验启动参数的合法性;3 返回int参数,代表Activity是否启动成功。
- ActivityStackSupervisior:这个类的作用你从它的名字就可以看出来,它用来管理任务栈。
- ActivityStack:用来管理任务栈里的Activity。
- ActivityThread:最终干活的人,Activity、Service、BroadcastReceiver的启动、切换、调度等各种操作都在这个类里完成。
注:这里单独提一下ActivityStackSupervisior,这是高版本才有的类,它用来管理多个ActivityStack,早期的版本只有一个ActivityStack对应着手机屏幕,后来高版本支持多屏以后,就有了多个ActivityStack,于是就引入了ActivityStackSupervisior用来管理多个ActivityStack。
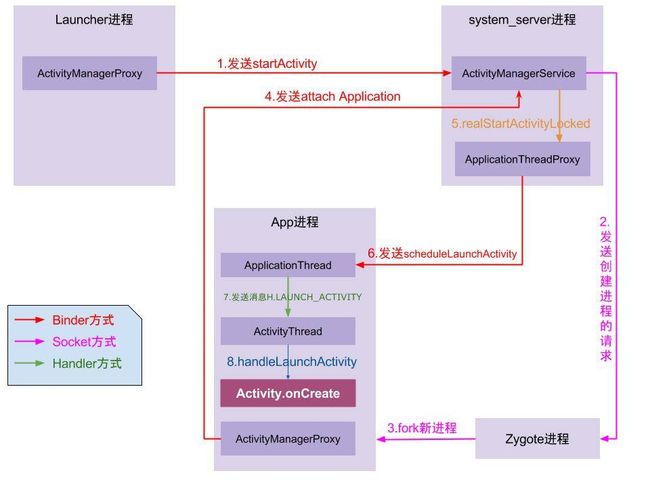
整个流程主要涉及四个进程:
- 调用者进程,如果是在桌面启动应用就是Launcher应用进程。
- ActivityManagerService等待所在的System Server进程,该进程主要运行着系统服务组件。
- Zygote进程,该进程主要用来fork新进程。
- 新启动的应用进程,该进程就是用来承载应用运行的进程了,它也是应用的主线程(新创建的进程就是主线程),处理组件生命周期、界面绘制等相关事情。
有了以上的理解,整个流程可以概括如下:
- 1、点击桌面应用图标,Launcher进程将启动Activity(MainActivity)的请求以Binder的方式发送给了AMS。
- 2、AMS接收到启动请求后,交付ActivityStarter处理Intent和Flag等信息,然后再交给ActivityStackSupervisior/ActivityStack 处理Activity进栈相关流程。同时以Socket方式请求Zygote进程fork新进程。
- 3、Zygote接收到新进程创建请求后fork出新进程。
- 4、在新进程里创建ActivityThread对象,新创建的进程就是应用的主线程,在主线程里开启Looper消息循环,开始处理创建Activity。
- 5、ActivityThread利用ClassLoader去加载Activity、创建Activity实例,并回调Activity的onCreate()方法,这样便完成了Activity的启动。
最后,再看看另一幅启动流程图来加深理解:
9、ActivityThread工作原理。
10、说下四大组件的启动过程,四大组件的启动与销毁的方式。
广播发送和接收的原理了解吗?
- 继承BroadcastReceiver,重写onReceive()方法。
- 通过Binder机制向ActivityManagerService注册广播。
- 通过Binder机制向ActivityMangerService发送广播。
- ActivityManagerService查找符合相应条件的广播(IntentFilter/Permission)的BroadcastReceiver,将广播发送到BroadcastReceiver所在的消息队列中。
- BroadcastReceiver所在消息队列拿到此广播后,回调它的onReceive()方法。
11、AMS是如何管理Activity的?
12、理解Window和WindowManager。
1.Window用于显示View和接收各种事件,Window有三种型:应用Window(每个Activity对应一个Window)、子Widow(不能单独存在,附属于特定Window)、系统window(toast和状态栏)
2.Window分层级,应用Window在1-99、子Window在1000-1999、系统Window在2000-2999.WindowManager提供了增改View的三个功能。
3.Window是个抽象概念:每一个Window对应着一个ViewRootImpl,Window通过ViewRootImpl来和View建立联系,View是Window存在的实体,只能通过WindowManager来访问Window。
4.WindowManager的实现是WindowManagerImpl,其再委托WindowManagerGlobal来对Window进行操作,其中有四种List分别储存对应的View、ViewRootImpl、WindowManger.LayoutParams和正在被删除的View。
5.Window的实体是存在于远端的WindowMangerService,所以增删改Window在本端是修改上面的几个List然后通过ViewRootImpl重绘View,通过WindowSession(每Window个对应一个)在远端修改Window。
6.Activity创建Window:Activity会在attach()中创建Window并设置其回调(onAttachedToWindow()、dispatchTouchEvent()),Activity的Window是由Policy类创建PhoneWindow实现的。然后通过Activity#setContentView()调用PhoneWindow的setContentView。
13、WMS是如何管理Window的?
14、大体说清一个应用程序安装到手机上时发生了什么?
APK的安装流程如下所示:
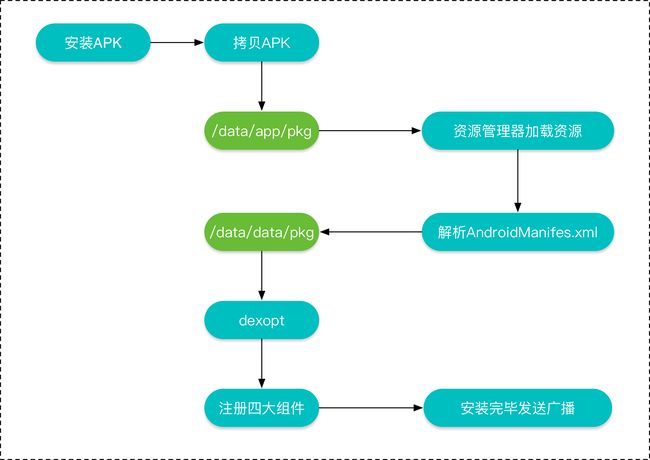
复制APK到/data/app目录下,解压并扫描安装包。
资源管理器解析APK里的资源文件。
解析AndroidManifest文件,并在/data/data/目录下创建对应的应用数据目录。
然后对dex文件进行优化,并保存在dalvik-cache目录下。
将AndroidManifest文件解析出的四大组件信息注册到PackageManagerService中。
安装完成后,发送广播。
15、Android的打包流程?(即描述清点击 Android Studio 的 build 按钮后发生了什么?)apk里有哪些东西?签名算法的原理?
apk打包流程
Android的包文件APK分为两个部分:代码和资源,所以打包方面也分为资源打包和代码打包两个方面,下面就来分析资源和代码的编译打包原理。
APK整体的的打包流程如下图所示:
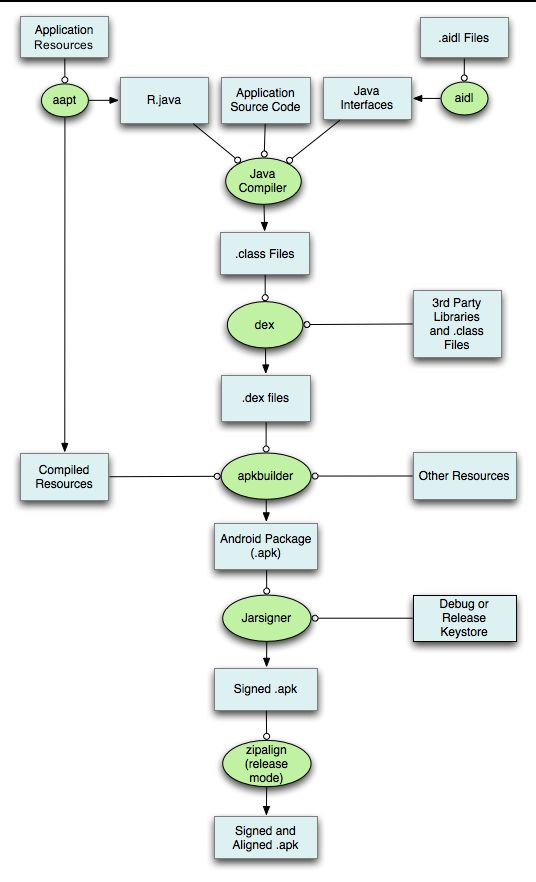
具体说来:
- 通过AAPT工具进行资源文件(包括AndroidManifest.xml、布局文件、各种xml资源等)的打包,生成R.java文件。
- 通过AIDL工具处理AIDL文件,生成相应的Java文件。
- 通过Java Compiler编译R.java、Java接口文件、Java源文件,生成.class文件。
- 通过dex命令,将.class文件和第三方库中的.class文件处理生成classes.dex,该过程主要完成Java字节码转换成Dalvik字节码,压缩常量池以及清除冗余信息等工作。
- 通过ApkBuilder工具将资源文件、DEX文件打包生成APK文件。
- 通过Jarsigner工具,利用KeyStore对生成的APK文件进行签名。
- 如果是正式版的APK,还会利用ZipAlign工具进行对齐处理,对齐的过程就是将APK文件中所有的资源文件距离文件的起始距位置都偏移4字节的整数倍,这样通过内存映射访问APK文件的速度会更快,并且会减少其在设备上运行时的内存占用。
apk组成
- dex:最终生成的Dalvik字节码。
- res:存放资源文件的目录。
- asserts:额外建立的资源文件夹。
- lib:如果存在的话,存放的是ndk编出来的so库。
- META-INF:存放签名信息
MANIFEST.MF(清单文件):其中每一个资源文件都有一个SHA-256-Digest签名,MANIFEST.MF文件的SHA256(SHA1)并base64编码的结果即为CERT.SF中的SHA256-Digest-Manifest值。
CERT.SF(待签名文件):除了开头处定义的SHA256(SHA1)-Digest-Manifest值,后面几项的值是对MANIFEST.MF文件中的每项再次SHA256并base64编码后的值。
CERT.RSA(签名结果文件):其中包含了公钥、加密算法等信息。首先对前一步生成的MANIFEST.MF使用了SHA256(SHA1)-RSA算法,用开发者私钥签名,然后在安装时使用公钥解密。最后,将其与未加密的摘要信息(MANIFEST.MF文件)进行对比,如果相符,则表明内容没有被修改。
- androidManifest:程序的全局清单配置文件。
- resources.arsc:编译后的二进制资源文件。
签名算法的原理
为什么要签名?
- 确保Apk来源的真实性。
- 确保Apk没有被第三方篡改。
什么是签名?
在Apk中写入一个“指纹”。指纹写入以后,Apk中有任何修改,都会导致这个指纹无效,Android系统在安装Apk进行签名校验时就会不通过,从而保证了安全性。
数字摘要
对一个任意长度的数据,通过一个Hash算法计算后,都可以得到一个固定长度的二进制数据,这个数据就称为“摘要”。
补充:
- 散列算法的基础原理:将数据(如一段文字)运算变为另一固定长度值。
- SHA-1:在密码学中,SHA-1(安全散列算法1)是一种加密散列函数,它接受输入并产生一个160 位(20 字节)散列值,称为消息摘要 。
- MD5:MD5消息摘要算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传输完整一致。
- SHA-2:名称来自于安全散列算法2(英语:Secure Hash Algorithm 2)的缩写,一种密码散列函数算法标准,其下又可再分为六个不同的算法标准,包括了:SHA-224、SHA-256、SHA-384、SHA-512、SHA-512/224、SHA-512/256。
特征:
- 唯一性
- 固定长度:比较常用的Hash算法有MD5和SHA1,MD5的长度是128拉,SHA1的长度是160位。
- 不可逆性
签名和校验的主要过程
签名就是在摘要的基础上再进行一次加密,对摘要加密后的数据就可以当作数字签名。
签名过程:
- 1、计算摘要:通过Hash算法提取出原始数据的摘要。
- 2、计算签名:再通过基于密钥(私钥)的非对称加密算法对提取出的摘要进行加密,加密后的数据就是签名信息。
- 3、写入签名:将签名信息写入原始数据的签名区块内。
校验过程:
- 1、首先用同样的Hash算法从接收到的数据中提取出摘要。
- 2、解密签名:使用发送方的公钥对数字签名进行解密,解密出原始摘要。
- 3、比较摘要:如果解密后的数据和提取的摘要一致,则校验通过;如果数据被第三方篡改过,解密后的数据和摘要将会不一致,则校验不通过。
数字证书
如何保证公钥的可靠性呢?答案是数字证书,数字证书是身份认证机构(Certificate Authority)颁发的,包含了以下信息:
- 证书颁发机构
- 证书颁发机构签名
- 证书绑定的服务器域名
- 证书版本、有效期
- 签名使用的加密算法(非对称算法,如RSA)
- 公钥等
接收方收到消息后,先向CA验证证书的合法性,再进行签名校验。
注意:Apk的证书通常是自签名的,也就是由开发者自己制作,没有向CA机构申请。Android在安装Apk时并没有校验证书本身的合法性,只是从证书中提取公钥和加密算法,这也正是对第三方Apk重新签名后,还能够继续在没有安装这个Apk的系统中继续安装的原因。
keystore和证书格式
keystore文件中包含了私钥、公钥和数字证书。根据编码不同,keystore文件分为很多种,Android使用的是Java标准keystore格式JKS(Java Key Storage),所以通过Android Studio导出的keystore文件是以.jks结尾的。
keystore使用的证书标准是X.509,X.509标准也有多种编码格式,常用的有两种:pem(Privacy Enhanced Mail)和der(Distinguished Encoding Rules)。jks使用的是der格式,Android也支持直接使用pem格式的证书进行签名。
两种证书编码格式的区别:
- DER(Distinguished Encoding Rules)
二进制格式,所有类型的证书和私钥都可以存储为der格式。
- PEM(Privacy Enhanced Mail)
base64编码,内容以-----BEGIN xxx----- 开头,以-----END xxx----- 结尾。
jarsigner和apksigner的区别
Android提供了两种对Apk的签名方式,一种是基于JAR的签名方式,另一种是基于Apk的签名方式,它们的主要区别在于使用的签名文件不一样:jarsigner使用keystore文件进行签名;apksigner除了支持使用keystore文件进行签名外,还支持直接指定pem证书文件和私钥进行签名。
在签名时,除了要指定keystore文件和密码外,也要指定alias和key的密码,这是为什么呢?
keystore是一个密钥库,也就是说它可以存储多对密钥和证书,keystore的密码是用于保护keystore本身的,一对密钥和证书是通过alias来区分的。所以jarsigner是支持使用多个证书对Apk进行签名的,apksigner也同样支持。
Android Apk V1 签名原理
- 1、解析出 CERT.RSA 文件中的证书、公钥,解密 CERT.RSA 中的加密数据。
- 2、解密结果和 CERT.SF 的指纹进行对比,保证 CERT.SF 没有被篡改。
- 3、而 CERT.SF 中的内容再和 MANIFEST.MF 指纹对比,保证 MANIFEST.MF 文件没有被篡改。
- 4、MANIFEST.MF 中的内容和 APK 所有文件指纹逐一对比,保证 APK 没有被篡改。
16、说下安卓虚拟机和java虚拟机的原理和不同点?(JVM、Davilk、ART三者的原理和区别)
JVM 和Dalvik虚拟机的区别
JVM:.java -> javac -> .class -> jar -> .jar
架构: 堆和栈的架构.
DVM:.java -> javac -> .class -> dx.bat -> .dex
架构: 寄存器(cpu上的一块高速缓存)
Android2个虚拟机的区别(一个5.0之前,一个5.0之后)
什么是Dalvik:Dalvik是Google公司自己设计用于Android平台的Java虚拟机。Dalvik虚拟机是Google等厂商合作开发的Android移动设备平台的核心组成部分之一,它可以支持已转换为.dex(即Dalvik Executable)格式的Java应用程序的运行,.dex格式是专为Dalvik应用设计的一种压缩格式,适合内存和处理器速度有限的系统。Dalvik经过优化,允许在有限的内存中同时运行多个虚拟机的实例,并且每一个Dalvik应用作为独立的Linux进程执行。独立的进程可以防止在虚拟机崩溃的时候所有程序都被关闭。
什么是ART:Android操作系统已经成熟,Google的Android团队开始将注意力转向一些底层组件,其中之一是负责应用程序运行的Dalvik运行时。Google开发者已经花了两年时间开发更快执行效率更高更省电的替代ART运行时。ART代表Android Runtime,其处理应用程序执行的方式完全不同于Dalvik,Dalvik是依靠一个Just-In-Time(JIT)编译器去解释字节码。开发者编译后的应用代码需要通过一个解释器在用户的设备上运行,这一机制并不高效,但让应用能更容易在不同硬件和架构上运行。ART则完全改变了这套做法,在应用安装的时候就预编译字节码为机器语言,这一机制叫Ahead-Of-Time(AOT)编译。在移除解释代码这一过程后,应用程序执行将更有效率,启动更快。
ART优点:
- 系统性能的显著提升。
- 应用启动更快、运行更快、体验更流畅、触感反馈更及时。
- 更长的电池续航能力。
- 支持更低的硬件。
ART缺点:
- 更大的存储空间占用,可能会增加10%-20%。
- 更长的应用安装时间。
17、安卓采用自动垃圾回收机制,请说下安卓内存管理的原理?
18、Android中App是如何沙箱化的,为何要这么做?
19、一个图片在app中调用R.id后是如何找到的?
20、JNI
Java调用C++
- 在Java中声明Native方法(即需要调用的本地方法)
- 编译上述 Java源文件javac(得到 .class文件) 3。 通过 javah 命令导出JNI的头文件(.h文件)
- 使用 Java需要交互的本地代码 实现在 Java中声明的Native方法
- 编译.so库文件
- 通过Java命令执行 Java程序,最终实现Java调用本地代码
C++调用Java
-
从classpath路径下搜索ClassMethod这个类,并返回该类的Class对象。
-
获取类的默认构造方法ID。
-
查找实例方法的ID。
-
创建该类的实例。
-
调用对象的实例方法。
JNIEXPORT void JNICALL Java_com_study_jnilearn_AccessMethod_callJavaInstaceMethod (JNIEnv *env, jclass cls) { jclass clazz = NULL; jobject jobj = NULL; jmethodID mid_construct = NULL; jmethodID mid_instance = NULL; jstring str_arg = NULL; // 1、从classpath路径下搜索ClassMethod这个类,并返回该类的Class对象 clazz = (*env)->FindClass(env, "com/study/jnilearn/ClassMethod"); if (clazz == NULL) { printf("找不到'com.study.jnilearn.ClassMethod'这个类"); return; } // 2、获取类的默认构造方法ID mid_construct = (*env)->GetMethodID(env,clazz, "","()V"); if (mid_construct == NULL) { printf("找不到默认的构造方法"); return; } // 3、查找实例方法的ID mid_instance = (*env)->GetMethodID(env, clazz, "callInstanceMethod", "(Ljava/lang/String;I)V"); if (mid_instance == NULL) { return; } // 4、创建该类的实例 jobj = (*env)->NewObject(env,clazz,mid_construct); if (jobj == NULL) { printf("在com.study.jnilearn.ClassMethod类中找不到callInstanceMethod方法"); return; } // 5、调用对象的实例方法 str_arg = (*env)->NewStringUTF(env,"我是实例方法"); (*env)->CallVoidMethod(env,jobj,mid_instance,str_arg,200); // 删除局部引用 (*env)->DeleteLocalRef(env,clazz); (*env)->DeleteLocalRef(env,jobj); (*env)->DeleteLocalRef(env,str_arg); }
如何在jni中注册native函数,有几种注册方式?
21、请介绍一下NDK?
三、Android优秀三方库源码
1、你项目中用到哪些开源库?说说其实现原理?
一、网络底层框架:OkHttp实现原理
这个库是做什么用的?
网络底层库,它是基于http协议封装的一套请求客户端,虽然它也可以开线程,但根本上它更偏向真正的请求,跟HttpClient, HttpUrlConnection的职责是一样的。其中封装了网络请求get、post等底层操作的实现。
为什么要在项目中使用这个库?
- OkHttp 提供了对最新的 HTTP 协议版本 HTTP/2 和 SPDY 的支持,这使得对同一个主机发出的所有请求都可以共享相同的套接字连接。
- 如果 HTTP/2 和 SPDY 不可用,OkHttp 会使用连接池来复用连接以提高效率。
- OkHttp 提供了对 GZIP 的默认支持来降低传输内容的大小。
- OkHttp 也提供了对 HTTP 响应的缓存机制,可以避免不必要的网络请求。
- 当网络出现问题时,OkHttp 会自动重试一个主机的多个 IP 地址。
这个库都有哪些用法?对应什么样的使用场景?
get、post请求、上传文件、上传表单等等。
这个库的优缺点是什么,跟同类型库的比较?
- 优点:在上面
- 缺点:使用的时候仍然需要自己再做一层封装。
这个库的核心实现原理是什么?如果让你实现这个库的某些核心功能,你会考虑怎么去实现?
OkHttp内部的请求流程:使用OkHttp会在请求的时候初始化一个Call的实例,然后执行它的execute()方法或enqueue()方法,内部最后都会执行到getResponseWithInterceptorChain()方法,这个方法里面通过拦截器组成的责任链,依次经过用户自定义普通拦截器、重试拦截器、桥接拦截器、缓存拦截器、连接拦截器和用户自定义网络拦截器以及访问服务器拦截器等拦截处理过程,来获取到一个响应并交给用户。其中,除了OKHttp的内部请求流程这点之外,缓存和连接这两部分内容也是两个很重要的点,掌握了这3点就说明你理解了OkHttp。
各个拦截器的作用:
- interceptors:用户自定义拦截器
- retryAndFollowUpInterceptor:负责失败重试以及重定向
- BridgeInterceptor:请求时,对必要的Header进行一些添加,接收响应时,移除必要的Header
- CacheInterceptor:负责读取缓存直接返回(根据请求的信息和缓存的响应的信息来判断是否存在缓存可用)、更新缓存
- ConnectInterceptor:负责和服务器建立连接
ConnectionPool:
1、判断连接是否可用,不可用则从ConnectionPool获取连接,ConnectionPool无连接,创建新连接,握手,放入ConnectionPool。
2、它是一个Deque,add添加Connection,使用线程池负责定时清理缓存。
3、使用连接复用省去了进行 TCP 和 TLS 握手的一个过程。
- networkInterceptors:用户定义网络拦截器
- CallServerInterceptor:负责向服务器发送请求数据、从服务器读取响应数据
你从这个库中学到什么有价值的或者说可借鉴的设计思想?
使用责任链模式实现拦截器的分层设计,每一个拦截器对应一个功能,充分实现了功能解耦,易维护。
手写拦截器?
网络请求缓存处理,okhttp如何处理网络缓存的?
HttpUrlConnection 和 okhttp关系?
Volley与OkHttp的对比:
Volley:支持HTTPS。缓存、异步请求,不支持同步请求。协议类型是Http/1.0, Http/1.1,网络传输使用的是 HttpUrlConnection/HttpClient,数据读写使用的IO。 OkHttp:支持HTTPS。缓存、异步请求、同步请求。协议类型是Http/1.0, Http/1.1, SPDY, Http/2.0, WebSocket,网络传输使用的是封装的Socket,数据读写使用的NIO(Okio)。 SPDY协议类似于HTTP,但旨在缩短网页的加载时间和提高安全性。SPDY协议通过压缩、多路复用和优先级来缩短加载时间。
Okhttp的子系统层级结构图如下所示:

网络配置层:利用Builder模式配置各种参数,例如:超时时间、拦截器等,这些参数都会由Okhttp分发给各个需要的子系统。 重定向层:负责重定向。 Header拼接层:负责把用户构造的请求转换为发送给服务器的请求,把服务器返回的响应转换为对用户友好的响应。 HTTP缓存层:负责读取缓存以及更新缓存。 连接层:连接层是一个比较复杂的层级,它实现了网络协议、内部的拦截器、安全性认证,连接与连接池等功能,但这一层还没有发起真正的连接,它只是做了连接器一些参数的处理。 数据响应层:负责从服务器读取响应的数据。 在整个Okhttp的系统中,我们还要理解以下几个关键角色:
OkHttpClient:通信的客户端,用来统一管理发起请求与解析响应。 Call:Call是一个接口,它是HTTP请求的抽象描述,具体实现类是RealCall,它由CallFactory创建。 Request:请求,封装请求的具体信息,例如:url、header等。 RequestBody:请求体,用来提交流、表单等请求信息。 Response:HTTP请求的响应,获取响应信息,例如:响应header等。 ResponseBody:HTTP请求的响应体,被读取一次以后就会关闭,所以我们重复调用responseBody.string()获取请求结果是会报错的。 Interceptor:Interceptor是请求拦截器,负责拦截并处理请求,它将网络请求、缓存、透明压缩等功能都统一起来,每个功能都是一个Interceptor,所有的Interceptor最 终连接成一个Interceptor.Chain。典型的责任链模式实现。 StreamAllocation:用来控制Connections与Streas的资源分配与释放。 RouteSelector:选择路线与自动重连。 RouteDatabase:记录连接失败的Route黑名单。
自己去设计网络请求框架,怎么做?
从网络加载一个10M的图片,说下注意事项?
http怎么知道文件过大是否传输完毕的响应?
谈谈你对WebSocket的理解?
WebSocket与socket的区别?
二、网络封装框架:Retrofit实现原理
这个库是做什么用的?
Retrofit 是一个 RESTful 的 HTTP 网络请求框架的封装。Retrofit 2.0 开始内置 OkHttp,前者专注于接口的封装,后者专注于网络请求的高效。
为什么要在项目中使用这个库?
1、功能强大:
- 支持同步、异步
- 支持多种数据的解析 & 序列化格式
- 支持RxJava
2、简洁易用:
- 通过注解配置网络请求参数
- 采用大量设计模式简化使用
3、可扩展性好:
- 功能模块高度封装
- 解耦彻底,如自定义Converters
这个库都有哪些用法?对应什么样的使用场景?
任何网络场景都应该优先选择,特别是后台API遵循Restful API设计风格 & 项目中使用到RxJava。
这个库的优缺点是什么,跟同类型库的比较?
- 优点:在上面
- 缺点:扩展性差,高度封装所带来的必然后果,如果服务器不能给出统一的API形式,会很难处理。
这个库的核心实现原理是什么?如果让你实现这个库的某些核心功能,你会考虑怎么去实现?
Retrofit主要是在create方法中采用动态代理模式(通过访问代理对象的方式来间接访问目标对象)实现接口方法,这个过程构建了一个ServiceMethod对象,根据方法注解获取请求方式,参数类型和参数注解拼接请求的链接,当一切都准备好之后会把数据添加到Retrofit的RequestBuilder中。然后当我们主动发起网络请求的时候会调用okhttp发起网络请求,okhttp的配置包括请求方式,URL等在Retrofit的RequestBuilder的build()方法中实现,并发起真正的网络请求。
你从这个库中学到什么有价值的或者说可借鉴的设计思想?
内部使用了优秀的架构设计和大量的设计模式,在我分析过Retrofit最新版的源码和大量优秀的Retrofit源码分析文章后,我发现,要想真正理解Retrofit内部的核心源码流程和设计思想,首先,需要对它使用到的九大设计模式有一定的了解,下面我简单说一说:
1、创建Retrofit实例:
- 使用建造者模式通过内部Builder类建立了一个Retroift实例。
- 网络请求工厂使用了工厂方法模式。
2、创建网络请求接口的实例:
- 首先,使用外观模式统一调用创建网络请求接口实例和网络请求参数配置的方法。
- 然后,使用动态代理动态地去创建网络请求接口实例。
- 接着,使用了建造者模式 & 单例模式创建了serviceMethod对象。
- 再者,使用了策略模式对serviceMethod对象进行网络请求参数配置,即通过解析网络请求接口方法的参数、返回值和注解类型,从Retrofit对象中获取对应的网络的url地址、网络请求执行器、网络请求适配器和数据转换器。
- 最后,使用了装饰者模式ExecuteCallBack为serviceMethod对象加入线程切换的操作,便于接受数据后通过Handler从子线程切换到主线程从而对返回数据结果进行处理。
3、发送网络请求:
- 在异步请求时,通过静态delegate代理对网络请求接口的方法中的每个参数使用对应的ParameterHanlder进行解析。
4、解析数据
5、切换线程:
- 使用了适配器模式通过检测不同的Platform使用不同的回调执行器,然后使用回调执行器切换线程,这里同样是使用了装饰模式。
6、处理结果
Android:主流网络请求开源库的对比(Android-Async-Http、Volley、OkHttp、Retrofit)
https://www.jianshu.com/p/050c6db5af5a
三、响应式编程框架:RxJava实现原理
RxJava中map和flatmap操作符的区别及底层实现
手写rxjava遍历数组。
你认为Rxjava的线程池与你们自己实现任务管理框架有什么区别?
四、图片加载框架:Glide实现原理
这个库是做什么用的?
Glide是Android中的一个图片加载库,用于实现图片加载。
为什么要在项目中使用这个库?
1、多样化媒体加载:不仅可以进行图片缓存,还支持Gif、WebP、缩略图,甚至是Video。
2、通过设置绑定生命周期:可以使加载图片的生命周期动态管理起来。
3、高效的缓存策略:支持内存、Disk缓存,并且Picasso只会缓存原始尺寸的图片,内Glide缓存的是多种规格,也就是Glide会根据你ImageView的大小来缓存相应大小的图片尺寸。
4、内存开销小:默认的Bitmap格式是RGB_565格式,而Picasso默认的是ARGB_8888格式,内存开销小一半。
这个库都有哪些用法?对应什么样的使用场景?
1、图片加载:Glide.with(this).load(imageUrl).override(800, 800).placeholder().error().animate().into()。
2、多样式媒体加载:asBitamp、asGif。
3、生命周期集成。
4、可以配置磁盘缓存策略ALL、NONE、SOURCE、RESULT。
这个库的优缺点是什么,跟同类型库的比较?
库比较大,源码实现复杂。
这个库的核心实现原理是什么?如果让你实现这个库的某些核心功能,你会考虑怎么去实现?
- Glide&with:
1、初始化各式各样的配置信息(包括缓存,请求线程池,大小,图片格式等等)以及glide对象。
2、将glide请求和application/SupportFragment/Fragment的生命周期绑定在一块。
- Glide&load:
设置请求url,并记录url已设置的状态。
3、Glide&into:
1、首先根据转码类transcodeClass类型返回不同的ImageViewTarget:BitmapImageViewTarget、DrawableImageViewTarget。
2、递归建立缩略图请求,没有缩略图请求,则直接进行正常请求。
3、如果没指定宽高,会根据ImageView的宽高计算出图片宽高,最终执行到onSizeReay()方法中的engine.load()方法。
4、engine是一个负责加载和管理缓存资源的类
- 常规三级缓存的流程:强引用->软引用->硬盘缓存
当我们的APP中想要加载某张图片时,先去LruCache中寻找图片,如果LruCache中有,则直接取出来使用,如果LruCache中没有,则去SoftReference中寻找(软引用适合当cache,当内存吃紧的时候才会被回收。而weakReference在每次system.gc()就会被回收)(当LruCache存储紧张时,会把最近最少使用的数据放到SoftReference中),如果SoftReference中有,则从SoftReference中取出图片使用,同时将图片重新放回到LruCache中,如果SoftReference中也没有图片,则去硬盘缓存中中寻找,如果有则取出来使用,同时将图片添加到LruCache中,如果没有,则连接网络从网上下载图片。图片下载完成后,将图片保存到硬盘缓存中,然后放到LruCache中。
- Glide的三层缓存机制:
Glide缓存机制大致分为三层:内存缓存、弱引用缓存、磁盘缓存。
取的顺序是:内存、弱引用、磁盘。
存的顺序是:弱引用、内存、磁盘。
三层存储的机制在Engine中实现的。先说下Engine是什么?Engine这一层负责加载时做管理内存缓存的逻辑。持有MemoryCache、Map
需要一个图片资源,如果Lrucache中有相应的资源图片,那么就返回,同时从Lrucache中清除,放到activeResources中。activeResources map是盛放正在使用的资源,以弱引用的形式存在。同时资源内部有被引用的记录。如果资源没有引用记录了,那么再放回Lrucache中,同时从activeResources中清除。如果Lrucache中没有,就从activeResources中找,找到后相应资源引用加1。如果Lrucache和activeResources中没有,那么进行资源异步请求(网络/diskLrucache),请求成功后,资源放到diskLrucache和activeResources中。
Glide源码机制的核心思想:
使用一个弱引用map activeResources来盛放项目中正在使用的资源。Lrucache中不含有正在使用的资源。资源内部有个计数器来显示自己是不是还有被引用的情况,把正在使用的资源和没有被使用的资源分开有什么好处呢??因为当Lrucache需要移除一个缓存时,会调用resource.recycle()方法。注意到该方法上面注释写着只有没有任何consumer引用该资源的时候才可以调用这个方法。那么为什么调用resource.recycle()方法需要保证该资源没有任何consumer引用呢?glide中resource定义的recycle()要做的事情是把这个不用的资源(假设是bitmap或drawable)放到bitmapPool中。bitmapPool是一个bitmap回收再利用的库,在做transform的时候会从这个bitmapPool中拿一个bitmap进行再利用。这样就避免了重新创建bitmap,减少了内存的开支。而既然bitmapPool中的bitmap会被重复利用,那么肯定要保证回收该资源的时候(即调用资源的recycle()时),要保证该资源真的没有外界引用了。这也是为什么glide花费那么多逻辑来保证Lrucache中的资源没有外界引用的原因。
你从这个库中学到什么有价值的或者说可借鉴的设计思想?
Glide的高效的三层缓存机制,如上。
Glide如何确定图片加载完毕?
Glide使用什么缓存?
Glide内存缓存如何控制大小?
计算一张图片的大小
图片占用内存的计算公式:图片高度 * 图片宽度 * 一个像素占用的内存大小。所以,计算图片占用内存大小的时候,要考虑图片所在的目录跟设备密度,这两个因素其实影响的是图片的宽高,android会对图片进行拉升跟压缩。
加载bitmap过程(怎样保证不产生内存溢出)
由于Android对图片使用内存有限制,若是加载几兆的大图片便内存溢出。Bitmap会将图片的所有像素(即长x宽)加载到内存中,如果图片分辨率过大,会直接导致内存OOM,只有在BitmapFactory加载图片时使用BitmapFactory.Options对相关参数进行配置来减少加载的像素。
BitmapFactory.Options相关参数详解:
(1).Options.inPreferredConfig值来降低内存消耗。
比如:默认值ARGB_8888改为RGB_565,节约一半内存。
(2).设置Options.inSampleSize 缩放比例,对大图片进行压缩 。
(3).设置Options.inPurgeable和inInputShareable:让系统能及时回收内存。
A:inPurgeable:设置为True时,表示系统内存不足时可以被回收,设置为False时,表示不能被回收。
B:inInputShareable:设置是否深拷贝,与inPurgeable结合使用,inPurgeable为false时,该参数无意义。
(4).使用decodeStream代替decodeResource等其他方法。
Android中软引用与弱引用的应用场景。
Java 引用类型分类:
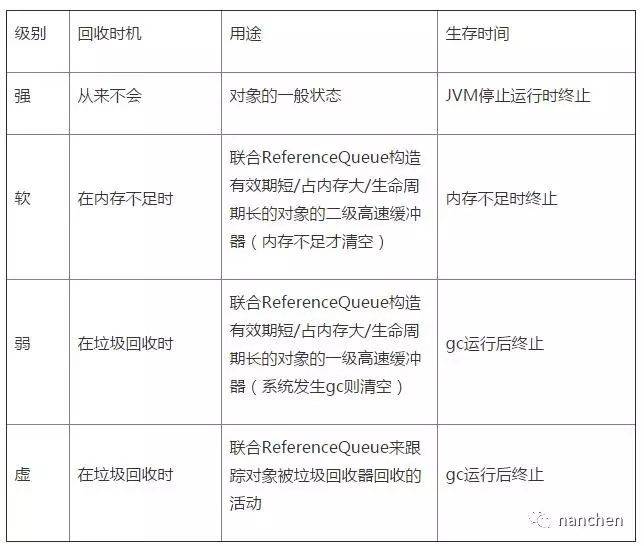
在 Android 应用的开发中,为了防止内存溢出,在处理一些占用内存大而且生命周期较长的对象时候,可以尽量应用软引用和弱引用技术。
- 1、软/弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收器回收,Java 虚拟机就会把这个软引用加入到与之关联的引用队列中。利用这个队列可以得知被回收的软/弱引用的对象列表,从而为缓冲器清除已失效的软 / 弱引用。
- 2、如果只是想避免 OOM 异常的发生,则可以使用软引用。如果对于应用的性能更在意,想尽快回收一些占用内存比较大的对象,则可以使用弱引用。
- 3、可以根据对象是否经常使用来判断选择软引用还是弱引用。如果该对象可能会经常使用的,就尽量用软引用。如果该对象不被使用的可能性更大些,就可以用弱引用。
Android里的内存缓存和磁盘缓存是怎么实现的。
内存缓存基于LruCache实现,磁盘缓存基于DiskLruCache实现。这两个类都基于Lru算法和LinkedHashMap来实现。
LRU算法可以用一句话来描述,如下所示:
LRU是Least Recently Used的缩写,最近最少使用算法,从它的名字就可以看出,它的核心原则是如果一个数据在最近一段时间没有使用到,那么它在将来被访问到的可能性也很小,则这类数据项会被优先淘汰掉。
LruCache原理
之前,我们会使用内存缓存技术实现,也就是软引用或弱引用,在Android 2.3(APILevel 9)开始,垃圾回收器会更倾向于回收持有软引用或弱引用的对象,这让软引用和弱引用变得不再可靠。
其实LRU缓存的实现类似于一个特殊的栈,把访问过的元素放置到栈顶(若栈中存在,则更新至栈顶;若栈中不存在则直接入栈),然后如果栈中元素数量超过限定值,则删除栈底元素(即最近最少使用的元素)。
它的内部存在一个 LinkedHashMap 和 maxSize,把最近使用的对象用强引用存储在 LinkedHashMap 中,给出来 put 和 get 方法,每次 put 图片时计算缓存中所有图片的总大小,跟 maxSize 进行比较,大于 maxSize,就将最久添加的图片移除,反之小于 maxSize 就添加进来。
LruCache的原理就是利用LinkedHashMap持有对象的强引用,按照Lru算法进行对象淘汰。具体说来假设我们从表尾访问数据,在表头删除数据,当访问的数据项在链表中存在时,则将该数据项移动到表尾,否则在表尾新建一个数据项。当链表容量超过一定阈值,则移除表头的数据。
详细来说就是LruCache中维护了一个集合LinkedHashMap,该LinkedHashMap是以访问顺序排序的。当调用put()方法时,就会在结合中添加元素,并调用trimToSize()判断缓存是否已满,如果满了就用LinkedHashMap的迭代器删除队头元素,即近期最少访问的元素。当调用get()方法访问缓存对象时,就会调用LinkedHashMap的get()方法获得对应集合元素,同时会更新该元素到队尾。
LruCache put方法核心逻辑
在添加过缓存对象后,调用trimToSize()方法,来判断缓存是否已满,如果满了就要删除近期最少使用的对象。trimToSize()方法不断地删除LinkedHashMap中队头的元素,即近期最少访问的,直到缓存大小小于最大值(maxSize)。
LruCache get方法核心逻辑
当调用LruCache的get()方法获取集合中的缓存对象时,就代表访问了一次该元素,将会更新队列,保持整个队列是按照访问顺序排序的。
为什么会选择LinkedHashMap呢?
这跟LinkedHashMap的特性有关,LinkedHashMap的构造函数里有个布尔参数accessOrder,当它为true时,LinkedHashMap会以访问顺序为序排列元素,否则以插入顺序为序排序元素。
LinkedHashMap原理
LinkedHashMap 几乎和 HashMap 一样:从技术上来说,不同的是它定义了一个 Entry
DisLruCache原理
DiskLruCache与LruCache原理相似,只是多了一个journal文件来做磁盘文件的管理,如下所示:
libcore.io.DiskLruCache
1
1
1
DIRTY 1517126350519
CLEAN 1517126350519 5325928
REMOVE 1517126350519
注:这里的缓存目录是应用的缓存目录/data/data/pckagename/cache,未root的手机可以通过以下命令进入到该目录中或者将该目录整体拷贝出来:
//进入/data/data/pckagename/cache目录
adb shell
run-as com.your.packagename
cp /data/data/com.your.packagename/
//将/data/data/pckagename目录拷贝出来
adb backup -noapk com.your.packagename
我们来分析下这个文件的内容:
第一行:libcore.io.DiskLruCache,固定字符串。 第二行:1,DiskLruCache源码版本号。 第三行:1,App的版本号,通过open()方法传入进去的。 第四行:1,每个key对应几个文件,一般为1. 第五行:空行 第六行及后续行:缓存操作记录。 第六行及后续行表示缓存操作记录,关于操作记录,我们需要了解以下三点:
DIRTY 表示一个entry正在被写入。写入分两种情况,如果成功会紧接着写入一行CLEAN的记录;如果失败,会增加一行REMOVE记录。注意单独只有DIRTY状态的记录是非法的。 当手动调用remove(key)方法的时候也会写入一条REMOVE记录。 READ就是说明有一次读取的记录。 CLEAN的后面还记录了文件的长度,注意可能会一个key对应多个文件,那么就会有多个数字。
Bitmap 压缩策略
加载 Bitmap 的方式:
BitmapFactory 四类方法:
- decodeFile( 文件系统 )
- decodeResourece( 资源 )
- decodeStream( 输入流 )
- decodeByteArray( 字节数 )
BitmapFactory.options 参数:
- inSampleSize 采样率,对图片高和宽进行缩放,以最小比进行缩放(一般取值为 2 的指数)。通常是根据图片宽高实际的大小/需要的宽高大小,分别计算出宽和高的缩放比。但应该取其中最小的缩放比,避免缩放图片太小,到达指定控件中不能铺满,需要拉伸从而导致模糊。
- inJustDecodeBounds 获取图片的宽高信息,交给 inSampleSize 参数选择缩放比。通过 inJustDecodeBounds = true,然后加载图片就可以实现只解析图片的宽高信息,并不会真正的加载图片,所以这个操作是轻量级的。当获取了宽高信息,计算出缩放比后,然后在将 inJustDecodeBounds = false,再重新加载图片,就可以加载缩放后的图片。
高效加载 Bitmap 的流程:
- 1、将 BitmapFactory.Options 的 inJustDecodeBounds 参数设为 true 并加载图片
- 2、从 BitmapFactory.Options 中取出图片原始的宽高信息,对应于 outWidth 和 outHeight 参数
- 3、根据采样率规则并结合目标 view 的大小计算出采样率 inSampleSize
- 4、将 BitmapFactory.Options 的 inJustDecodeBounds 设置为 false 重新加载图片
Bitmap的处理:
当使用ImageView的时候,可能图片的像素大于ImageView,此时就可以通过BitmapFactory.Option来对图片进行压缩,inSampleSize表示缩小2^(inSampleSize-1)倍。
BitMap的缓存:
1.使用LruCache进行内存缓存。
2.使用DiskLruCache进行硬盘缓存。
实现一个ImageLoader的流程
同步异步加载、图片压缩、内存硬盘缓存、网络拉取
- 1.同步加载只创建一个线程然后按照顺序进行图片加载
- 2.异步加载使用线程池,让存在的加载任务都处于不同线程
- 3.为了不开启过多的异步任务,只在列表静止的时候开启图片加载
具体为:
- 1、ImageLoader作为一个单例,提供了加载图片到指定控件的方法:直接从内存缓存中获取对象,如果没有则用一个ThreadPoolExecutor去执行Runnable任务来加载图片。ThreadPoolExecutor的创建需要指定核心线程数CPU数+1,最大线程数CPU数*2+1,线程闲置超市时长10s,这几个关键数据,还可以加入ThreadFactory参数来创建定制化的线程。
- 2、ImageLoader的具体实现loadBitmap:先从内存缓存LruCache中加载,如果为空再从磁盘缓存中加载,加载成功后记得存入内存缓存,如果为空则从网络中直接下载输出流到磁盘缓存,然后再从磁盘中加载,如果为空并且磁盘缓存没有被创建的话,直接通过BitmapFactory的decodeStream获取网络请求的输入流获取Bitmap对象。
- 3、v4包的LruCache可以兼容到2.2版本,LruCache采用LinkedHashMap存储缓存对象。创建对象只需要提供缓存容量并重写sizeOf方法:作用是计算缓存对象的大小。有时需要重写entryRemoved方法,用于回收一些资源。
- 4、DiskLruCache通过open方法创建,设置缓存路径,缓存容量。缓存添加通过Editor对象创建输出流,下载资源到输出流完成后,commit,如果失败则abort撤回。然后刷新磁盘缓存。缓存查找通过Snapshot对象获取输入流,获取FileDescriptor,通过FileDescriptor解析出Bitmap对象。
- 5、列表中需要加载图片的时候,当列表在滑动中不进行图片加载,当滑动停止后再去加载图片。
Bitmap在decode的时候申请的内存如何复用,释放时机
图片库对比
http://stackoverflow.com/questions/29363321/picasso-v-s-imageloader-v-s-fresco-vs-glide
http://www.trinea.cn/android/android-image-cache-compare/
Fresco与Glide的对比:
Glide:相对轻量级,用法简单优雅,支持Gif动态图,适合用在那些对图片依赖不大的App中。 Fresco:采用匿名共享内存来保存图片,也就是Native堆,有效的的避免了OOM,功能强大,但是库体积过大,适合用在对图片依赖比较大的App中。
Fresco的整体架构如下图所示:
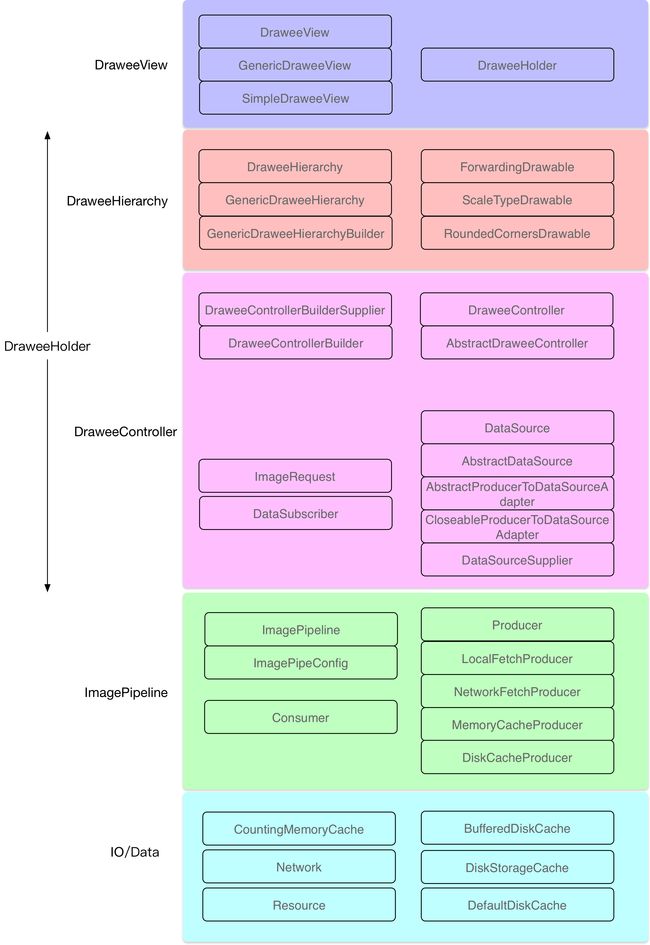
DraweeView:继承于ImageView,只是简单的读取xml文件的一些属性值和做一些初始化的工作,图层管理交由Hierarchy负责,图层数据获取交由负责。 DraweeHierarchy:由多层Drawable组成,每层Drawable提供某种功能(例如:缩放、圆角)。 DraweeController:控制数据的获取与图片加载,向pipeline发出请求,并接收相应事件,并根据不同事件控制Hierarchy,从DraweeView接收用户的事件,然后执行取消网络请求、回收资源等操作。 DraweeHolder:统筹管理Hierarchy与DraweeHolder。 ImagePipeline:Fresco的核心模块,用来以各种方式(内存、磁盘、网络等)获取图像。 Producer/Consumer:Producer也有很多种,它用来完成网络数据获取,缓存数据获取、图片解码等多种工作,它产生的结果由Consumer进行消费。 IO/Data:这一层便是数据层了,负责实现内存缓存、磁盘缓存、网络缓存和其他IO相关的功能。 纵观整个Fresco的架构,DraweeView是门面,和用户进行交互,DraweeHierarchy是视图层级,管理图层,DraweeController是控制器,管理数据。它们构成了整个Fresco框架的三驾马车。当然还有我们 幕后英雄Producer,所有的脏活累活都是它干的,最佳劳模
理解了Fresco整体的架构,我们还有了解在这套矿建里发挥重要作用的几个关键角色,如下所示:
Supplier:提供一种特定类型的对象,Fresco里有很多以Supplier结尾的类都实现了这个接口。 SimpleDraweeView:这个我们就很熟悉了,它接收一个URL,然后调用Controller去加载图片。该类继承于GenericDraweeView,GenericDraweeView又继承于DraweeView,DraweeView是Fresco的顶层View类。 PipelineDraweeController:负责图片数据的获取与加载,它继承于AbstractDraweeController,由PipelineDraweeControllerBuilder构建而来。AbstractDraweeController实现了DraweeController接口,DraweeController 是Fresco的数据大管家,所以的图片数据的处理都是由它来完成的。 GenericDraweeHierarchy:负责SimpleDraweeView上的图层管理,由多层Drawable组成,每层Drawable提供某种功能(例如:缩放、圆角),该类由GenericDraweeHierarchyBuilder进行构建,该构建器 将placeholderImage、retryImage、failureImage、progressBarImage、background、overlays与pressedStateOverlay等 xml文件或者Java代码里设置的属性信息都传入GenericDraweeHierarchy中,由GenericDraweeHierarchy进行处理。 DraweeHolder:该类是一个Holder类,和SimpleDraweeView关联在一起,DraweeView是通过DraweeHolder来统一管理的。而DraweeHolder又是用来统一管理相关的Hierarchy与Controller DataSource:类似于Java里的Futures,代表数据的来源,和Futures不同,它可以有多个result。 DataSubscriber:接收DataSource返回的结果。 ImagePipeline:用来调取获取图片的接口。 Producer:加载与处理图片,它有多种实现,例如:NetworkFetcherProducer,LocalAssetFetcherProducer,LocalFileFetchProducer。从这些类的名字我们就可以知道它们是干什么的。 Producer由ProducerFactory这个工厂类构建的,而且所有的Producer都是像Java的IO流那样,可以一层嵌套一层,最终只得到一个结果,这是一个很精巧的设计 Consumer:用来接收Producer产生的结果,它与Producer组成了生产者与消费者模式。 注:Fresco源码里的类的名字都比较长,但是都是按照一定的命令规律来的,例如:以Supplier结尾的类都实现了Supplier接口,它可以提供某一个类型的对象(factory, generator, builder, closure等)。 以Builder结尾的当然就是以构造者模式创建对象的类。
Bitmap如何处理大图,如一张30M的大图,如何预防OOM?
http://blog.csdn.net/guolin_blog/article/details/9316683
https://blog.csdn.net/lmj623565791/article/details/493009890
使用BitmapRegionDecoder动态加载图片的显示区域。
Bitmap对象的理解
自己去实现图片库,怎么做?(对扩展开发,对修改封闭,同时又保持独立性,参考Android源码设计模式解析实战的图片加载库案例即可)
写个图片浏览器,说出你的思路?
五、事件总线框架:EventBus实现原理
六、内存泄漏检测框架:LeakCanary实现原理
这个库是做什么用?
内存泄露检测框架。
为什么要在项目中使用这个库?
- 针对Android Activity组件完全自动化的内存泄漏检查,在最新的版本中,还加入了android.app.fragment的组件自动化的内存泄漏检测。
- 易用集成,使用成本低。
- 友好的界面展示和通知。
这个库都有哪些用法?对应什么样的使用场景?
直接从application中拿到全局的 refWatcher 对象,在Fragment或其他组件的销毁回调中使用refWatcher.watch(this)检测是否发生内存泄漏。
这个库的优缺点是什么,跟同类型库的比较?
检测结果并不是特别的准确,因为内存的释放和对象的生命周期有关也和GC的调度有关。
这个库的核心实现原理是什么?如果让你实现这个库的某些核心功能,你会考虑怎么去实现?
主要分为如下7个步骤:
- 1、RefWatcher.watch()创建了一个KeyedWeakReference用于去观察对象。
- 2、然后,在后台线程中,它会检测引用是否被清除了,并且是否没有触发GC。
- 3、如果引用仍然没有被清除,那么它将会把堆栈信息保存在文件系统中的.hprof文件里。
- 4、HeapAnalyzerService被开启在一个独立的进程中,并且HeapAnalyzer使用了HAHA开源库解析了指定时刻的堆栈快照文件heap dump。
- 5、从heap dump中,HeapAnalyzer根据一个独特的引用key找到了KeyedWeakReference,并且定位了泄露的引用。
- 6、HeapAnalyzer为了确定是否有泄露,计算了到GC Roots的最短强引用路径,然后建立了导致泄露的链式引用。
- 7、这个结果被传回到app进程中的DisplayLeakService,然后一个泄露通知便展现出来了。
简单来说就是:
在一个Activity执行完onDestroy()之后,将它放入WeakReference中,然后将这个WeakReference类型的Activity对象与ReferenceQueque关联。这时再从ReferenceQueque中查看是否有该对象,如果没有,执行gc,再次查看,还是没有的话则判断发生内存泄露了。最后用HAHA这个开源库去分析dump之后的heap内存(主要就是创建一个HprofParser解析器去解析出对应的引用内存快照文件snapshot)。
流程图:
源码分析中一些核心分析点:
AndroidExcludedRefs:它是一个enum类,它声明了Android SDK和厂商定制的SDK中存在的内存泄露的case,根据AndroidExcludedRefs这个类的类名就可看出这些case都会被Leakcanary的监测过滤掉。
buildAndInstall()(即install方法)这个方法应该仅仅只调用一次。
debuggerControl : 判断是否处于调试模式,调试模式中不会进行内存泄漏检测。为什么呢?因为在调试过程中可能会保留上一个引用从而导致错误信息上报。
watchExecutor : 线程控制器,在 onDestroy() 之后并且主线程空闲时执行内存泄漏检测。
gcTrigger : 用于 GC,watchExecutor 首次检测到可能的内存泄漏,会主动进行 GC,GC 之后会再检测一次,仍然泄漏的判定为内存泄漏,最后根据heapDump信息生成相应的泄漏引用链。
gcTrigger的runGc()方法:这里并没有使用System.gc()方法进行回收,因为system.gc()并不会每次都执行。而是从AOSP中拷贝一段GC回收的代码,从而相比System.gc()更能够保证进行垃圾回收的工作。
Runtime.getRuntime().gc();
子线程延时1000ms;
System.runFinalization();
install方法内部最终还是调用了application的registerActivityLifecycleCallbacks()方法,这样就能够监听activity对应的生命周期事件了。
在RefWatcher#watch()中使用随机的UUID保证了每个检测对象对应的key 的唯一性。
在KeyedWeakReference内部,使用了key和name标识了一个被检测的WeakReference对象。在其构造方法中将弱引用和引用队列 ReferenceQueue 关联起来,如果弱引用reference持有的对象被GC回收,JVM就会把这个弱引用加入到与之关联的引用队列referenceQueue中。即 KeyedWeakReference 持有的 Activity 对象如果被GC回收,该对象就会加入到引用队列 referenceQueue 中。
使用Android SDK的API Debug.dumpHprofData() 来生成 hprof 文件。
在HeapAnalyzerService(类型为IntentService的ForegroundService)的runAnalysis()方法中,为了避免减慢app进程或占用内存,这里将HeapAnalyzerService设置在了一个独立的进程中。
你从这个库中学到什么有价值的或者说可借鉴的设计思想?
BlockCanary原理:
该组件利用了主线程的消息队列处理机制,应用发生卡顿,一定是在dispatchMessage中执行了耗时操作。我们通过给主线程的Looper设置一个Printer,打点统计dispatchMessage方法执行的时间,如果超出阀值,表示发生卡顿,则dump出各种信息,提供开发者分析性能瓶颈。
七、依赖注入框架:ButterKnife实现原理
ButterKnife对性能的影响很小,因为没有使用使用反射,而是使用的Annotation Processing Tool(APT),注解处理器,javac中用于编译时扫描和解析Java注解的工具。在编译阶段执行的,它的原理就是读入Java源代码,解析注解,然后生成新的Java代码。新生成的Java代码最后被编译成Java字节码,注解解析器不能改变读入的Java类,比如不能加入或删除Java方法。
AOP IOC 的好处以及在 Android 开发中的应用
八、依赖全局管理框架:Dagger2实现原理
九、数据库框架:GreenDao实现原理
数据库框架对比?
数据库的优化
数据库数据迁移问题
数据库索引的数据结构
平衡二叉树
- 1、非叶子节点只能允许最多两个子节点存在。
- 2、每一个非叶子节点数据分布规则为左边的子节点小当前节点的值,右边的子节点大于当前节点的值(这里值是基于自己的算法规则而定的,比如hash值)。
- 3、树的左右两边的层级数相差不会大于1。
使用平衡二叉树能保证数据的左右两边的节点层级相差不会大于1.,通过这样避免树形结构由于删除增加变成线性链表影响查询效率,保证数据平衡的情况下查找数据的速度近于二分法查找。
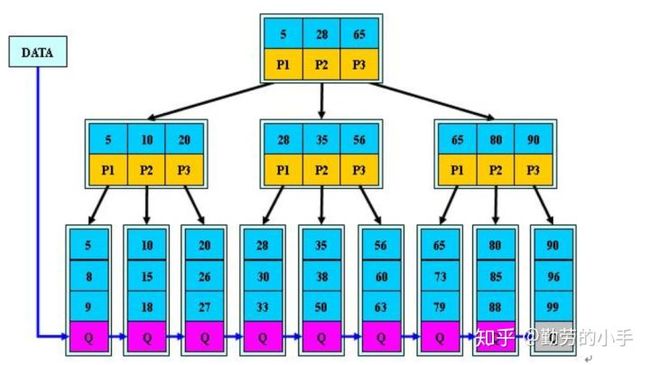
目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构。
B-Tree
B树和平衡二叉树稍有不同的是B树属于多叉树又名平衡多路查找树(查找路径不只两个)。
- 1、排序方式:所有节点关键字是按递增次序排列,并遵循左小右大原则。
- 2、子节点数:非叶节点的子节点数>1,且<=M ,且M>=2,空树除外(注:M阶代表一个树节点最多有多少个查找路径,M=M路,当M=2则是2叉树,M=3则是3叉)。
- 3、关键字数:枝节点的关键字数量大于等于ceil(m/2)-1个且小于等于M-1个(注:ceil()是个朝正无穷方向取整的函数 如ceil(1.1)结果为2)。
- 4、所有叶子节点均在同一层、叶子节点除了包含了关键字和关键字记录的指针外也有指向其子节点的指针只不过其指针地址都为null对应下图最后一层节点的空格子。
B树相对于平衡二叉树的不同是,每个节点包含的关键字增多了,把树的节点关键字增多后树的层级比原来的二叉树少了,减少数据查找的次数和复杂度。
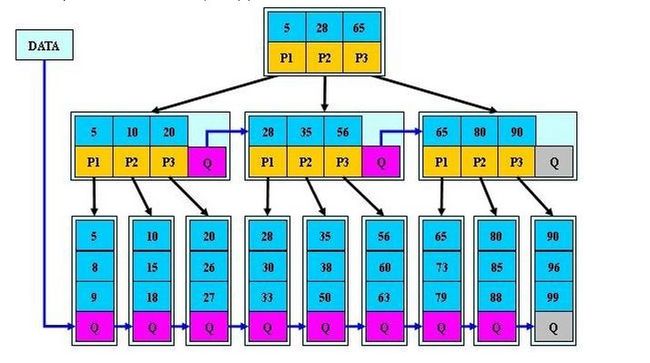
B+Tree
规则:
- 1、B+跟B树不同B+树的非叶子节点不保存关键字记录的指针,只进行数据索引。
- 2、B+树叶子节点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到。所以每次数据查询的次数都一样。
- 3、B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
- 4、非叶子节点的子节点数=关键字数(来源百度百科)(根据各种资料 这里有两种算法的实现方式,另一种为非叶节点的关键字数=子节点数-1(来源维基百科),虽然他们数据排列结构不一样,但其原理还是一样的Mysql 的B+树是用第一种方式实现)。
特点:
1、B+树的层级更少:相较于B树B+每个非叶子节点存储的关键字数更多,树的层级更少所以查询数据更快。
2、B+树查询速度更稳定:B+所有关键字数据地址都存在叶子节点上,所以每次查找的次数都相同所以查询速度要比B树更稳定。
3、B+树天然具备排序功能:B+树所有的叶子节点数据构成了一个有序链表,在查询大小区间的数据时候更方便,数据紧密性很高,缓存的命中率也会比B树高。
4、B+树全节点遍历更快:B+树遍历整棵树只需要遍历所有的叶子节点即可,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
B树相对于B+树的优点是,如果经常访问的数据离根节点很近,而B树的非叶子节点本身存有关键字其数据的地址,所以这种数据检索的时候会要比B+树快。
B*Tree
B*树是B+树的变种,相对于B+树他们的不同之处如下:
-
1、首先是关键字个数限制问题,B+树初始化的关键字初始化个数是cei(m/2),b树的初始化个数为(cei(2/3m))。
-
2、B+树节点满时就会分裂,而B*树节点满时会检查兄弟节点是否满(因为每个节点都有指向兄弟的指针),如果兄弟节点未满则向兄弟节点转移关键字,如果兄弟节点已满,则从当前节点和兄弟节点各拿出1/3的数据创建一个新的节点出来。
在B+树的基础上因其初始化的容量变大,使得节点空间使用率更高,而又存有兄弟节点的指针,可以向兄弟节点转移关键字的特性使得B*树分解次数变得更少。
结论:
- 1、相同思想和策略:从平衡二叉树、B树、B+树、B*树总体来看它们贯彻的思想是相同的,都是采用二分法和数据平衡策略来提升查找数据的速度。
- 2、不同的方式的磁盘空间利用:不同点是他们一个一个在演变的过程中通过IO从磁盘读取数据的原理进行一步步的演变,每一次演变都是为了让节点的空间更合理的运用起来,从而使树的层级减少达到快速查找数据的目的;
还不理解请查看:平衡二叉树、B树、B+树、B*树 理解其中一种你就都明白了。
四、热修复、插件化、模块化、组件化、Gradle
1、热修复和插件化
热修补技术是怎样实现的,和插件化有什么区别?
插件化:动态加载主要解决3个技术问题:
- 1、使用ClassLoader加载类。
- 2、资源访问。
- 3、生命周期管理。
插件化是体现在功能拆分方面的,它将某个功能独立提取出来,独立开发,独立测试,再插入到主应用中。以此来减少主应用的规模。
热修复:
原因:因为一个dvm中存储方法id用的是short类型,导致dex中方法不能超过65536个。
代码热修复原理:
- 将编译好的class文件拆分打包成两个dex,绕过dex方法数量的限制以及安装时的检查,在运行时再动态加载第二个dex文件中。
- 热修复是体现在bug修复方面的,它实现的是不需要重新发版和重新安装,就可以去修复已知的bug。
- 利用PathClassLoader和DexClassLoader去加载与bug类同名的类,替换掉bug类,进而达到修复bug的目的,原理是在app打包的时候阻止类打上CLASS_ISPREVERIFIED标志,然后在热修复的时候动态改变BaseDexClassLoader对象间接引用的dexElements,替换掉旧的类。
相同点:
都使用ClassLoader来实现加载新的功能类,都可以使用PathClassLoader与DexClassLoader。
不同点:
热修复因为是为了修复Bug的,所以要将新的类替代同名的Bug类,要抢先加载新的类而不是Bug类,所以多做两件事:在原先的app打包的时候,阻止相关类去打上CLASS_ISPREVERIFIED标志,还有在热修复时动态改变BaseDexClassLoader对象间接引用的dexElements,这样才能抢先代替Bug类,完成系统不加载旧的Bug类.。 而插件化只是增加新的功能类或者是资源文件,所以不涉及抢先加载新的类这样的使命,就避过了阻止相关类去打上CLASS_ISPREVERIFIED标志和还有在热修复时动态改变BaseDexClassLoader对象间接引用的dexElements.
所以插件化比热修复简单,热修复是在插件化的基础上在进行替换旧的Bug类。
热修复原理:
资源修复:
很多热修复框架的资源修复参考了Instant Run的资源修复的原理。
传统编译部署流程如下:
Instant Run编译部署流程如下:
- Hot Swap:修改一个现有方法中的代码时会采用Hot Swap。
- Warm Swap:修改或删除一个现有的资源文件时会采用Warm Swap。
- Cold Swap:有很多情况,如添加、删除或修改一个字段和方法、添加一个类等。
Instant Run中的资源热修复流程:
- 1、创建新的AssetManager,通过反射调用addAssetPath方法加载外部的资源,这样新创建的AssetManager就含有了外部资源。
- 2、将AssetManager类型的mAssets字段的引用全部替换为新创建的AssetManager。
代码修复:
1、类加载方案:
65536限制:
65536的主要原因是DVM Bytecode的限制,DVM指令集的方法调用指令invoke-kind索引为16bits,最多能引用65535个方法。
LinearAlloc限制:
- DVM中的LinearAlloc是一个固定的缓存区,当方法数超过了缓存区的大小时会报错。
Dex分包方案主要做的是在打包时将应用代码分成多个Dex,将应用启动时必须用到的类和这些类的直接引用类放到Dex中,其他代码放到次Dex中。当应用启动时先加载主Dex,等到应用启动后再动态地加载次Dex,从而缓解了主Dex的65536限制和LinearAlloc限制。
加载流程:
- 根据dex文件的查找流程,我们将有Bug的类Key.class进行修改,再将Key.class打包成包含dex的补丁包Patch.jar,放在Element数组dexElements的第一个元素,这样会首先找到Patch.dex中的Key.class去替换之前存在Bug的Key.class,排在数组后面的dex文件中存在Bug的Key.class根据ClassLoader的双亲委托模式就不会被加载。
类加载方案需要重启App后让ClassLoader重新加载新的类,为什么需要重启呢?
- 这是因为类是无法被卸载的,要想重新加载新的类就需要重启App,因此采用类加载方案的热修复框架是不能即时生效的。
各个热修复框架的实现细节差异:
- QQ空间的超级补丁和Nuwa是按照上面说的将补丁包放在Element数组的第一个元素得到优先加载。
- 微信的Tinker将新旧APK做了diff,得到path.dex,再将patch.dex与手机中APK的classes.dex做合并,生成新的classes.dex,然后在运行时通过反射将classes.dex放在Elements数组的第一个元素。
- 饿了么的Amigo则是将补丁包中每个dex对应的Elements取出来,之后组成新的Element数组,在运行时通过反射用新的Elements数组替换掉现有的Elements数组。
2、底层替换方案:
当我们要反射Key的show方法,会调用Key.class.getDeclaredMethod("show").invoke(Key.class.newInstance());,最终会在native层将传入的javaMethod在ART虚拟机中对应一个ArtMethod指针,ArtMethod结构体中包含了Java方法的所有信息,包括执行入口、访问权限、所属类和代码执行地址等。
替换ArtMethod结构体中的字段或者替换整个ArtMethod结构体,这就是底层替换方案。
AndFix采用的是替换ArtMethod结构体中的字段,这样会有兼容性问题,因为厂商可能会修改ArtMethod结构体,导致方法替换失败。
Sophix采用的是替换整个ArtMethod结构体,这样不会存在兼容问题。
底层替换方案直接替换了方法,可以立即生效不需要重启。采用底层替换方案主要是阿里系为主,包括AndFix、Dexposed、阿里百川、Sophix。
3、Instant Run方案:
什么是ASM?
ASM是一个java字节码操控框架,它能够动态生成类或者增强现有类的功能。ASM可以直接产生class文件,也可以在类被加载到虚拟机之前动态改变类的行为。
Instant Run在第一次构建APK时,使用ASM在每一个方法中注入了类似的代码逻辑:当$change不为null时,则调用它的access$dispatch方法,参数为具体的方法名和方法参数。当MainActivity的onCreate方法做了修改,就会生成替换类MainActivity$override,这个类实现了IncrementalChange接口,同时也会生成一个AppPatchesLoaderImpl类,这个类的getPatchedClasses方法会返回被修改的类的列表(里面包含了MainActivity),根据列表会将MainActivity的$change设置为MainActivity$override。最后这个$change就不会为null,则会执行MainActivity$override的access$dispatch方法,最终会执行onCreate方法,从而实现了onCreate方法的修改。
借鉴Instant Run原理的热修复框架有Robust和Aceso。
动态链接库修复:
重新加载so。
加载so主要用到了System类的load和loadLibrary方法,最终都会调用到nativeLoad方法。其会调用JavaVMExt的LoadNativeLibrary函数来加载so。
so修复主要有两个方案:
- 1、将so补丁插入到NativeLibraryElement数组的前部,让so补丁的路径先被返回和加载。
- 2、调用System的load方法来接管so的加载入口。
为什么选用插件化?
在Android传统开发中,一旦应用的代码被打包成APK并被上传到各个应用市场,我们就不能修改应用的源码了,只能通过服务器来控制应用中预留的分支代码。但是很多时候我们无法预知需求和突然发生的情况,也就不能提前在应用代码中预留分支代码,这时就需要采用动态加载技术,即在程序运行时,动态加载一些程序中原本不存在的可执行文件并运行这些文件里的代码逻辑。其中可执行文件包括动态链接库so和dex相关文件(dex以及包含dex的jar/apk文件)。随着应用开发技术和业务的逐步发展,动态加载技术派生出两个技术:热修复和插件化。其中热修复技术主要用来修复Bug,而插件化技术则主要用于解决应用越来越庞大以及功能模块的解耦。详细点说,就是为了解决以下几种情况:
- 1、业务复杂、模块耦合:随着业务越来越复杂,应用程序的工程和功能模块数量会越来越多,一个应用可能由几十甚至几百人来协同开发,其中的一个工程可能就由一个小组来进行开发维护,如果功能模块间的耦合度较高,修改一个模块会影响其它功能模块,势必会极大地增加沟通成本。
- 2、应用间的接入:当一个应用需要接入其它应用时,如淘宝,为了将流量引流到其它的淘宝应用如:飞猪旅游、口碑外卖、聚划算等等应用,如使用常规技术有两个问题:可能要维护多个版本的问题或单个应用体积将会非常庞大的问题。
- 3、65536限制,内存占用大。
插件化的思想:
安装的应用可以理解为插件,这些插件可以自由地进行插拔。
插件化的定义:
插件一般是指经过处理的APK,so和dex等文件,插件可以被宿主进行加载,有的插件也可以作为APK独立运行。
将一个应用按照插件的方式进行改造的过程就叫作插件化。
插件化的优势:
- 低耦合
- 应用间的接入和维护更便捷,每个应用团队只需要负责自己的那一部分。
- 应用及主dex的体积也会相应变小,间接地避免了65536限制。
- 第一次加载到内存的只有淘宝客户端,当使用到其它插件时才会加载相应插件到内存,以减少内存占用。
插件化框架对比:
- 最早的插件化框架:2012年大众点评的屠毅敏就推出了AndroidDynamicLoader框架。
- 目前主流的插件化方案有滴滴任玉刚的VirtualApk、360的DroidPlugin、RePlugin、Wequick的Small框架。
- 如果加载的插件不需要和宿主有任何耦合,也无须和宿主进行通信,比如加载第三方App,那么推荐使用RePlugin,其他情况推荐使用VirtualApk。由于VirtualApk在加载耦合插件方面是插件化框架的首选,具有普遍的适用性,因此有必要对它的源码进行了解。
插件化原理:
Activity插件化:
主要实现方式有三种:
- 反射:对性能有影响,主流的插件化框架没有采用此方式。
- 接口:dynamic-load-apk采用。
- Hook:主流。
Hook实现方式有两种:Hook IActivityManager和Hook Instrumentation。主要方案就是先用一个在AndroidManifest.xml中注册的Activity来进行占坑,用来通过AMS的校验,接着在合适的时机用插件Activity替换占坑的Activity。
Hook IActivityManager:
1、占坑、通过校验:
在Android 7.0和8.0的源码中IActivityManager借助了Singleton类实现单例,而且该单例是静态的,因此IActivityManager是一个比较好的Hook点。
接着,定义替换IActivityManager的代理类IActivityManagerProxy,由于Hook点IActivityManager是一个接口,建议这里采用动态代理。
- 拦截startActivity方法,获取参数args中保存的Intent对象,它是原本要启动插件TargetActivity的Intent。
- 新建一个subIntent用来启动StubActivity,并将前面得到的TargetActivity的Intent保存到subIntent中,便于以后还原TargetActivity。
- 最后,将subIntent赋值给参数args,这样启动的目标就变为了StubActivity,用来通过AMS的校验。
然后,用代理类IActivityManagerProxy来替换IActivityManager。
- 当版本大于等于26时,使用反射获取ActivityManager的IActivityManagerSingleton字段,小于时则获取ActivityManagerNative中的gDefault字段。
- 然后,通过反射获取对应的Singleton实例,从上面得到的2个字段中拿到对应的IActivityManager。
- 最后,使用Proxy.newProxyInstance()方法动态创建代理类IActivityManagerProxy,用IActivityManagerProxy来替换IActivityManager。
2、还原插件Activity:
- 前面用占坑Activity通过了AMS的校验,但是我们要启动的是插件TargetActivity,还需要用插件TargetActivity来替换占坑的SubActivity,替换时机为图中步骤2之后。
- 在ActivityThread的H类中重写的handleMessage方法会对LAUNCH_ACTIVITY类型的消息进行处理,最终会调用Activity的onCreate方法。在Handler的dispatchMessage处理消息的这个方法中,看到如果Handelr的Callback类型的mCallBack不为null,就会执行mCallback的handleMessage方法,因此mCallback可以作为Hook点。我们可以用自定义的Callback来替换mCallback。
自定义的Callback实现了Handler.Callback,并重写了handleMessage方法,当收到消息的类型为LAUNCH_ACTIVITY时,将启动SubActivity的Intent替换为启动TargetActivity的Intent。然后使用反射将Handler的mCallback替换为自定义的CallBack即可。使用时则在application的attachBaseContext方法中进行hook即可。
3、插件Activity的生命周期:
- AMS和ActivityThread之间的通信采用了token来对Activity进行标识,并且此后的Activity的生命周期处理也是根据token来对Activity进行标识的,因为我们在Activity启动时用插件TargetActivity替换占坑SubActivity,这一过程在performLaunchActivity之前,因此performLaunchActivity的r.token就是TargetActivity。所以TargetActivity具有生命周期。
Hook Instrumentation:
Hook Instrumentation实现同样也需要用到占坑Activity,与Hook IActivity实现不同的是,用占坑Activity替换插件Activity以及还原插件Activity的地方不同。
分析:在Activity通过AMS校验前,会调用Activity的startActivityForResult方法,其中调用了Instrumentation的execStartActivity方法来激活Activity的生命周期。并且在ActivityThread的performLaunchActivity中使用了mInstrumentation的newActivity方法,其内部会用类加载器来创建Activity的实例。
方案:在Instrumentation的execStartActivity方法中用占坑SubActivity来通过AMS的验证,在Instrumentation的newActivity方法中还原TargetActivity,这两部操作都和Instrumentation有关,因此我们可以用自定义的Instumentation来替换掉mInstrumentation。具体为:
- 首先检查TargetActivity是否已经注册,如果没有则将TargetActivity的ClassName保存起来用于后面还原。接着把要启动的TargetActivity替换为StubActivity,最后通过反射调用execStartActivity方法,这样就可以用StubActivity通过AMS的验证。
- 在newActivity方法中创建了此前保存的TargetActivity,完成了还原TargetActivity。最后使用反射用InstrumentationProxy替换mInstumentation。
资源插件化:
资源的插件化和热修复的资源修复都借助了AssetManager。
资源的插件化方案主要有两种:
- 1、合并资源方案,将插件的资源全部添加到宿主的Resources中,这种方案插件可以访问宿主的资源。
- 2、构建插件资源方案,每个插件都构造出独立的Resources,这种方案插件不可以访问宿主资源。
so的插件化:
so的插件化方案和so热修复的第一种方案类似,就是将so插件插入到NativelibraryElement数组中,并且将存储so插件的文件添加到nativeLibraryDirectories集合中就可以了。
插件的加载机制方案:
- 1、Hook ClassLoader。
- 2、委托给系统的ClassLoader帮忙加载。
2、模块化和组件化
模块化的好处
https://www.jianshu.com/p/376ea8a19a17
分析现有的组件化方案:
很多大厂的组件化方案是以 多工程 + 多 Module 的结构(微信, 美团等超级 App 更是以 多工程 + 多 Module + 多 P 工程(以页面为单元的代码隔离方式) 的三级工程结构), 使用 Git Submodule 创建多个子仓库管理各个模块的代码, 并将各个模块的代码打包成 AAR 上传至私有 Maven 仓库使用远程版本号依赖的方式进行模块间代码的隔离。
组件化开发的好处:
- 避免重复造轮子,可以节省开发和维护的成本。
- 可以通过组件和模块为业务基准合理地安排人力,提高开发效率。
- 不同的项目可以共用一个组件或模块,确保整体技术方案的统一性。
- 为未来插件化共用同一套底层模型做准备。
跨组件通信:
跨组件通信场景:
- 第一种是组件之间的页面跳转 (Activity 到 Activity, Fragment 到 Fragment, Activity 到 Fragment, Fragment 到 Activity) 以及跳转时的数据传递 (基础数据类型和可序列化的自定义类类型)。
- 第二种是组件之间的自定义类和自定义方法的调用(组件向外提供服务)。
跨组件通信方案分析:
- 第一种组件之间的页面跳转不需要过多描述了, 算是 ARouter 中最基础的功能, API 也比较简单, 跳转时想传递不同类型的数据也提供有相应的 API。
- 第二种组件之间的自定义类和自定义方法的调用要稍微复杂点, 需要 ARouter 配合架构中的 公共服务(CommonService) 实现:
提供服务的业务模块:
在公共服务(CommonService) 中声明 Service 接口 (含有需要被调用的自定义方法), 然后在自己的模块中实现这个 Service 接口, 再通过 ARouter API 暴露实现类。
使用服务的业务模块:
通过 ARouter 的 API 拿到这个 Service 接口(多态持有, 实际持有实现类), 即可调用 Service 接口中声明的自定义方法, 这样就可以达到模块之间的交互。 此外,可以使用 AndroidEventBus 其独有的 Tag, 可以在开发时更容易定位发送事件和接受事件的代码, 如果以组件名来作为 Tag 的前缀进行分组, 也可以更好的统一管理和查看每个组件的事件, 当然也不建议大家过多使用 EventBus。
如何管理过多的路由表?
RouterHub 存在于基础库, 可以被看作是所有组件都需要遵守的通讯协议, 里面不仅可以放路由地址常量, 还可以放跨组件传递数据时命名的各种 Key 值, 再配以适当注释, 任何组件开发人员不需要事先沟通只要依赖了这个协议, 就知道了各自该怎样协同工作, 既提高了效率又降低了出错风险, 约定的东西自然要比口头上说的强。
Tips: 如果您觉得把每个路由地址都写在基础库的 RouterHub 中, 太麻烦了, 也可以在每个组件内部建立一个私有 RouterHub, 将不需要跨组件的路由地址放入私有 RouterHub 中管理, 只将需要跨组件的路由地址放入基础库的公有 RouterHub 中管理, 如果您不需要集中管理所有路由地址的话, 这也是比较推荐的一种方式。
ARouter路由原理:
ARouter维护了一个路由表Warehouse,其中保存着全部的模块跳转关系,ARouter路由跳转实际上还是调用了startActivity的跳转,使用了原生的Framework机制,只是通过apt注解的形式制造出跳转规则,并人为地拦截跳转和设置跳转条件。
多模块开发的时候不同的负责人可能会引入重复资源,相同的字符串,相同的icon等但是文件名并不一样,怎样去重?
3、gradle
gradle熟悉么,自动打包知道么?
如何加快 Gradle 的编译速度?
Gradle的Flavor能否配置sourceset?
Gradle生命周期
五、设计模式与架构设计
1、设计模式
谈谈你对Android设计模式的理解
项目中常用的设计模式
手写生产者/消费者模式
2、架构设计
MVC MVP MVVM原理和区别?
架构设计的目的
通过设计是模块程序化,从而做到高内聚低耦合,让开发者能更专注于功能实现本身,提供程序开发效率、更容易进行测试、维护和定位问题等等。而且,不同的规模的项目应该选用不同的架构设计。
MVC
MVC是模型(model)-视图(view)-控制器(controller)的缩写,其中M层处理数据,业务逻辑等;V层处理界面的显示结果;C层起到桥梁的作用,来控制V层和M层通信以此来达到分离视图显示和业务逻辑层。在Android中的MVC划分是这样的:
- 视图层(View):一般采用XML文件进行界面的描述,也可以在界面中使用动态布局的方式。
- 控制层(Controller):由Activity承担。
- 模型层(Model):数据库的操作、对网络等的操作,复杂业务计算等等。
MVC缺点
在Android开发中,Activity并不是一个标准的MVC模式中的Controller,它的首要职责是加载应用的布局和初始化用户界面,并接受和处理来自用户的操作请求,进而作出响应。随着界面及其逻辑的复杂度不断提升,Activity类的职责不断增加,以致变得庞大臃肿。
MVP
MVP框架由3部分组成:View负责显示,Presenter负责逻辑处理,Model提供数据。
- View:负责绘制UI元素、与用户进行交互(在Android中体现为Activity)。
- Model:负责存储、检索、操纵数据(有时也实现一个Model interface用来降低耦合)。
- Presenter:作为View与Model交互的中间纽带,处理与用户交互的逻辑。
- View interface:需要View实现的接口,View通过View interface与Presenter进行交互,降低耦合,方便使用MOCK对Presenter进行单元测试。
MVP的Presenter是框架的控制者,承担了大量的逻辑操作,而MVC的Controller更多时候承担一种转发的作用。因此在App中引入MVP的原因,是为了将此前在Activty中包含的大量逻辑操作放到控制层中,避免Activity的臃肿。
MVP与MVC的主要区别:
- 1、(最主要区别)View与Model并不直接交互,而是通过与Presenter交互来与Model间接交互。而在MVC中View可以与Model直接交互。
- 2、Presenter与View的交互是通过接口来进行的,更有利于添加单元测试。
MVP的优点
- 1、模型与视图完全分离,我们可以修改视图而不影响模型。
- 2、可以更高效地使用模型,因为所有的交互都发生在一个地方——Presenter内部。
- 3、我们可以将一个Presenter用于多个视图,而不需要改变Presenter的逻辑。这个特性非常的有用,因为视图的变化总是比模型的变化频繁。
- 4、如果我们把逻辑放在Presenter中,那么我们就可以脱离用户接口来测试这些逻辑(单元测试)。
UI层一般包括Activity,Fragment,Adapter等直接和UI相关的类,UI层的Activity在启动之后实例化相应的Presenter,App的控制权后移,由UI转移到Presenter,两者之间的通信通过BroadCast、Handler、事件总线机制或者接口完成,只传递事件和结果。
MVP的执行流程:首先V层通知P层用户发起了一个网络请求,P层会决定使用负责网络相关的M层去发起请求网络,最后,P层将完成的结果更新到V层。
MVP的变种:Passive View
View直接依赖Presenter,但是Presenter间接依赖View,它直接依赖的是View实现的接口。相对于View的被动,那Presenter就是主动的一方。对于Presenter的主动,有如下的理解:
- Presenter是整个MVP体系的控制中心,而不是单纯的处理View请求的人。
- View仅仅是用户交互请求的汇报者,对于响应用户交互相关的逻辑和流程,View不参与决策,真正的决策者是Presenter。
- View向Presenter发送用户交互请求应该采用这样的口吻:“我现在将用户交互请求发送给你,你看着办,需要我的时候我会协助你”。
- 对于绑定到View上的数据,不应该是View从Presenter上“拉”回来的,应该是Presenter主动“推”给View的。(这里借鉴了IOC做法)
- View尽可能不维护数据状态,因为其本身仅仅实现单纯的、独立的UI操作;Presenter才是整个体系的协调者,它根据处理用于交互的逻辑给View和Model安排工作。
MVP架构存在的问题与解决办法
- 1、加入模板方法
将逻辑操作从V层转移到P层后,可能有一些Activity还是比较膨胀,此时,可以通过继承BaseActivity的方式加入模板方法。注意,最好不要超过3层继承。
- 2、Model内部分层
模型层(Model)中的整体代码量是最大的,此时可以进行模块的划分和接口隔离。
- 3、使用中介者和代理
在UI层和Presenter之间设置中介者Mediator,将例如数据校验、组装在内的轻量级逻辑操作放在Mediator中;在Presenter和Model之间使用代理Proxy;通过上述两者分担一部分Presenter的逻辑操作,但整体框架的控制权还是在Presenter手中。
MVVM
MVVM可以算是MVP的升级版,其中的VM是ViewModel的缩写,ViewModel可以理解成是View的数据模型和Presenter的合体,ViewModel和View之间的交互通过Data Binding完成,而Data Binding可以实现双向的交互,这就使得视图和控制层之间的耦合程度进一步降低,关注点分离更为彻底,同时减轻了Activity的压力。
MVC->MVP->MVVM演进过程
MVC -> MVP -> MVVM 这几个软件设计模式是一步步演化发展的,MVVM 是从 MVP 的进一步发展与规范,MVP 隔离了MVC中的 M 与 V 的直接联系后,靠 Presenter 来中转,所以使用 MVP 时 P 是直接调用 View 的接口来实现对视图的操作的,这个 View 接口的东西一般来说是 showData、showLoading等等。M 与 V已经隔离了,方便测试了,但代码还不够优雅简洁,所以 MVVM 就弥补了这些缺陷。在 MVVM 中就出现的 Data Binding 这个概念,意思就是 View 接口的 showData 这些实现方法可以不写了,通过 Binding 来实现。
三种模式的相同点
M层和V层的实现是一样的。
三种模式的不同点
三者的差异在于如何粘合View和Model,实现用户的交互操作以及变更通知。
- Controller:接收View的命令,对Model进行操作,一个Controller可以对应多个View。
- Presenter:Presenter与Controller一样,接收View的命令,对Model进行操作;与Controller不同的是Presenter会反作用于View,Model的变更通知首先被Presenter获得,然后Presenter再去更新View。通常一个Presenter只对应于一个View。据Presenter和View对逻辑代码分担的程度不同,这种模式又有两种情况:普通的MVP模式和Passive View模式。
- ViewModel:注意这里的“Model”指的是View的Model,跟MVVM中的一个Model不是一回事。所谓View的Model就是包含View的一些数据属性和操作的这么一个东东,这种模式的关键技术就是数据绑定(data binding),View的变化会直接影响ViewModel,ViewModel的变化或者内容也会直接体现在View上。这种模式实际上是框架替应用开发者做了一些工作,开发者只需要较少的代码就能实现比较复杂的交互。
补充:基于AOP的架构设计
AOP(Aspect-Oriented Programming, 面向切面编程),诞生于上个世纪90年代,是对OOP(Object-Oriented Programming, 面向对象编程)的补充和完善。OOP引入封装、继承和多态性等概念来建立一种从上道下的对象层次结构,用以模拟公共行为的一个集合。当我们需要为分散的对象引入公共行为的时候,即定义从左到右的关系时,OOP则显得无能为力。例如日志功能。日志代码往往水平地散布在所有对象层次中,而与它所散布到的对象的核心功能毫无关系。对于其他类型的代码,如安全性、异常处理和透明的持续性也是如此。这种散布在各处的无关的代码被称为横切(Cross-Cutting)代码,在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。而AOP技术则恰恰相反,它利用一种称为“横切”的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,并将其名为“Aspect”,即方面。所谓“方面”,简单地说,就是将那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块间的耦合度,并有利于未来的可操作性和可维护性。
在Android App中的横切关注点有Http, SharedPreferences, Log, Json, Xml, File, Device, System, 格式转换等。Android App的需求差别很大,不同的需求横切关注点必然是不一样的。一般的App工程中应该有一个Util Package来存放相关的切面操作,在项目多了之后可以将其中使用较多的Util封装为一个Jar包/aar文件/远程依赖的方式供工程调用。
在使用MVP和AOP对App进行纵向和横向的切割之后,能够使得App整体的结构更清晰合理,避免局部的代码臃肿,方便开发、测试以及后续的维护。这样纵,横两次对于App代码的分割已经能使得程序不会过多堆积在一个Java文件里,但靠一次开发过程就写出高质量的代码是很困难的,趁着项目的间歇期,对代码进行重构很有必要。
最后的建议
如果“从零开始”,用什么设计架构的问题属于想得太多做得太少的问题。 从零开始意味着一个项目的主要技术难点是基本功能实现。当每一个功能都需要考虑如何做到的时候,我觉得一般人都没办法考虑如何做好。 因为,所有的优化都是站在最上层进行统筹规划。在这之前,你必须对下层的每一个模块都非常熟悉,进而提炼可复用的代码、规划逻辑流程。
MVC的情况下怎么把Activity的C和V抽离?
MVP 架构中 Presenter 定义为接口有什么好处;
MVP如何管理Presenter的生命周期,何时取消网络请求?
aop思想
Fragment如果在Adapter中使用应该如何解耦?
项目框架里有没有Base类,BaseActivity和BaseFragment这种封装导致的问题,以及解决方法?
设计一个音乐播放界面,你会如何实现,用到那些类,如何设计,如何定义接口,如何与后台交互,如何缓存与下载,如何优化(15分钟时间)
从0设计一款App整体架构,如何去做?
说一款你认为当前比较火的应用并设计(比如:直播APP,P2P金融,小视频等)
实现一个库,完成日志的实时上报和延迟上报两种功能,该从哪些方面考虑?
六、其它高频面试题
1、如何保证一个后台服务不被杀死?(相同问题:如何保证service在后台不被kill?)比较省电的方式是什么?
保活方案
1、AIDL方式单进程、双进程方式保活Service。(基于onStartCommand() return START_STICKY)
START_STICKY 在运行onStartCommand后service进程被kill后,那将保留在开始状态,但是不保留那些传入的intent。不久后service就会再次尝试重新创建,因为保留在开始状态,在创建 service后将保证调用onstartCommand。如果没有传递任何开始命令给service,那将获取到null的intent。
除了华为此方案无效以及未更改底层的厂商不起作用外(START_STICKY字段就可以保持Service不被杀)。此方案可以与其他方案混合使用
2、降低oom_adj的值(提升service进程优先级):
Android中的进程是托管的,当系统进程空间紧张的时候,会依照优先级自动进行进程的回收。Android将进程分为6个等级,它们按优先级顺序由高到低依次是:
- 1.前台进程 (Foreground process)
- 2.可见进程 (Visible process)
- 3.服务进程 (Service process)
- 4.后台进程 (Background process)
- 5.空进程 (Empty process)
当service运行在低内存的环境时,将会kill掉一些存在的进程。因此进程的优先级将会很重要,可以使用startForeground 将service放到前台状态。这样在低内存时被kill的几率会低一些。
-
常驻通知栏(可通过启动另外一个服务关闭Notification,不对oom_adj值有影响)。
-
使用”1像素“的Activity覆盖在getWindow()的view上。
此方案无效果
- 循环播放无声音频(黑科技,7.0下杀不掉)。
成功对华为手机保活。小米8下也成功突破20分钟
- 3、监听锁屏广播:使Activity始终保持前台。
- 4、使用自定义锁屏界面:覆盖了系统锁屏界面。
- 5、通过android:process属性来为Service创建一个进程。
- 6、跳转到系统白名单界面让用户自己添加app进入白名单。
复活方案
1、onDestroy方法里重启service
service + broadcast 方式,就是当service走onDestory的时候,发送一个自定义的广播,当收到广播的时候,重新启动service。
2、JobScheduler:原理类似定时器,5.0,5.1,6.0作用很大,7.0时候有一定影响(可以在电源管理中给APP授权)。
只对5.0,5.1、6.0起作用。
3、推送互相唤醒复活:极光、友盟、以及各大厂商的推送。
4、同派系APP广播互相唤醒:比如今日头条系、阿里系。
此外还可以监听系统广播判断Service状态,通过系统的一些广播,比如:手机重启、界面唤醒、应用状态改变等等监听并捕获到,然后判断我们的Service是否还存活。
结论:高版本情况下可以使用弹出通知栏、双进程、无声音乐提高后台服务的保活概率。
2、Android动画框架实现原理。
Animation 框架定义了透明度,旋转,缩放和位移几种常见的动画,而且控制的是整个View。实现原理:
每次绘制视图时,View 所在的 ViewGroup 中的 drawChild 函数获取该View 的 Animation 的 Transformation 值,然后调用canvas.concat(transformToApply.getMatrix()),通过矩阵运算完成动画帧,如果动画没有完成,继续调用 invalidate() 函数,启动下次绘制来驱动动画,动画过程中的帧之间间隙时间是绘制函数所消耗的时间,可能会导致动画消耗比较多的CPU资源,最重要的是,动画改变的只是显示,并不能响应事件。
3、Activity-Window-View三者的差别?
Activity像一个工匠(控制单元),Window像窗户(承载模型),View像窗花(显示视图) LayoutInflater像剪刀,Xml配置像窗花图纸。
在Activity中调用attach,创建了一个Window, 创建的window是其子类PhoneWindow,在attach中创建PhoneWindow。 在Activity中调用setContentView(R.layout.xxx), 其中实际上是调用的getWindow().setContentView(), 内部调用了PhoneWindow中的setContentView方法。
创建ParentView:
作为ViewGroup的子类,实际是创建的DecorView(作为FramLayout的子类), 将指定的R.layout.xxx进行填充, 通过布局填充器进行填充【其中的parent指的就是DecorView】, 调用ViewGroup的removeAllView(),先将所有的view移除掉,添加新的view:addView()。
参考文章
4、低版本SDK如何实现高版本api?
- 1、在使用了高版本API的方法前面加一个 @TargetApi(API号)。
- 2、在代码上用版本判断来控制不同版本使用不同的代码。
5、说说你对Context的理解?
6、Android的生命周期和启动模式
由A启动B Activity,A为栈内复用模式,B为标准模式,然后再次启动A或者杀死B,说说A,B的生命周期变化,为什么?
Activity的启动模式有哪些?栈里是A-B-C,先想直接到A,BC都清理掉,有几种方法可以做到?这几种方法产生的结果是有几个A的实例?
7、ListView和RecyclerView系列
RecyclerView和ListView有什么区别?局部刷新?前者使用时多重type场景下怎么避免滑动卡顿。懒加载怎么实现,怎么优化滑动体验。
ListView、RecyclerView区别?
一、使用方面:
ListView的基础使用:
- 继承重写 BaseAdapter 类
- 自定义 ViewHolder 和 convertView 一起完成复用优化工作
RecyclerView 基础使用关键点同样有两点:
- 继承重写 RecyclerView.Adapter 和 RecyclerView.ViewHolder
- 设置布局管理器,控制布局效果
RecyclerView 相比 ListView 在基础使用上的区别主要有如下几点:
- ViewHolder 的编写规范化了
- RecyclerView 复用 Item 的工作 Google 全帮你搞定,不再需要像 ListView 那样自己调用 setTag
- RecyclerView 需要多出一步 LayoutManager 的设置工作
二、布局方面:
RecyclerView 支持 线性布局、网格布局、瀑布流布局 三种,而且同时还能够控制横向还是纵向滚动。
三、API提供方面:
ListView 提供了 setEmptyView ,addFooterView 、 addHeaderView.
RecyclerView 供了 notifyItemChanged 用于更新单个 Item View 的刷新,我们可以省去自己写局部更新的工作。
四、动画效果:
RecyclerView 在做局部刷新的时候有一个渐变的动画效果。继承 RecyclerView.ItemAnimator 类,并实现相应的方法,再调用 RecyclerView的 setItemAnimator(RecyclerView.ItemAnimator animator) 方法设置完即可实现自定义的动画效果。
五、监听 Item 的事件:
ListView 提供了单击、长按、选中某个 Item 的监听设置。
RecyclerView与ListView缓存机制的不同
想改变listview的高度,怎么做?
listview跟recyclerview上拉加载的时候分别应该如何处理?
如何自己实现RecyclerView的侧滑删除?
RecyclerView的ItemTouchHelper的实现原理
8、如何实现一个推送,消息推送原理?推送到达率的问题?
一:客户端不断的查询服务器,检索新内容,也就是所谓的pull 或者轮询方式。
二:客户端和服务器之间维持一个TCP/IP长连接,服务器向客户端push。
https://blog.csdn.net/clh604/article/details/20167263
https://www.jianshu.com/p/45202dcd5688
9、动态权限系列。
动态权限适配方案,权限组的概念
Runtime permission,如何把一个预置的app默认给它权限?不要授权。
10、自定义View系列。
Canvas的底层机制,绘制框架,硬件加速是什么原理,canvas lock的缓冲区是怎么回事?
双指缩放拖动大图
TabLayout中如何让当前标签永远位于屏幕中间
TabLayout如何设置指示器的宽度包裹内容?
自定义View如何考虑机型适配?
- 合理使用warp_content,match_parent。
- 尽可能地使用RelativeLayout。
- 针对不同的机型,使用不同的布局文件放在对应的目录下,android会自动匹配。
- 尽量使用点9图片。
- 使用与密度无关的像素单位dp,sp。
- 引入android的百分比布局。
- 切图的时候切大分辨率的图,应用到布局当中,在小分辨率的手机上也会有很好的显示效果。
11、对谷歌新推出的Room架构。
12、没有给权限如何定位,特定机型定位失败,如何解决?
13、Debug跟Release的APK的区别?
14、android文件存储,各版本存储位置的权限控制的演进,外部存储,内部存储
15、有什么提高编译速度的方法?
16、Scroller原理。
Scroller执行流程里面的三个核心方法
mScroller.startScroll();
mScroller.computeScrollOffset();
view.computeScroll();
1、在mScroller.startScroll()中为滑动做了一些初始化准备,比如:起始坐标,滑动的距离和方向以及持续时间(有默认值),动画开始时间等。
2、mScroller.computeScrollOffset()方法主要是根据当前已经消逝的时间来计算当前的坐标点。因为在mScroller.startScroll()中设置了动画时间,那么在computeScrollOffset()方法中依据已经消逝的时间就很容易得到当前时刻应该所处的位置并将其保存在变量mCurrX和mCurrY中。除此之外该方法还可判断动画是否已经结束。
17、Hybrid系列。
webwiew了解?怎么实现和javascript的通信?相互双方的通信。@JavascriptInterface在?版本有bug,除了这个还有其他调用android方法的方案吗?
Android中Java和JavaScript交互
webView.addJavaScriptInterface(new Object(){xxx}, "xxx");
1
答案:可以使用WebView控件执行JavaScript脚本,并且可以在JavaScript中执行Java代码。要想让WebView控件执行JavaScript,需要调用WebSettings.setJavaScriptEnabled方法,代码如下:
WebView webView = (WebView)findViewById(R.id.webview);
WebSettings webSettings = webView.getSettings();
//设置WebView支持JavaScript
webSettings.setJavaScriptEnabled(true);
webView.setWebChromeClient(new WebChromeClient());
JavaScript调用Java方法需要使用WebView.addJavascriptInterface方法设置JavaScript调用的Java方法,代码如下:
webView.addJavascriptInterface(new Object()
{
//JavaScript调用的方法
public String process(String value)
{
//处理代码
return result;
}
}, "demo"); //demo是Java对象映射到JavaScript中的对象名
可以使用下面的JavaScript代码调用process方法,代码如下: