Unicode编码的实现
一 点睛
Unicode的实现和编码方式不一定等价。Unicode编码是一种理论层面的东西。Unicode编码的实现方式称为Unicode转换格式(Unicode Transfomation Format,UTF)。Unicode编码的实现方式主要由UTF-8,UTF-16,UFT-32等,分别以字节(BYTE)、字(OWORD,2个字节)、双子(DWORD,4个字节,实际只用了31位,最高位为0)作为编码单位。根据字节序的不同,UTF-16可以被实现为UTF-16LE或UFT-16BE,UTF-32可以被实现为UTF-32LE或UFT-32BE。这些方式是对Unicode码点进行编码,以适合计算机的存储和传输。
二 UTF-8
1 从Unicode到UTF-8的编码方式
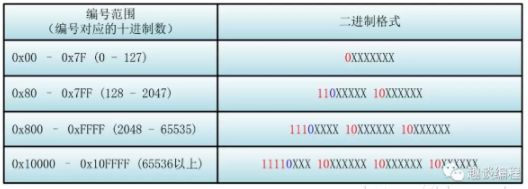
2 转换方法
首先找到该Unicode编号所在的编号范围,进而可以找到与之对应的二进制格式,然后将该Unicode编号转化为二进制数(去掉高位的0),最后将该二进制数从右向左依次填入二进制格式的X中,如果还有X未填,则设为0 。
3 举例
“马”的Unicode编号是:0x9A6C,整数编号是39532,对应第三个范围(2048 - 65535),其格式为:1110XXXX 10XXXXXX 10XXXXXX,39532 对应的二进制是 1001 1010 0110 1100,将二进制填入进入就为: 11101001 10101001 10101100 。
4 图示


由于UTF-8的处理单元为一个字节(也就是一次处理一个字节),所以处理器在处理的时候就不需要考虑这一个字节的存储是在高位还是在低位,直接拿到这个字节进行处理就行了,因为大小端是针对大于一个字节的数的存储问题而言的。
6 转换工具
http://tool.chinaz.com/Tools/utf-8.aspx
三 UTF-16
1 点睛
使用二或四个字节为每个字符编码,其中大部分汉字采用两个字节编码,少量不常用汉字采用四个字节编码。UTF-16 编码有大尾序和小尾序之别,即 UTF-16BE 和 UTF-16LE,在编码前会放置一个 U+FEFF 或 U+FFFE(UTF-16BE 以 FEFF 代表,UTF-16LE 以 FFFE 代表),其中 U+FEFF 字符在 Unicode 中代表的意义是 ZERO WIDTH NO-BREAK SPACE,顾名思义,它是个没有宽度也没有断字的空白。
2 编码规则
2.1 从U+D800到U+DFFF的码位(代理区)
因为Unicode字符集的编码值范围为0-0x10FFFF,而大于等于0x10000的辅助平面区的编码值无法用2个字节来表示,所以Unicode标准规定:基本多语言平面内,U+D800~U+DFFF的值不对应于任何字符,为代理区。这样,UTF-16利用保留下来的0xD800-0xDFFF区段的码位来对辅助平面的字符的码位进行编码。
但是在使用UCS-2的时代,U+D800~U+DFFF内的值被占用,用于某些字符的映射。但只要不构成代理对,许多UTF-16编码解码还是能把这些不符合Unicode标准的字符映射正确的辨识、转换成合规的码元. 按照Unicode标准,这种码元串行本来应算作编码错误。
2.2 从U+0000至U+D7FF以及从U+E000至U+FFFF的码位
第一个Unicode平面(BMP),码位从U+0000至U+FFFF(除去代理区),包含了最常用的字符。UTF-16与UCS-2编码在这个范围内的码位为单个16比特长的码元,数值等价于对应的码位。BMP中的这些码位是仅有的码位可以在UCS-2被表示。
2.3 从U+10000到U+10FFFF的码位
辅助平面(Supplementary Planes)中的码位,大于等于0x10000,在UTF-16中被编码为一对16比特长的码元(即32bit,4Bytes),称作 code units called a 代理对(surrogate pair),具体方法是:
Ø 码位减去0x10000, 得到的值的范围为20比特长的0..0xFFFFF(因为Unicode的最大码位是0x10ffff,减去0x10000后,得到的最大值是0xfffff,所以肯定可以用20个二进制位表示),写成二进制形式:yyyy yyyy yyxx xxxx xxxx。
Ø 高位的10比特的值(值的范围为0..0x3FF)被加上0xD800得到第一个码元或称作高位代理(high surrogate), 值的范围是0xD800..0xDBFF。由于高位代理比低位代理的值要小,所以为了避免混淆使用,Unicode标准现在称高位代理为前导代理(lead surrogates)。
Ø 低位的10比特的值(值的范围也是0..0x3FF)被加上0xDC00得到第二个码元或称作低位代理(low surrogate), 现在值的范围是0xDC00..0xDFFF。 由于低位代理比高位代理的值要大,所以为了避免混淆使用,Unicode标准现在称低位代理为后尾代理(trail surrogates)。
Ø 最终的UTF-16(4字节)的编码(二进制)就是:110110yyyyyyyyyy 110111xxxxxxxxxx。
按照上述规则,Unicode编码0x10000-0x10FFFF的UTF-16编码有两个WORD,第一个WORD的高6位是110110,第二个WORD的高6位是110111。可见,第一个WORD的取值范围(二进制)是11011000 00000000到11011011 11111111,即0xD800-0xDBFF。第二个WORD的取值范围(二进制)是11011100 00000000到11011111 11111111,即0xDC00-0xDFFF。上面所说的从U+D800到U+DFFF的码位(代理区),就是为了将一个WORD(2字节)的UTF-16编码与两个WORD的UTF-16编码区分开来。
高位代理、低位代理、BMP中的有效字符的码位,三者互不重叠。
四 UTF-32
UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符,所以直接存储 Unicode 编号即可,不需要任何编码转换。浪费了空间,提高了效率。