linux spi
前言:
linux spi驱动分层架构包括,应用层、系统调用层、spi接口层、spi核心层、spi驱动层、spi从设备,本博客首先分析spi-platfrom设备驱动的注册,从设备m25p80是如何绑定到spi总线上,在platform探测函数是如何注册spi-master主设备的,其次通过从设备spi nandflash分析其是如何工作的....
1.spi驱动框架
1.1.硬件结构模型
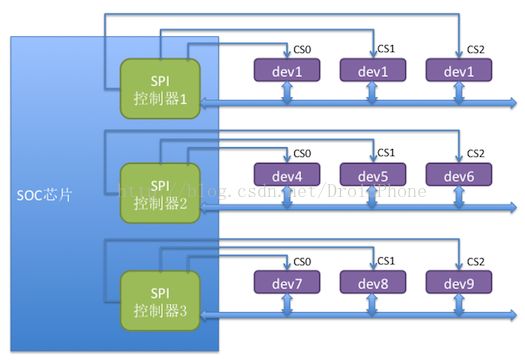
MCU与SPI主要关系为主从设备,通过SPI片选可在同一根SPI总线下挂接多个从设备。
1.2.spi时序图

CPOL:表示时钟初始电平状态,0-表示初始电平为低,1-表示初始电表为高;
CPHA:表示哪个时钟沿开始采样,0-表示首个时钟沿开始采样,1-表示第二个时钟沿开始采样;
所以CPOL\CPHA组合,有四种模式:
CPOL=0、CPHA=0,模式1
CPOL=0、CPHA=1,模式2
CPOL=1、CPHA=0,模式3
CPOL=1、CPHA=1,模式4
1.3.spi驱动框架
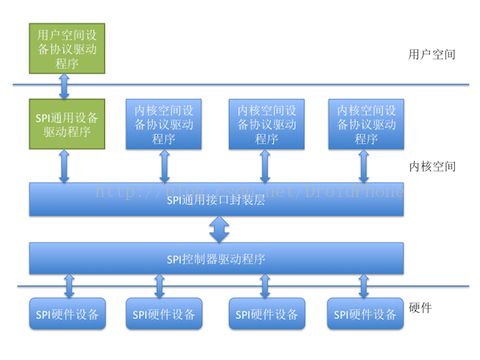
spi驱动框架从上到下,主要包括:
a. 用户层spi系统调用
b. 内核空间设备协议驱动程序
c. spi通用接口封装
d. spi控制器驱动程序
f. spi硬件设备
2.spi从设备注册(m25p80)
这里通过从设备M25P80 spi-flash来阐述spi的驱动框架的
2.1.mtd分区表
static struct mtd_partition nuc970_spi0_flash_partitions[] = {
{
.name = "kernel",
.size = 0x0800000,
.offset = 0,
},
{
.name = "rootfs",
.size = 0x0800000,
.offset = 0x0800000,
},
};2.2.Flash platform数据区
static struct flash_platform_data nuc970_spi0_flash_data = {
.name = "m25p80", //设备名称
.parts = nuc970_spi0_flash_partitions, //mtd分区表
.nr_parts = ARRAY_SIZE(nuc970_spi0_flash_partitions), //mtd分区个数
.type = "w25q128",
};M25P80:是意法半导体推出的一款高速8 Mbit串行Flash,共由16部分组成,每一部分有256页,每页有256个字节。M25P80具有先进的写保护机制,读取数据的最大时钟速率为40 MHz。M25P80的工作电压范围为2.7 V~3.6 V,具有整体擦除和扇区擦除、灵活的页编程指令和写保护功能,数据保存至少20年,每个扇区可承受100 000次擦写循环。并行Flash封装通常需要28个以上的引脚,因此,额外支出大,而M25P80采用SO8封装,需要的引脚数较少,从而节省了电路板空间,功率、系统噪声和整体成本等都会大幅度降低,既经济又实用。
W25Q128:是华邦公司推出的大容量SPI FLASH产品,W25Q128的容量为128Mb,该系列还有W25Q80/16/32/64等。
W25Q128将16M的容量分为256个块(Block),每个块大小为64K字节,每个块又分为16个扇区(Sector),每个扇区4K个字节。W25Q128的最小擦除单位为一个扇区,也就是每次必须擦除4K个字节。这样我们需要给W25Q128开辟一个至少4K的缓存区,这样对SRAM要求比较高,要求芯片必须有4K以上SRAM才能很好的操作。
W25Q128的擦写周期多达10W次,具有20年的数据保存期限,支持电压为2.7~3.6V,
W25Q128支持标准的SPI,还支持双输出/四输出的SPI,最大SPI时钟可以到80Mhz(双输出时相当于160Mhz,四输出时相当于320M),更多的W25Q128的介绍,请参考W25Q128的DATASHEET。
2.3.spi从设备板级信息配置
static struct spi_board_info nuc970_spi0_board_info[] __initdata = {
{
.modalias = "m25p80", //spi从设备名称
.max_speed_hz = 15000000, //spi从设备最大时钟
.bus_num = 0, //spi控制器总线编号,这里是0,即选择spi0控制器
.chip_select = 0, //该从设备在控制器里片选为0
.platform_data = &nuc970_spi0_flash_data, //见上“2.1.2 Flash platfrom数据区”
#if defined(CONFIG_SPI_NUC970_P0_NORMAL) //三线
.mode = (SPI_MODE_0 | SPI_RX_DUAL | SPI_TX_DUAL), //spi工作模式,这里选择mode0,
#elif defined(CONFIG_SPI_NUC970_P0_QUAD) //四线
.mode = (SPI_MODE_0 | SPI_TX_QUAD | SPI_RX_QUAD),
#endif
},
};SPI分4线和3线,
4线接口:包括SCLK、SDO、SDI、SS;
3线接口:包括SCLK、SDA、SS。
所以3线和4线的不同在于,4线接口可以实现的是master in和master out。
但3线只有master out。不管是3线还是4线,SS是必须有的。master使用不同的SS信号可以连接多个salver。
spi接收、发送分为两种方式,即三线和四线
SPI_RX_DUAL、SPI_TX_DUAL:SPI的读写速度是普通序列式闪存的2-3倍,DI和DO是双向的,称作DI0 DI1SPI_TX_QUAD、SPI_RX_QUAD:SPI的读写速度是普通序列式闪存的4-6倍;DI和DO是双向的,称作DI0 DI1,同时,/WP和/HOLD也变成输入输出管脚,称作DI2 DI3
详见定义:linux-3.10.x\include\linux\spi\spi.h
2.4.spi从设备m25p80板级信息注册
spi_register_board_info(nuc970_spi0_board_info, ARRAY_SIZE(nuc970_spi0_board_info));int spi_register_board_info(struct spi_board_info const *info, unsigned n)
{
struct boardinfo *bi;
int i;
bi = kzalloc(n * sizeof(*bi), GFP_KERNEL);
if (!bi)
return -ENOMEM;
for (i = 0; i < n; i++, bi++, info++) {
struct spi_master *master;
memcpy(&bi->board_info, info, sizeof(*info));
mutex_lock(&board_lock);
list_add_tail(&bi->list, &board_list); //spi从设备板级信息加入到全局board_list链表中
list_for_each_entry(master, &spi_master_list, list)
spi_match_master_to_boardinfo(master, &bi->board_info); //本次注册的板级信息对应的spi控制器是否已经注册到全局控制器链表spi_master_ilst中
mutex_unlock(&board_lock);
}
return 0;
}
本次注册的板级信息bi对应的spi控制器驱动是否匹配成功,若成功将调用spi_new_device(...)增加一个新的设备!
static void spi_match_master_to_boardinfo(struct spi_master *master,
struct spi_board_info *bi)
{
struct spi_device *dev;
if (master->bus_num != bi->bus_num)
return;
dev = spi_new_device(master, bi);
if (!dev)
dev_err(master->dev.parent, "can't create new device for %s\n",
bi->modalias);
}3.spi platform设备注册
3.1.spi控制器驱动配置
static struct nuc970_spi_info nuc970_spi0_platform_data = {
.num_cs = 1, //spi控制器下片选个数
.lsb = 0, //字节传输顺序, 0-高bit先传输
.txneg = 1, //发送边沿
.rxneg = 0, //接收边沿
.divider = 4, //时钟分频系数
.sleep = 0, //?
.txnum = 0, //?
.txbitlen = 8, //控制器发送bit
.bus_num = 0, //总线编号,这里为spi0
};3.2.spi寄存器资源
static struct resource nuc970_spi0_resource[] = {
[0] = {
.start = NUC970_PA_SPI0,
.end = NUC970_PA_SPI0 + NUC970_SZ_SPI0 - 1,
.flags = IORESOURCE_MEM,
},
[1] = {
.start = IRQ_SPI0,
.end = IRQ_SPI0,
.flags = IORESOURCE_IRQ,
}
};3.3.spi platfrom设备配置
struct platform_device nuc970_device_spi0 = {
.name = "nuc970-spi0",
.id = -1,
.num_resources = ARRAY_SIZE(nuc970_spi0_resource),
.resource = nuc970_spi0_resource,
#if defined(CONFIG_MTD_M25P80) || defined(CONFIG_SPI_SPIDEV)
.dev = {
.platform_data = &nuc970_spi0_platform_data, //spi控制器驱动配置
}
#endif
};3.4.spi platform设备注册
platform_device_register(nuc970_device_spi0 );4.spi platform驱动注册
4.1. spi platform_driver注册
static struct platform_driver nuc970_spi0_driver = {
.probe = nuc970_spi0_probe,
.remove = nuc970_spi0_remove,
.driver = {
.name = "nuc970-spi0",//驱动名称,与上面的平台设备名称一样
.owner = THIS_MODULE,
},
};
module_platform_driver(nuc970_spi0_driver);源码路径:linux-3.10.x\include\linux\platform_device.h
#define module_platform_driver(__platform_driver) \
module_driver(__platform_driver, platform_driver_register, \
platform_driver_unregister)#define module_driver(__driver, __register, __unregister, ...) \
static int __init __driver##_init(void) \
{ \
return __register(&(__driver) , ##__VA_ARGS__); \
} \
module_init(__driver##_init); \
static void __exit __driver##_exit(void) \
{ \
__unregister(&(__driver) , ##__VA_ARGS__); \
} \
module_exit(__driver##_exit);module_platform_driver(...)其实就是调用平台驱动注册platform_driver_register(...)、释放函数platform_driver_unregister(...),这两个函数内部的处理可以参考之前的一篇博客:点击打开链接,其目的是注册spi驱动,和设备匹配时调用探测函数nuc970_spi0_probe(...)。
4.2.探测函数nuc970_spi0_probe(...)
static int nuc970_spi0_probe(struct platform_device *pdev)
{
struct nuc970_spi *hw;
struct spi_master *master;
int err = 0;
struct pinctrl *p;
master = spi_alloc_master(&pdev->dev, sizeof(struct nuc970_spi)); //分配一个spi主机控制器
if (master == NULL) {
dev_err(&pdev->dev, "No memory for spi_master\n");
err = -ENOMEM;
goto err_nomem;
}
//获取设备的私有数据,私有数据的内存空间在spi_alloc_mater(...)中分配,内存空间为sizeof(struct nuc970_spi)
hw = spi_master_get_devdata(master);
//nuc970_spi指向master主机控制器
hw->master = spi_master_get(master);
//hw->pdata类型为struct nuc970_spi_info,pdev->dev.platform_data在“2.1.4”中定义
hw->pdata = pdev->dev.platform_data;
//pdev->dev在“二.1.f”中定义
hw->dev = &pdev->dev;
if (hw->pdata == NULL) {
dev_err(&pdev->dev, "No platform data supplied\n");
err = -ENOENT;
goto err_pdata;
}
//将pdev->dev->p->driver_data设备私有数据指针指向hw
platform_set_drvdata(pdev, hw);
//初始化一个完成量,具体工作原理待分析!!!
init_completion(&hw->done);
#if defined(CONFIG_SPI_NUC970_P0_NORMAL)
master->mode_bits = (SPI_MODE_0 | SPI_TX_DUAL | SPI_RX_DUAL);
#elif defined(CONFIG_SPI_NUC970_P0_QUAD)
master->mode_bits = (SPI_MODE_0 | SPI_TX_DUAL | SPI_RX_DUAL | SPI_TX_QUAD | SPI_RX_QUAD);
#endif
master->num_chipselect = hw->pdata->num_cs; //片选
master->bus_num = hw->pdata->bus_num; //spi总线
hw->bitbang.master = hw->master;
hw->bitbang.setup_transfer = nuc970_spi0_setupxfer; //设置SPI的传输配置,包括时钟、接发边沿、bit传输顺序...
hw->bitbang.chipselect = nuc970_spi0_chipsel; //片选操作
hw->bitbang.txrx_bufs = nuc970_spi0_txrx;
hw->bitbang.master->setup = nuc970_spi0_setup;
hw->res = platform_get_resource(pdev, IORESOURCE_MEM, 0);
if (hw->res == NULL) {
dev_err(&pdev->dev, "Cannot get IORESOURCE_MEM\n");
err = -ENOENT;
goto err_pdata;
}
hw->ioarea = request_mem_region(hw->res->start,
resource_size(hw->res), pdev->name);
if (hw->ioarea == NULL) {
dev_err(&pdev->dev, "Cannot reserve region\n");
err = -ENXIO;
goto err_pdata;
}
hw->regs = ioremap(hw->res->start, resource_size(hw->res));
if (hw->regs == NULL) {
dev_err(&pdev->dev, "Cannot map IO\n");
err = -ENXIO;
goto err_iomap;
}
hw->irq = platform_get_irq(pdev, 0);
if (hw->irq < 0) {
dev_err(&pdev->dev, "No IRQ specified\n");
err = -ENOENT;
goto err_irq;
}
//申请spi中断
err = request_irq(hw->irq, nuc970_spi0_irq, 0, pdev->name, hw);
if (err) {
dev_err(&pdev->dev, "Cannot claim IRQ\n");
goto err_irq;
}
hw->clk = clk_get(NULL, "spi0");
if (IS_ERR(hw->clk)) {
dev_err(&pdev->dev, "No clock for device\n");
err = PTR_ERR(hw->clk);
goto err_clk;
}
#if defined(CONFIG_SPI_NUC970_P0_NORMAL)
p = devm_pinctrl_get_select(&pdev->dev, "spi0");
#elif defined(CONFIG_SPI_NUC970_P0_QUAD)
p = devm_pinctrl_get_select(&pdev->dev, "spi0-quad");
#endif
if(IS_ERR(p)) {
dev_err(&pdev->dev, "unable to reserve pin\n");
err = PTR_ERR(p);
}
//spi主机控制器初始化
nuc970_init_spi(hw);
err = spi_bitbang_start(&hw->bitbang);
if (err) {
dev_err(&pdev->dev, "Failed to register SPI master\n");
goto err_register;
}
return 0;
err_register:
clk_disable(hw->clk);
clk_put(hw->clk);
err_clk:
free_irq(hw->irq, hw);
err_irq:
iounmap(hw->regs);
err_iomap:
release_mem_region(hw->res->start, resource_size(hw->res));
kfree(hw->ioarea);
err_pdata:
spi_master_put(hw->master);
err_nomem:
return err;
}struct spi_master *spi_alloc_master(struct device *dev, unsigned size)
{
struct spi_master *master;
if (!dev)
return NULL;
master = kzalloc(size + sizeof *master, GFP_KERNEL);
if (!master)
return NULL;
/*
设备初始化,包括spi设备指向device_kset内核集合,
spi内核对象初始化为device_ktype
*/
device_initialize(&master->dev);
master->bus_num = -1;
master->num_chipselect = 1;
master->dev.class = &spi_master_class;
//获取设备的父对象,因为spi设备是挂接到platform总线上,所以这里的父对象是platform
master->dev.parent = get_device(dev);
//上面kzalloc(...)分配的内存为两部分,size+sizeof*master,所以
//&master[1]就是master之后的另一部分内存的起始地址
spi_master_set_devdata(master, &master[1]);
return master;
}static void nuc970_init_spi(struct nuc970_spi *hw)
{
clk_prepare(hw->clk);
clk_enable(hw->clk);
spin_lock_init(&hw->lock);
nuc970_tx_edge(hw, hw->pdata->txneg);
nuc970_rx_edge(hw, hw->pdata->rxneg);
nuc970_send_first(hw, hw->pdata->lsb);
nuc970_set_sleep(hw, hw->pdata->sleep);
nuc970_spi0_setup_txbitlen(hw, hw->pdata->txbitlen);
nuc970_spi0_setup_txnum(hw, hw->pdata->txnum);
nuc970_set_divider(hw);
nuc970_enable_int(hw);
}4.3.spi_bitbang_start(...)启动spi控制器
int spi_bitbang_start(struct spi_bitbang *bitbang)
{
struct spi_master *master = bitbang->master;
int status;
if (!master || !bitbang->chipselect)
return -EINVAL;
INIT_WORK(&bitbang->work, bitbang_work); //初始化一个工作,并绑定该工作的回调函数
spin_lock_init(&bitbang->lock);
INIT_LIST_HEAD(&bitbang->queue);
if (!master->mode_bits)
master->mode_bits = SPI_CPOL | SPI_CPHA | bitbang->flags;
if (!master->transfer)
master->transfer = spi_bitbang_transfer;
if (!bitbang->txrx_bufs) {
bitbang->use_dma = 0;
bitbang->txrx_bufs = spi_bitbang_bufs;
if (!master->setup) {
if (!bitbang->setup_transfer)
bitbang->setup_transfer =
spi_bitbang_setup_transfer;
master->setup = spi_bitbang_setup;
master->cleanup = spi_bitbang_cleanup;
}
} else if (!master->setup)
return -EINVAL;
if (master->transfer == spi_bitbang_transfer &&
!bitbang->setup_transfer)
return -EINVAL;
/* this task is the only thing to touch the SPI bits */
bitbang->busy = 0;
bitbang->workqueue = create_singlethread_workqueue( //创建bitbang->workqueue工作队列
dev_name(master->dev.parent));
if (bitbang->workqueue == NULL) {
status = -EBUSY;
goto err1;
}
/* driver may get busy before register() returns, especially
* if someone registered boardinfo for devices
*/
status = spi_register_master(master);
if (status < 0)
goto err2;
return status;
err2:
destroy_workqueue(bitbang->workqueue);
err1:
return status;
}4.4.spi_register_master(...)注册控制器
int spi_register_master(struct spi_master *master)
{
static atomic_t dyn_bus_id = ATOMIC_INIT((1<<15) - 1);
struct device *dev = master->dev.parent;
struct boardinfo *bi;
int status = -ENODEV;
int dynamic = 0;
if (!dev)
return -ENODEV;
status = of_spi_register_master(master);
if (status)
return status;
/* even if it's just one always-selected device, there must
* be at least one chipselect
*/
if (master->num_chipselect == 0)
return -EINVAL;
if ((master->bus_num < 0) && master->dev.of_node)
master->bus_num = of_alias_get_id(master->dev.of_node, "spi");
/* convention: dynamically assigned bus IDs count down from the max */
if (master->bus_num < 0) {
/* FIXME switch to an IDR based scheme, something like
* I2C now uses, so we can't run out of "dynamic" IDs
*/
master->bus_num = atomic_dec_return(&dyn_bus_id);
dynamic = 1;
}
spin_lock_init(&master->bus_lock_spinlock);
mutex_init(&master->bus_lock_mutex);
master->bus_lock_flag = 0;
/* register the device, then userspace will see it.
* registration fails if the bus ID is in use.
*/
dev_set_name(&master->dev, "spi%u", master->bus_num);
status = device_add(&master->dev);
if (status < 0)
goto done;
dev_dbg(dev, "registered master %s%s\n", dev_name(&master->dev),
dynamic ? " (dynamic)" : "");
/* If we're using a queued driver, start the queue */
if (master->transfer)
dev_info(dev, "master is unqueued, this is deprecated\n");
else {
status = spi_master_initialize_queue(master);
if (status) {
device_unregister(&master->dev);
goto done;
}
}
mutex_lock(&board_lock);
list_add_tail(&master->list, &spi_master_list); //将本次注册的spi主机控制器加入到spi_master_list全局链表中
list_for_each_entry(bi, &board_list, list) //遍历board_list链表是否有对应的设备注册,我们在“一.3”节中有注册设备到该链表,nuc970_spi0_board_info[]
spi_match_master_to_boardinfo(master, &bi->board_info);
mutex_unlock(&board_lock);
/* Register devices from the device tree and ACPI */
of_register_spi_devices(master);
acpi_register_spi_devices(master);
done:
return status;
}static void spi_match_master_to_boardinfo(struct spi_master *master,
struct spi_board_info *bi)
{
struct spi_device *dev;
if (master->bus_num != bi->bus_num)
return;
dev = spi_new_device(master, bi);
if (!dev)
dev_err(master->dev.parent, "can't create new device for %s\n",
bi->modalias);
}
struct spi_device *spi_new_device(struct spi_master *master,
struct spi_board_info *chip)
{
struct spi_device *proxy;
int status;
/* NOTE: caller did any chip->bus_num checks necessary.
*
* Also, unless we change the return value convention to use
* error-or-pointer (not NULL-or-pointer), troubleshootability
* suggests syslogged diagnostics are best here (ugh).
*/
//分配一个代理spi设备,分配期间绑定了总线为spi,内核集合devices_kset,对象类型device_ktype
proxy = spi_alloc_device(master);
if (!proxy)
return NULL;
WARN_ON(strlen(chip->modalias) >= sizeof(proxy->modalias));
proxy->chip_select = chip->chip_select; //片选从设备
proxy->max_speed_hz = chip->max_speed_hz; //spi最大时钟
proxy->mode = chip->mode; //spi通讯模式
proxy->irq = chip->irq; //spi中断
strlcpy(proxy->modalias, chip->modalias, sizeof(proxy->modalias)); //从设备名称,这里是“m25p80”
proxy->dev.platform_data = (void *) chip->platform_data; //指向nuc970_spi0_flash_data
proxy->controller_data = chip->controller_data;
proxy->controller_state = NULL;
status = spi_add_device(proxy);
if (status < 0) {
spi_dev_put(proxy);
return NULL;
}
return proxy;
}
struct spi_device *spi_alloc_device(struct spi_master *master)
{
struct spi_device *spi;
struct device *dev = master->dev.parent;
if (!spi_master_get(master))
return NULL;
spi = kzalloc(sizeof *spi, GFP_KERNEL);
if (!spi) {
dev_err(dev, "cannot alloc spi_device\n");
spi_master_put(master);
return NULL;
}
spi->master = master;
spi->dev.parent = &master->dev;
spi->dev.bus = &spi_bus_type; //绑定spi总线
spi->dev.release = spidev_release;
spi->cs_gpio = -ENOENT;
device_initialize(&spi->dev); //设备对象初始化
return spi;
}4.5.spi_add_device(...)增加spi设备
int spi_add_device(struct spi_device *spi)
{
static DEFINE_MUTEX(spi_add_lock);
struct spi_master *master = spi->master;
struct device *dev = master->dev.parent;
struct device *d;
int status;
/* Chipselects are numbered 0..max; validate. */
if (spi->chip_select >= master->num_chipselect) {
dev_err(dev, "cs%d >= max %d\n",
spi->chip_select,
master->num_chipselect);
return -EINVAL;
}
/* Set the bus ID string */
dev_set_name(&spi->dev, "%s.%u", dev_name(&spi->master->dev), //"spi0.0"
spi->chip_select);
/* We need to make sure there's no other device with this
* chipselect **BEFORE** we call setup(), else we'll trash
* its configuration. Lock against concurrent add() calls.
*/
mutex_lock(&spi_add_lock);
//确定当前设备是否已经注册
d = bus_find_device_by_name(&spi_bus_type, NULL, dev_name(&spi->dev));
if (d != NULL) {
dev_err(dev, "chipselect %d already in use\n",
spi->chip_select);
put_device(d);
status = -EBUSY;
goto done;
}
if (master->cs_gpios)
spi->cs_gpio = master->cs_gpios[spi->chip_select];
/* Drivers may modify this initial i/o setup, but will
* normally rely on the device being setup. Devices
* using SPI_CS_HIGH can't coexist well otherwise...
*/
status = spi_setup(spi); //spi设置
if (status < 0) {
dev_err(dev, "can't setup %s, status %d\n",
dev_name(&spi->dev), status);
goto done;
}
/* Device may be bound to an active driver when this returns */
status = device_add(&spi->dev);
if (status < 0)
dev_err(dev, "can't add %s, status %d\n",
dev_name(&spi->dev), status);
else
dev_dbg(dev, "registered child %s\n", dev_name(&spi->dev));
done:
mutex_unlock(&spi_add_lock);
return status;
}int spi_setup(struct spi_device *spi)
{
unsigned bad_bits, ugly_bits;
int status = 0;
/* check mode to prevent that DUAL and QUAD set at the same time
*/
if (((spi->mode & SPI_TX_DUAL) && (spi->mode & SPI_TX_QUAD)) ||
((spi->mode & SPI_RX_DUAL) && (spi->mode & SPI_RX_QUAD))) {
dev_err(&spi->dev,
"setup: can not select dual and quad at the same time\n");
return -EINVAL;
}
/* if it is SPI_3WIRE mode, DUAL and QUAD should be forbidden
*/
if ((spi->mode & SPI_3WIRE) && (spi->mode &
(SPI_TX_DUAL | SPI_TX_QUAD | SPI_RX_DUAL | SPI_RX_QUAD)))
return -EINVAL;
/* help drivers fail *cleanly* when they need options
* that aren't supported with their current master
*/
bad_bits = spi->mode & ~spi->master->mode_bits;
if (bad_bits) {
dev_err(&spi->dev, "setup: unsupported mode bits %x\n",
bad_bits);
return -EINVAL;
}
if (!spi->bits_per_word)
spi->bits_per_word = 8;
if (spi->master->setup)
status = spi->master->setup(spi); //调用nuc970_spi0_setup(...)设置spi寄存器
dev_dbg(&spi->dev, "setup mode %d, %s%s%s%s"
"%u bits/w, %u Hz max --> %d\n",
(int) (spi->mode & (SPI_CPOL | SPI_CPHA)),
(spi->mode & SPI_CS_HIGH) ? "cs_high, " : "",
(spi->mode & SPI_LSB_FIRST) ? "lsb, " : "",
(spi->mode & SPI_3WIRE) ? "3wire, " : "",
(spi->mode & SPI_LOOP) ? "loopback, " : "",
spi->bits_per_word, spi->max_speed_hz,
status);
return status;
}device_add(&spi->dev)函数可以见之前写的一篇文章5.1.e小节部分:点击打开链接
至此,通过platform平台总线,完成spi控制器驱动的注册,"m25p80"spi从设备的注册。接下来要分析“m25p80”驱动是如何注册的。
5.spi驱动注册(m25p80)
5.1.spi设备驱动注册
struct spi_device_id {
char name[SPI_NAME_SIZE];
kernel_ulong_t driver_data; /* Data private to the driver */
};struct flash_info {
/* JEDEC id zero means "no ID" (most older chips); otherwise it has
* a high byte of zero plus three data bytes: the manufacturer id,
* then a two byte device id.
*/
u32 jedec_id;
u16 ext_id;
/* The size listed here is what works with OPCODE_SE, which isn't
* necessarily called a "sector" by the vendor.
*/
unsigned sector_size;
u16 n_sectors;
u16 page_size;
u16 addr_width;
u16 flags;
#define SECT_4K 0x01 /* OPCODE_BE_4K works uniformly */
#define M25P_NO_ERASE 0x02 /* No erase command needed */
#define SST_WRITE 0x04 /* use SST byte programming */
#define M25P_NO_FR 0x08 /* Can't do fastread */
#define M25P80_DUAL_READ 0x10 /* Flash supports Dual Read */
#define M25P80_QUAD_READ 0x20 /* Flash supports Quad Read */
#define M25P80_DUAL_WRITE 0x40 /* Flash supports Dual Write */
#define M25P80_QUAD_WRITE 0x80 /* Flash supports Quad Write */
};
#define INFO(_jedec_id, _ext_id, _sector_size, _n_sectors, _flags) \
((kernel_ulong_t)&(struct flash_info) { \
.jedec_id = (_jedec_id), \
.ext_id = (_ext_id), \
.sector_size = (_sector_size), \
.n_sectors = (_n_sectors), \
.page_size = 256, \
.flags = (_flags), \
})static const struct spi_device_id m25p_ids[] = {
/* Atmel -- some are (confusingly) marketed as "DataFlash" */
{ "at25fs010", INFO(0x1f6601, 0, 32 * 1024, 4, SECT_4K) },
{ "at25fs040", INFO(0x1f6604, 0, 64 * 1024, 8, SECT_4K) },
//...
{ "m25p80", INFO(0x202014, 0, 64 * 1024, 16, 0) },
//...
}static struct spi_driver m25p80_driver = {
.driver = {
.name = "m25p80",
.owner = THIS_MODULE,
},
.id_table = m25p_ids,
.probe = m25p_probe,
.remove = m25p_remove,
/* REVISIT: many of these chips have deep power-down modes, which
* should clearly be entered on suspend() to minimize power use.
* And also when they're otherwise idle...
*/
};module_spi_driver(m25p80_driver);#define module_spi_driver(__spi_driver) \
module_driver(__spi_driver, spi_register_driver, \
spi_unregister_driver)spi驱动注册:
int spi_register_driver(struct spi_driver *sdrv)
{
sdrv->driver.bus = &spi_bus_type; //绑定总线为spi,与上面4.4节相对应
if (sdrv->probe)
sdrv->driver.probe = spi_drv_probe;
if (sdrv->remove)
sdrv->driver.remove = spi_drv_remove;
if (sdrv->shutdown)
sdrv->driver.shutdown = spi_drv_shutdown;
return driver_register(&sdrv->driver);
}driver_register(...)设备注册,通过本次注册的设备驱动与上面3.1小节的“m25p80”相匹配,调用探针函数m25p_probe(...)
5.2.spi设备驱动探测函数
static int m25p_probe(struct spi_device *spi)
{
const struct spi_device_id *id = spi_get_device_id(spi); //本次注册的驱动“m25p80”是否在m25p_ids表中,匹配成功就返回id
struct flash_platform_data *data;
struct m25p *flash;
struct flash_info *info;
unsigned i;
struct mtd_part_parser_data ppdata;
struct device_node __maybe_unused *np = spi->dev.of_node;
int ret;
#ifdef CONFIG_MTD_OF_PARTS
if (!of_device_is_available(np))
return -ENODEV;
#endif
/* Platform data helps sort out which chip type we have, as
* well as how this board partitions it. If we don't have
* a chip ID, try the JEDEC id commands; they'll work for most
* newer chips, even if we don't recognize the particular chip.
*/
data = spi->dev.platform_data; //data指向nuc970_spi0_flash_data结构体
if (data && data->type) {
const struct spi_device_id *plat_id;
for (i = 0; i < ARRAY_SIZE(m25p_ids) - 1; i++) {
plat_id = &m25p_ids[i];
if (strcmp(data->type, plat_id->name)) //与"w25q128"匹配是否相同
continue;
break;
}
if (i < ARRAY_SIZE(m25p_ids) - 1)
id = plat_id;
else
dev_warn(&spi->dev, "unrecognized id %s\n", data->type);
}
info = (void *)id->driver_data;
if (info->jedec_id) { //JEDEC:电子元器件工业协会 定义的两个字节厂商ID
const struct spi_device_id *jid;
//这里还不知道spi总线下接的什么从设备,所以在jedec_probe(...)函数内部,
//通过spi接口读取从设备的厂商ID,并与m25p_ids[]结构体的成员比较。
jid = jedec_probe(spi);
if (IS_ERR(jid)) {
return PTR_ERR(jid);
} else if (jid != id) { //由于spi从设备与驱动程序配置的设备名不一致,下面将从设备的信息强制转换!
/*
* JEDEC knows better, so overwrite platform ID. We
* can't trust partitions any longer, but we'll let
* mtd apply them anyway, since some partitions may be
* marked read-only, and we don't want to lose that
* information, even if it's not 100% accurate.
*/
dev_warn(&spi->dev, "found %s, expected %s\n",
jid->name, id->name);
id = jid;
info = (void *)jid->driver_data;
}
}
//分配一个m25p80的flash设备
flash = kzalloc(sizeof *flash, GFP_KERNEL);
if (!flash)
return -ENOMEM;
flash->command = kmalloc(MAX_CMD_SIZE + (flash->fast_read ? 1 : 0),
GFP_KERNEL);
if (!flash->command) {
kfree(flash);
return -ENOMEM;
}
//以下通过flash->spi成员指向spi设备,同时spi->dev->p->driver_data私有数据指向flash,这样可以分别都访问对方!
flash->spi = spi; //绑定flash的spi设备
mutex_init(&flash->lock);
dev_set_drvdata(&spi->dev, flash); //将spi->dev->p->driver_data私有数据指向flash
/*
* Atmel, SST and Intel/Numonyx serial flash tend to power
* up with the software protection bits set
*/
//以下芯片厂家,flash芯片上电需对其写保护操作
if (JEDEC_MFR(info->jedec_id) == CFI_MFR_ATMEL ||
JEDEC_MFR(info->jedec_id) == CFI_MFR_INTEL ||
JEDEC_MFR(info->jedec_id) == CFI_MFR_SST) {
write_enable(flash);
write_sr(flash, 0);
}
if (data && data->name) //条件成立,即flash->mtd.name=“m25p80”
flash->mtd.name = data->name; //data->name="m25p80"
else
flash->mtd.name = dev_name(&spi->dev);
flash->mtd.type = MTD_NORFLASH; //flash类型
flash->mtd.writesize = 1; //最小写的单元大小
flash->mtd.flags = MTD_CAP_NORFLASH;
flash->mtd.size = info->sector_size * info->n_sectors; //flash的空间 = 一个扇区空间 * 扇区个数
flash->mtd._erase = m25p80_erase; //擦除函数(整片或部分扇区)
flash->mtd._read = m25p80_read;//读取函数
/* flash protection support for STmicro chips */
if (JEDEC_MFR(info->jedec_id) == CFI_MFR_ST) {
flash->mtd._lock = m25p80_lock;
flash->mtd._unlock = m25p80_unlock;
}
/* sst flash chips use AAI word program */
if (info->flags & SST_WRITE)
flash->mtd._write = sst_write;
else
flash->mtd._write = m25p80_write;
/* prefer "small sector" erase if possible */
if (info->flags & SECT_4K) {
flash->erase_opcode = OPCODE_BE_4K;
flash->mtd.erasesize = 4096;
} else {
flash->erase_opcode = OPCODE_SE;
flash->mtd.erasesize = info->sector_size; //一个块擦除的大小
}
if (info->flags & M25P_NO_ERASE)
flash->mtd.flags |= MTD_NO_ERASE;
ppdata.of_node = spi->dev.of_node;
flash->mtd.dev.parent = &spi->dev;
flash->page_size = info->page_size;
flash->mtd.writebufsize = flash->page_size;
if (np) {
#ifdef CONFIG_OF
/* If we were instantiated by DT, use it */
if (of_property_read_bool(np, "m25p,fast-read"))
flash->flash_read = M25P80_FAST;
else
#endif
flash->flash_read = M25P80_NORMAL;
} else {
/* If we weren't instantiated by DT, default to fast-read */
flash->flash_read = M25P80_FAST;
}
/* Some devices cannot do fast-read, no matter what DT tells us */
if (info->flags & M25P_NO_FR)
flash->flash_read = M25P80_NORMAL;
flash->flash_write = M25P80_NORMAL;
/* Quad/Dual-read mode takes precedence over fast/normal */
if ((spi->mode & (SPI_RX_QUAD | SPI_TX_QUAD)) && (info->flags & (M25P80_QUAD_READ | M25P80_QUAD_WRITE))) {
printk("m25p80: Enable Quad Mode\n");
ret = set_quad_mode(flash, info->jedec_id);
if (ret) {
dev_err(&flash->spi->dev, "quad mode not supported\n");
return ret;
}
if ((spi->mode & SPI_RX_QUAD) && (info->flags & M25P80_QUAD_READ)) {
flash->flash_read = M25P80_QUAD;
}
if ((spi->mode & SPI_TX_QUAD) && (info->flags & M25P80_QUAD_WRITE)) {
flash->flash_write = M25P80_QUAD;
}
} else if ((spi->mode & SPI_RX_DUAL) && (info->flags & M25P80_DUAL_READ)) {
printk("m25p80: Enable Dual Read Mode\n");
flash->flash_read = M25P80_DUAL;
} else if ((spi->mode & SPI_TX_DUAL) && (info->flags & M25P80_DUAL_WRITE)) {
printk("m25p80: Enable Dual Write Mode\n");
flash->flash_write = M25P80_DUAL;
}
/* Default commands */
switch (flash->flash_read) {
case M25P80_QUAD:
flash->read_opcode = OPCODE_QUAD_READ;
break;
case M25P80_DUAL:
flash->read_opcode = OPCODE_DUAL_READ;
break;
case M25P80_FAST:
flash->read_opcode = OPCODE_FAST_READ;
break;
case M25P80_NORMAL:
flash->read_opcode = OPCODE_NORM_READ;
break;
default:
dev_err(&flash->spi->dev, "No Read opcode defined\n");
return -EINVAL;
}
if(flash->flash_write & M25P80_QUAD)
flash->program_opcode = OPCODE_QUAD_PP;
else
flash->program_opcode = OPCODE_PP;
if (info->addr_width)
flash->addr_width = info->addr_width;
else {
/* enable 4-byte addressing if the device exceeds 16MiB */
if (flash->mtd.size > 0x1000000) {
flash->addr_width = 4;
set_4byte(flash, info->jedec_id, 1);
} else
flash->addr_width = 3;
}
dev_info(&spi->dev, "%s (%lld Kbytes)\n", id->name,
(long long)flash->mtd.size >> 10);
pr_debug("mtd .name = %s, .size = 0x%llx (%lldMiB) "
".erasesize = 0x%.8x (%uKiB) .numeraseregions = %d\n",
flash->mtd.name,
(long long)flash->mtd.size, (long long)(flash->mtd.size >> 20),
flash->mtd.erasesize, flash->mtd.erasesize / 1024,
flash->mtd.numeraseregions);
if (flash->mtd.numeraseregions)
for (i = 0; i < flash->mtd.numeraseregions; i++)
pr_debug("mtd.eraseregions[%d] = { .offset = 0x%llx, "
".erasesize = 0x%.8x (%uKiB), "
".numblocks = %d }\n",
i, (long long)flash->mtd.eraseregions[i].offset,
flash->mtd.eraseregions[i].erasesize,
flash->mtd.eraseregions[i].erasesize / 1024,
flash->mtd.eraseregions[i].numblocks);
/* partitions should match sector boundaries; and it may be good to
* use readonly partitions for writeprotected sectors (BP2..BP0).
*/
return mtd_device_parse_register(&flash->mtd, NULL, &ppdata,
data ? data->parts : NULL,
data ? data->nr_parts : 0);
}
5.3 SPI核心层与驱动层消息发送、接收机制
获取从设备芯片厂商ID,jedec_probe(...)
static const struct spi_device_id *jedec_probe(struct spi_device *spi)
{
int tmp;
u8 code = OPCODE_RDID;
u8 id[5];
u32 jedec;
u16 ext_jedec;
struct flash_info *info;
/* JEDEC also defines an optional "extended device information"
* string for after vendor-specific data, after the three bytes
* we use here. Supporting some chips might require using it.
*/
tmp = spi_write_then_read(spi, &code, 1, id, 5);
if (tmp < 0) {
pr_debug("%s: error %d reading JEDEC ID\n",
dev_name(&spi->dev), tmp);
return ERR_PTR(tmp);
}
jedec = id[0];
jedec = jedec << 8;
jedec |= id[1];
jedec = jedec << 8;
jedec |= id[2];
ext_jedec = id[3] << 8 | id[4];
for (tmp = 0; tmp < ARRAY_SIZE(m25p_ids) - 1; tmp++) {
info = (void *)m25p_ids[tmp].driver_data;
if (info->jedec_id == jedec) {
if (info->ext_id != 0 && info->ext_id != ext_jedec)
continue;
return &m25p_ids[tmp];
}
}
dev_err(&spi->dev, "unrecognized JEDEC id %06x\n", jedec);
return ERR_PTR(-ENODEV);
}
int spi_write_then_read(struct spi_device *spi,
const void *txbuf, unsigned n_tx,
void *rxbuf, unsigned n_rx)
{
static DEFINE_MUTEX(lock);
int status;
struct spi_message message;
struct spi_transfer x[2];
u8 *local_buf;
/* Use preallocated DMA-safe buffer if we can. We can't avoid
* copying here, (as a pure convenience thing), but we can
* keep heap costs out of the hot path unless someone else is
* using the pre-allocated buffer or the transfer is too large.
*/
if ((n_tx + n_rx) > SPI_BUFSIZ || !mutex_trylock(&lock)) {
local_buf = kmalloc(max((unsigned)SPI_BUFSIZ, n_tx + n_rx), //分配一个spi发送和接收的缓冲区
GFP_KERNEL | GFP_DMA);
if (!local_buf)
return -ENOMEM;
} else {
local_buf = buf;
}
spi_message_init(&message); //初始化一个spi消息链表
memset(x, 0, sizeof x);
if (n_tx) {
x[0].len = n_tx;
spi_message_add_tail(&x[0], &message); //将x[0]消息加入到链表message中
}
if (n_rx) {
x[1].len = n_rx;
spi_message_add_tail(&x[1], &message); //将x[1]消息加入到链表message中
}
//对加入到消息队列message中的spi发送、接收指针重定向到local_buf队列
memcpy(local_buf, txbuf, n_tx);
x[0].tx_buf = local_buf;
x[1].rx_buf = local_buf + n_tx;
/* do the i/o */
status = spi_sync(spi, &message); //重点讲解!
if (status == 0)
memcpy(rxbuf, x[1].rx_buf, n_rx); //复制spi接收数据
if (x[0].tx_buf == buf)
mutex_unlock(&lock);
else
kfree(local_buf);
return status;
}
spi_sync(...)同步消息接口:
int spi_sync(struct spi_device *spi, struct spi_message *message)
{
return __spi_sync(spi, message, 0);
}static int __spi_sync(struct spi_device *spi, struct spi_message *message,
int bus_locked)
{
DECLARE_COMPLETION_ONSTACK(done);
int status;
struct spi_master *master = spi->master;
message->complete = spi_complete;
message->context = &done;
if (!bus_locked)
mutex_lock(&master->bus_lock_mutex);
status = spi_async_locked(spi, message); //见下面
if (!bus_locked)
mutex_unlock(&master->bus_lock_mutex);
if (status == 0) {
wait_for_completion(&done);
status = message->status;
}
message->context = NULL;
return status;
}
int spi_async_locked(struct spi_device *spi, struct spi_message *message)
{
struct spi_master *master = spi->master;
int ret;
unsigned long flags;
spin_lock_irqsave(&master->bus_lock_spinlock, flags);
ret = __spi_async(spi, message);
spin_unlock_irqrestore(&master->bus_lock_spinlock, flags);
return ret;
}static int __spi_async(struct spi_device *spi, struct spi_message *message)
{
struct spi_master *master = spi->master; //获取spi控制器
struct spi_transfer *xfer;
/* Half-duplex links include original MicroWire, and ones with
* only one data pin like SPI_3WIRE (switches direction) or where
* either MOSI or MISO is missing. They can also be caused by
* software limitations.
*/
if ((master->flags & SPI_MASTER_HALF_DUPLEX)
|| (spi->mode & SPI_3WIRE)) {
unsigned flags = master->flags;
list_for_each_entry(xfer, &message->transfers, transfer_list) {
if (xfer->rx_buf && xfer->tx_buf)
return -EINVAL;
if ((flags & SPI_MASTER_NO_TX) && xfer->tx_buf)
return -EINVAL;
if ((flags & SPI_MASTER_NO_RX) && xfer->rx_buf)
return -EINVAL;
}
}
/**
* Set transfer bits_per_word and max speed as spi device default if
* it is not set for this transfer.
*/
list_for_each_entry(xfer, &message->transfers, transfer_list) {
if (!xfer->bits_per_word)
xfer->bits_per_word = spi->bits_per_word;
if (!xfer->speed_hz)
xfer->speed_hz = spi->max_speed_hz;
if (master->bits_per_word_mask) {
/* Only 32 bits fit in the mask */
if (xfer->bits_per_word > 32)
return -EINVAL;
if (!(master->bits_per_word_mask &
BIT(xfer->bits_per_word - 1)))
return -EINVAL;
}
if (xfer->tx_buf && !xfer->tx_nbits)
xfer->tx_nbits = SPI_NBITS_SINGLE;
if (xfer->rx_buf && !xfer->rx_nbits)
xfer->rx_nbits = SPI_NBITS_SINGLE;
/* check transfer tx/rx_nbits:
* 1. keep the value is not out of single, dual and quad
* 2. keep tx/rx_nbits is contained by mode in spi_device
* 3. if SPI_3WIRE, tx/rx_nbits should be in single
*/
if (xfer->tx_buf) {
if (xfer->tx_nbits != SPI_NBITS_SINGLE &&
xfer->tx_nbits != SPI_NBITS_DUAL &&
xfer->tx_nbits != SPI_NBITS_QUAD)
return -EINVAL;
if ((xfer->tx_nbits == SPI_NBITS_DUAL) &&
!(spi->mode & (SPI_TX_DUAL | SPI_TX_QUAD)))
return -EINVAL;
if ((xfer->tx_nbits == SPI_NBITS_QUAD) &&
!(spi->mode & SPI_TX_QUAD))
return -EINVAL;
if ((spi->mode & SPI_3WIRE) &&
(xfer->tx_nbits != SPI_NBITS_SINGLE))
return -EINVAL;
}
/* check transfer rx_nbits */
if (xfer->rx_buf) {
if (xfer->rx_nbits != SPI_NBITS_SINGLE &&
xfer->rx_nbits != SPI_NBITS_DUAL &&
xfer->rx_nbits != SPI_NBITS_QUAD)
return -EINVAL;
if ((xfer->rx_nbits == SPI_NBITS_DUAL) &&
!(spi->mode & (SPI_RX_DUAL | SPI_RX_QUAD)))
return -EINVAL;
if ((xfer->rx_nbits == SPI_NBITS_QUAD) &&
!(spi->mode & SPI_RX_QUAD))
return -EINVAL;
if ((spi->mode & SPI_3WIRE) &&
(xfer->rx_nbits != SPI_NBITS_SINGLE))
return -EINVAL;
}
}
message->spi = spi;
message->status = -EINPROGRESS;
return master->transfer(spi, message); //这个部分很重要!
}int spi_bitbang_transfer(struct spi_device *spi, struct spi_message *m)
{
struct spi_bitbang *bitbang;
unsigned long flags;
int status = 0;
m->actual_length = 0;
m->status = -EINPROGRESS;
bitbang = spi_master_get_devdata(spi->master);
spin_lock_irqsave(&bitbang->lock, flags);
if (!spi->max_speed_hz)
status = -ENETDOWN;
else {
list_add_tail(&m->queue, &bitbang->queue);
queue_work(bitbang->workqueue, &bitbang->work); //将bitbang->work加入到bitbang->workqueue工作队列中
}
spin_unlock_irqrestore(&bitbang->lock, flags);
return status;
}a. 初始化一个工作,并绑定回调函数
INIT_WORK(&bitbang->work, bitbang_work); //初始化一个工作,并绑定该工作的回调函数 bitbang->workqueue = create_singlethread_workqueue( //创建bitbang->workqueue工作队列
dev_name(master->dev.parent));bitbang = spi_master_get_devdata(spi->master); //获取spi设备的bitbang
//......
list_add_tail(&m->queue, &bitbang->queue); //将m消息加入到bitbang队列中
queue_work(bitbang->workqueue, &bitbang->work); //将bitbang->work加入到bitbang->workqueue工作队列中,同时会唤醒a.中的bitbang_work函数static void bitbang_work(struct work_struct *work)
{
//...
list_for_each_entry_safe(m, _m, &bitbang->queue, queue) { //遍历有多少个消息队列
//......
list_for_each_entry (t, &m->transfers, transfer_list) { //每个消息队列中有多少消息
//......
status = bitbang->txrx_bufs(spi, t); //处理消息发送、接收
//......
}static int nuc970_spi0_txrx(struct spi_device *spi, struct spi_transfer *t)
{
struct nuc970_spi *hw = (struct nuc970_spi *)to_hw(spi);
hw->tx = t->tx_buf;
hw->rx = t->rx_buf;
hw->len = t->len;
hw->count = 0;
if(t->tx_nbits & SPI_NBITS_DUAL) {
__raw_writel(__raw_readl(hw->regs + REG_CNTRL) | (0x5 << 20), hw->regs + REG_CNTRL);
} else if(t->tx_nbits & SPI_NBITS_QUAD) {
__raw_writel(__raw_readl(hw->regs + REG_CNTRL) | (0x3 << 20), hw->regs + REG_CNTRL);
}
if(t->rx_nbits & SPI_NBITS_DUAL) {
__raw_writel(__raw_readl(hw->regs + REG_CNTRL) | (0x4 << 20), hw->regs + REG_CNTRL);
} else if(t->rx_nbits & SPI_NBITS_QUAD) {
__raw_writel(__raw_readl(hw->regs + REG_CNTRL) | (0x2 << 20), hw->regs + REG_CNTRL);
}
__raw_writel(hw_txbyte(hw, 0x0), hw->regs + REG_TX0); //发送数据,当前数据字节发送完将触发中断nuc970_spi0_irq(...)
nuc970_spi0_gobusy(hw);
wait_for_completion(&hw->done); //等待完成量,否则一直在这里进入休眠阻塞
if(spi->mode & (SPI_TX_DUAL | SPI_TX_QUAD | SPI_RX_DUAL | SPI_RX_QUAD))
__raw_writel(__raw_readl(hw->regs + REG_CNTRL) & ~(0x7 << 20), hw->regs + REG_CNTRL);
return hw->count;
}a.先配置发送、接收字节寄存器
b.发送数据,然后进入busy忙等待
c.通过完成量判断当前spi message消息是否全部发送、接收完,完成量状态由d.更新
d.spi中断处理函数
static irqreturn_t nuc970_spi0_irq(int irq, void *dev)
{
struct nuc970_spi *hw = dev;
unsigned int status;
unsigned int count = hw->count;
status = __raw_readl(hw->regs + REG_CNTRL);
__raw_writel(status, hw->regs + REG_CNTRL);
if (status & ENFLG) {
hw->count++;
if (hw->rx)
hw->rx[count] = __raw_readl(hw->regs + REG_RX0); //接收消息
count++;
//确定数据是否发送完,否则触发完成量
if (count < hw->len) { //hw->len表示当前发送、接收数据的总和,count计算的是发送、和接收的次数
__raw_writel(hw_txbyte(hw, count), hw->regs + REG_TX0); //发送消息
nuc970_spi0_gobusy(hw);
} else {
complete(&hw->done);
}
return IRQ_HANDLED;
}
complete(&hw->done);
return IRQ_HANDLED;
}5.4.m25p80擦除flash接口
static int m25p80_erase(struct mtd_info *mtd, struct erase_info *instr)
{
struct m25p *flash = mtd_to_m25p(mtd);
u32 addr,len;
uint32_t rem;
pr_debug("%s: %s at 0x%llx, len %lld\n", dev_name(&flash->spi->dev),
__func__, (long long)instr->addr,
(long long)instr->len);
div_u64_rem(instr->len, mtd->erasesize, &rem);
if (rem)
return -EINVAL;
addr = instr->addr;
len = instr->len;
mutex_lock(&flash->lock);
/* whole-chip erase? */
if (len == flash->mtd.size) { //擦除的len等于flash的空间,表示整片flash擦除
if (erase_chip(flash)) {
instr->state = MTD_ERASE_FAILED;
mutex_unlock(&flash->lock);
return -EIO;
}
/* REVISIT in some cases we could speed up erasing large regions
* by using OPCODE_SE instead of OPCODE_BE_4K. We may have set up
* to use "small sector erase", but that's not always optimal.
*/
/* "sector"-at-a-time erase */
} else {
while (len) {
if (erase_sector(flash, addr)) { //部分擦除
instr->state = MTD_ERASE_FAILED;
mutex_unlock(&flash->lock);
return -EIO;
}
addr += mtd->erasesize; //擦除是按块
len -= mtd->erasesize;
}
}
mutex_unlock(&flash->lock);
instr->state = MTD_ERASE_DONE;
mtd_erase_callback(instr);
return 0;
}
static int erase_chip(struct m25p *flash)
{
pr_debug("%s: %s %lldKiB\n", dev_name(&flash->spi->dev), __func__,
(long long)(flash->mtd.size >> 10));
/* Wait until finished previous write command. */
if (wait_till_ready(flash))
return 1;
/* Send write enable, then erase commands. */
write_enable(flash);
/* Set up command buffer. */
flash->command[0] = OPCODE_CHIP_ERASE;
spi_write(flash->spi, flash->command, 1);
return 0;
}static int erase_sector(struct m25p *flash, u32 offset)
{
pr_debug("%s: %s %dKiB at 0x%08x\n", dev_name(&flash->spi->dev),
__func__, flash->mtd.erasesize / 1024, offset);
/* Wait until finished previous write command. */
if (wait_till_ready(flash))
return 1;
/* Send write enable, then erase commands. */
write_enable(flash);
/* Set up command buffer. */
flash->command[0] = flash->erase_opcode;
m25p_addr2cmd(flash, offset, flash->command);
spi_write(flash->spi, flash->command, m25p_cmdsz(flash));
return 0;
}5.5.m25p80读取flash接口
static int m25p80_read(struct mtd_info *mtd, loff_t from, size_t len,
size_t *retlen, u_char *buf)
{
struct m25p *flash = mtd_to_m25p(mtd);
struct spi_transfer t[2];
struct spi_message m;
uint8_t opcode;
int dummy;
pr_debug("%s: %s from 0x%08x, len %zd\n", dev_name(&flash->spi->dev),
__func__, (u32)from, len);
spi_message_init(&m);
memset(t, 0, (sizeof t));
dummy = m25p80_dummy_cycles_read(flash);
if (dummy < 0) {
dev_err(&flash->spi->dev, "No valid read command supported\n");
return -EINVAL;
}
/* NOTE:
* OPCODE_FAST_READ (if available) is faster.
* Should add 1 byte DUMMY_BYTE.
*/
t[0].tx_buf = flash->command;
t[0].len = m25p_cmdsz(flash) + dummy;
spi_message_add_tail(&t[0], &m);
t[1].rx_buf = buf;
t[1].rx_nbits = m25p80_rx_nbits(flash);
t[1].len = len;
spi_message_add_tail(&t[1], &m);
mutex_lock(&flash->lock);
/* Wait till previous write/erase is done. */
if (wait_till_ready(flash)) {
/* REVISIT status return?? */
mutex_unlock(&flash->lock);
return 1;
}
/* FIXME switch to OPCODE_FAST_READ. It's required for higher
* clocks; and at this writing, every chip this driver handles
* supports that opcode.
*/
/* Set up the write data buffer. */
opcode = flash->read_opcode;
flash->command[0] = opcode;
m25p_addr2cmd(flash, from, flash->command);
spi_sync(flash->spi, &m); //内部会调用spi驱动层代码,重要,待分析!!!
*retlen = m.actual_length - m25p_cmdsz(flash) - dummy;
mutex_unlock(&flash->lock);
return 0;
}5.6.m25p80写flash接口
static int m25p80_read(struct mtd_info *mtd, loff_t from, size_t len,
size_t *retlen, u_char *buf)
{
struct m25p *flash = mtd_to_m25p(mtd);
struct spi_transfer t[2];
struct spi_message m;
uint8_t opcode;
int dummy;
pr_debug("%s: %s from 0x%08x, len %zd\n", dev_name(&flash->spi->dev),
__func__, (u32)from, len);
spi_message_init(&m);
memset(t, 0, (sizeof t));
dummy = m25p80_dummy_cycles_read(flash);
if (dummy < 0) {
dev_err(&flash->spi->dev, "No valid read command supported\n");
return -EINVAL;
}
/* NOTE:
* OPCODE_FAST_READ (if available) is faster.
* Should add 1 byte DUMMY_BYTE.
*/
t[0].tx_buf = flash->command;
t[0].len = m25p_cmdsz(flash) + dummy;
spi_message_add_tail(&t[0], &m);
t[1].rx_buf = buf;
t[1].rx_nbits = m25p80_rx_nbits(flash);
t[1].len = len;
spi_message_add_tail(&t[1], &m);
mutex_lock(&flash->lock);
/* Wait till previous write/erase is done. */
if (wait_till_ready(flash)) {
/* REVISIT status return?? */
mutex_unlock(&flash->lock);
return 1;
}
/* FIXME switch to OPCODE_FAST_READ. It's required for higher
* clocks; and at this writing, every chip this driver handles
* supports that opcode.
*/
/* Set up the write data buffer. */
opcode = flash->read_opcode;
flash->command[0] = opcode;
m25p_addr2cmd(flash, from, flash->command);
spi_sync(flash->spi, &m); //内部会调用spi驱动层代码,重要,待分析!!!
*retlen = m.actual_length - m25p_cmdsz(flash) - dummy;
mutex_unlock(&flash->lock);
return 0;
}5.7.mtd层flash分区注册
return mtd_device_parse_register(&flash->mtd, NULL, &ppdata,
data ? data->parts : NULL,
data ? data->nr_parts : 0);int mtd_device_parse_register(struct mtd_info *mtd, const char * const *types,
struct mtd_part_parser_data *parser_data,
const struct mtd_partition *parts,
int nr_parts)
{
int err;
struct mtd_partition *real_parts;
err = parse_mtd_partitions(mtd, types, &real_parts, parser_data);
if (err <= 0 && nr_parts && parts) {
//复制parts分区到内存
real_parts = kmemdup(parts, sizeof(*parts) * nr_parts,
GFP_KERNEL);
if (!real_parts)
err = -ENOMEM;
else
err = nr_parts; //分区个数
}
if (err > 0) { //err > 0条件成立
err = add_mtd_partitions(mtd, real_parts, err); //增加MTD分区
kfree(real_parts);
} else if (err == 0) {
err = add_mtd_device(mtd); //增加MTD设备
if (err == 1)
err = -ENODEV;
}
return err;
}5.8.增加分区add_mtd_partitions(...)
int add_mtd_partitions(struct mtd_info *master,
const struct mtd_partition *parts,
int nbparts)
{
struct mtd_part *slave;
uint64_t cur_offset = 0;
int i;
printk(KERN_NOTICE "Creating %d MTD partitions on \"%s\":\n", nbparts, master->name);
for (i = 0; i < nbparts; i++) {
slave = allocate_partition(master, parts + i, i, cur_offset); //分配一个分区
if (IS_ERR(slave))
return PTR_ERR(slave);
mutex_lock(&mtd_partitions_mutex);
list_add(&slave->list, &mtd_partitions);
mutex_unlock(&mtd_partitions_mutex);
add_mtd_device(&slave->mtd);
cur_offset = slave->offset + slave->mtd.size;
}
return 0;
}5.9.分配一个分区allocate_partition(...)
static struct mtd_part *allocate_partition(struct mtd_info *master,
const struct mtd_partition *part, int partno,
uint64_t cur_offset)
{
struct mtd_part *slave;
char *name;
/* allocate the partition structure */
slave = kzalloc(sizeof(*slave), GFP_KERNEL);
name = kstrdup(part->name, GFP_KERNEL); //分区名称
if (!name || !slave) {
printk(KERN_ERR"memory allocation error while creating partitions for \"%s\"\n",
master->name);
kfree(name);
kfree(slave);
return ERR_PTR(-ENOMEM);
}
/* set up the MTD object for this partition */
slave->mtd.type = master->type; //flash类型,如MTD_NORFLASH
slave->mtd.flags = master->flags & ~part->mask_flags;
slave->mtd.size = part->size; //分区大小
slave->mtd.writesize = master->writesize; //分区最小写单元,NOR-FLASH为1个字节,NAND-FLASH为一页
slave->mtd.writebufsize = master->writebufsize;
slave->mtd.oobsize = master->oobsize; //OOB大小,包括ECC检验
slave->mtd.oobavail = master->oobavail;
slave->mtd.subpage_sft = master->subpage_sft;
slave->mtd.name = name; //分区名称,如内核“kernel”,文件系统“rootfs”
slave->mtd.owner = master->owner;
slave->mtd.backing_dev_info = master->backing_dev_info;
/* NOTE: we don't arrange MTDs as a tree; it'd be error-prone
* to have the same data be in two different partitions.
*/
slave->mtd.dev.parent = master->dev.parent;
slave->mtd._read = part_read; //分区读
slave->mtd._write = part_write; //分区写
if (master->_panic_write)
slave->mtd._panic_write = part_panic_write; //内核恐慌(崩溃)时写操作
if (master->_point && master->_unpoint) {
slave->mtd._point = part_point;
slave->mtd._unpoint = part_unpoint;
}
if (master->_get_unmapped_area)
slave->mtd._get_unmapped_area = part_get_unmapped_area;
if (master->_read_oob)
slave->mtd._read_oob = part_read_oob; //读oob ecc校验
if (master->_write_oob)
slave->mtd._write_oob = part_write_oob;
if (master->_read_user_prot_reg)
slave->mtd._read_user_prot_reg = part_read_user_prot_reg;
if (master->_read_fact_prot_reg)
slave->mtd._read_fact_prot_reg = part_read_fact_prot_reg;
if (master->_write_user_prot_reg)
slave->mtd._write_user_prot_reg = part_write_user_prot_reg;
if (master->_lock_user_prot_reg)
slave->mtd._lock_user_prot_reg = part_lock_user_prot_reg;
if (master->_get_user_prot_info)
slave->mtd._get_user_prot_info = part_get_user_prot_info;
if (master->_get_fact_prot_info)
slave->mtd._get_fact_prot_info = part_get_fact_prot_info;
if (master->_sync)
slave->mtd._sync = part_sync;
if (!partno && !master->dev.class && master->_suspend &&
master->_resume) {
slave->mtd._suspend = part_suspend;
slave->mtd._resume = part_resume;
}
if (master->_writev)
slave->mtd._writev = part_writev;
if (master->_lock)
slave->mtd._lock = part_lock;
if (master->_unlock)
slave->mtd._unlock = part_unlock;
if (master->_is_locked)
slave->mtd._is_locked = part_is_locked;
if (master->_block_isbad)
slave->mtd._block_isbad = part_block_isbad;
if (master->_block_markbad)
slave->mtd._block_markbad = part_block_markbad;
slave->mtd._erase = part_erase; //分区擦除
slave->master = master;
slave->offset = part->offset;
if (slave->offset == MTDPART_OFS_APPEND)
slave->offset = cur_offset;
if (slave->offset == MTDPART_OFS_NXTBLK) {
slave->offset = cur_offset;
if (mtd_mod_by_eb(cur_offset, master) != 0) {
/* Round up to next erasesize */
slave->offset = (mtd_div_by_eb(cur_offset, master) + 1) * master->erasesize;
printk(KERN_NOTICE "Moving partition %d: "
"0x%012llx -> 0x%012llx\n", partno,
(unsigned long long)cur_offset, (unsigned long long)slave->offset);
}
}
if (slave->offset == MTDPART_OFS_RETAIN) {
slave->offset = cur_offset;
if (master->size - slave->offset >= slave->mtd.size) {
slave->mtd.size = master->size - slave->offset
- slave->mtd.size;
} else {
printk(KERN_ERR "mtd partition \"%s\" doesn't have enough space: %#llx < %#llx, disabled\n",
part->name, master->size - slave->offset,
slave->mtd.size);
/* register to preserve ordering */
goto out_register;
}
}
if (slave->mtd.size == MTDPART_SIZ_FULL)
slave->mtd.size = master->size - slave->offset;
printk(KERN_NOTICE "0x%012llx-0x%012llx : \"%s\"\n", (unsigned long long)slave->offset,
(unsigned long long)(slave->offset + slave->mtd.size), slave->mtd.name);
/* let's do some sanity checks */
if (slave->offset >= master->size) {
/* let's register it anyway to preserve ordering */
slave->offset = 0;
slave->mtd.size = 0;
printk(KERN_ERR"mtd: partition \"%s\" is out of reach -- disabled\n",
part->name);
goto out_register;
}
if (slave->offset + slave->mtd.size > master->size) {
slave->mtd.size = master->size - slave->offset;
printk(KERN_WARNING"mtd: partition \"%s\" extends beyond the end of device \"%s\" -- size truncated to %#llx\n",
part->name, master->name, (unsigned long long)slave->mtd.size);
}
if (master->numeraseregions > 1) {
/* Deal with variable erase size stuff */
int i, max = master->numeraseregions;
u64 end = slave->offset + slave->mtd.size;
struct mtd_erase_region_info *regions = master->eraseregions;
/* Find the first erase regions which is part of this
* partition. */
for (i = 0; i < max && regions[i].offset <= slave->offset; i++)
;
/* The loop searched for the region _behind_ the first one */
if (i > 0)
i--;
/* Pick biggest erasesize */
for (; i < max && regions[i].offset < end; i++) {
if (slave->mtd.erasesize < regions[i].erasesize) {
slave->mtd.erasesize = regions[i].erasesize;
}
}
BUG_ON(slave->mtd.erasesize == 0);
} else {
/* Single erase size */
slave->mtd.erasesize = master->erasesize;
}
if ((slave->mtd.flags & MTD_WRITEABLE) &&
mtd_mod_by_eb(slave->offset, &slave->mtd)) {
/* Doesn't start on a boundary of major erase size */
/* FIXME: Let it be writable if it is on a boundary of
* _minor_ erase size though */
slave->mtd.flags &= ~MTD_WRITEABLE;
printk(KERN_WARNING"mtd: partition \"%s\" doesn't start on an erase block boundary -- force read-only\n",
part->name);
}
if ((slave->mtd.flags & MTD_WRITEABLE) &&
mtd_mod_by_eb(slave->mtd.size, &slave->mtd)) {
slave->mtd.flags &= ~MTD_WRITEABLE;
printk(KERN_WARNING"mtd: partition \"%s\" doesn't end on an erase block -- force read-only\n",
part->name);
}
slave->mtd.ecclayout = master->ecclayout;
slave->mtd.ecc_strength = master->ecc_strength;
slave->mtd.bitflip_threshold = master->bitflip_threshold;
if (master->_block_isbad) {
uint64_t offs = 0;
while (offs < slave->mtd.size) {
if (mtd_block_isbad(master, offs + slave->offset))
slave->mtd.ecc_stats.badblocks++;
offs += slave->mtd.erasesize;
}
}
out_register:
return slave;
}int add_mtd_device(struct mtd_info *mtd)
{
struct mtd_notifier *not;
int i, error;
if (!mtd->backing_dev_info) {
switch (mtd->type) {
case MTD_RAM:
mtd->backing_dev_info = &mtd_bdi_rw_mappable;
break;
case MTD_ROM:
mtd->backing_dev_info = &mtd_bdi_ro_mappable;
break;
default:
mtd->backing_dev_info = &mtd_bdi_unmappable;
break;
}
}
BUG_ON(mtd->writesize == 0);
mutex_lock(&mtd_table_mutex);
i = idr_alloc(&mtd_idr, mtd, 0, 0, GFP_KERNEL);
if (i < 0)
goto fail_locked;
mtd->index = i;
mtd->usecount = 0;
/* default value if not set by driver */
if (mtd->bitflip_threshold == 0)
mtd->bitflip_threshold = mtd->ecc_strength;
if (is_power_of_2(mtd->erasesize))
mtd->erasesize_shift = ffs(mtd->erasesize) - 1;
else
mtd->erasesize_shift = 0;
if (is_power_of_2(mtd->writesize))
mtd->writesize_shift = ffs(mtd->writesize) - 1;
else
mtd->writesize_shift = 0;
mtd->erasesize_mask = (1 << mtd->erasesize_shift) - 1;
mtd->writesize_mask = (1 << mtd->writesize_shift) - 1;
/* Some chips always power up locked. Unlock them now */
if ((mtd->flags & MTD_WRITEABLE) && (mtd->flags & MTD_POWERUP_LOCK)) {
error = mtd_unlock(mtd, 0, mtd->size);
if (error && error != -EOPNOTSUPP)
printk(KERN_WARNING
"%s: unlock failed, writes may not work\n",
mtd->name);
}
/* Caller should have set dev.parent to match the
* physical device.
*/
mtd->dev.type = &mtd_devtype;
mtd->dev.class = &mtd_class;
mtd->dev.devt = MTD_DEVT(i);
dev_set_name(&mtd->dev, "mtd%d", i);
dev_set_drvdata(&mtd->dev, mtd);
if (device_register(&mtd->dev) != 0)
goto fail_added;
if (MTD_DEVT(i))
device_create(&mtd_class, mtd->dev.parent,
MTD_DEVT(i) + 1,
NULL, "mtd%dro", i);
pr_debug("mtd: Giving out device %d to %s\n", i, mtd->name);
/* No need to get a refcount on the module containing
the notifier, since we hold the mtd_table_mutex */
list_for_each_entry(not, &mtd_notifiers, list)
not->add(mtd);
mutex_unlock(&mtd_table_mutex);
/* We _know_ we aren't being removed, because
our caller is still holding us here. So none
of this try_ nonsense, and no bitching about it
either. :) */
__module_get(THIS_MODULE);
return 0;
fail_added:
idr_remove(&mtd_idr, i);
fail_locked:
mutex_unlock(&mtd_table_mutex);
return 1;
}
总结:
DUAD SPI的读写速度是普通序列式闪存的4-6倍,DI和DO是双向的,称作DI0 DI1,同时/WP和/HOLD也变成输入输出管脚,称作DI2 DI3。