Proc 文件系统实现原理
目录
1. Proc文件系统主要数据结构 1
2. Proc 文件系统挂载 2
2.1 proc文件系统注册 2
2.2 proc挂载 2
3. proc文件操作 3
3.2 文件打开 5
3.3文件读取 7
Proc文件系统主要数据结构

文件或者目录打开的时候会创建一个结构体proc_inode,用于连接vfs,下面是它的主要成员说明:
| struct proc_inode |
|
| struct proc_dir_entry *pde |
指向该目录/文件对应的proc_dir_entry |
| struct inode vfs_inode |
Vfs的inode,用宏PROC_I(inode)可以通过inode得到对应的proc_inode |
每一个文件或者目录创建的时候都会构建一个结构体proc_dir_entry用于管理这个文件或者目录,与proc_inode不同的是,proc_dir_entry在文件或者目录创建的时候就会产生,但是proc_inode只有在打开的时候才会产生:
| struct proc_dir_entry |
|
| umode_t mode; |
文件类型:包含S_IFDIR(目录) 或者S_IFREG(普通文件)等等 |
| const struct inode_operations *proc_iops |
文件或者目录打开的时候会赋给vfs_inode->i_op |
| const struct file_operations *proc_fops |
如果是目录在打开的时候付给vfs_inode->i_fop,如果是普通文件会赋值为proc_reg_file_ops |
| struct proc_dir_entry *parent |
指向父目录 |
| struct rb_root subdir |
用于挂接子目录的红黑树 |
| struct rb_node subdir_node |
用于挂到父目录的subdir中 |
| u8 namelen |
目录项的名称长度 |
| char name[] |
存放目录项名 |
Proc 文件系统挂载
2.1 proc文件系统注册
static struct file_system_type proc_fs_type = {
.name = "proc",
.mount = proc_mount,
.kill_sb = proc_kill_sb,
.fs_flags = FS_USERNS_MOUNT,
};
void __init proc_root_init(void)
{
……
err = register_filesystem(&proc_fs_type); //将proc_fs_type 挂载到全局链表file_systems
…….
proc_mkdir("fs", NULL); //proc目录下创建二级子目录
proc_mkdir("driver", NULL);
……
}2.2 proc挂载
挂载流程如下:
sget_userns: 这个函数主要做了三件事:1,首先在链表proc_fs_type->fs_supers 上找符合要求的super_block避免重复挂载;2,如果没有找到就分配一个super_block;3,初始化super_block的相关字段,并将其挂载到全局链表super_blocks和proc_fs_type->fs_supers上。
下面是函数proc_fill_super实现的代码,去掉了一些检查相关的逻辑代码:
int proc_fill_super(struct super_block *s, void *data, int silent)
{
struct pid_namespace *ns = get_pid_ns(s->s_fs_info);
struct inode *root_inode;
int ret;
s->s_iflags |= SB_I_USERNS_VISIBLE | SB_I_NOEXEC | SB_I_NODEV;
s->s_flags |= MS_NODIRATIME | MS_NOSUID | MS_NOEXEC;
s->s_blocksize = 1024;
s->s_blocksize_bits = 10;
s->s_magic = PROC_SUPER_MAGIC;
s->s_op = &proc_sops;
s->s_time_gran = 1;
s->s_stack_depth = FILESYSTEM_MAX_STACK_DEPTH;
pde_get(&proc_root);
root_inode = proc_get_inode(s, &proc_root); //创建inode以便与vfs衔接
s->s_root = d_make_root(root_inode); //创建根目录的dentry
ret = proc_setup_self(s); //创建/proc/self目录
return proc_setup_thread_self(s); //创建/proc/thread-self目录
}proc_root是静态定义的,如下:
struct proc_dir_entry proc_root = {
.low_ino = PROC_ROOT_INO,
.namelen = 5,
.mode = S_IFDIR | S_IRUGO | S_IXUGO,
.nlink = 2,
.count = ATOMIC_INIT(1),
.proc_iops = &proc_root_inode_operations,
.proc_fops = &proc_root_operations,
.parent = &proc_root,
.subdir = RB_ROOT,
.name = "/proc",
};proc文件操作
3.1 创建目录/文件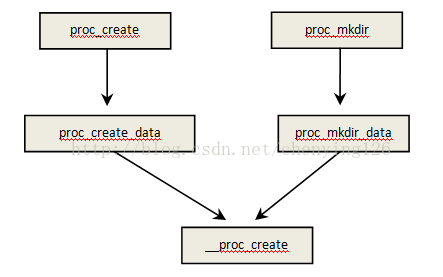
proc_create用于创建proc文件;proc_mkdir用于创建proc目录。接口__proc_create用于完成目录/文件创建的主要工作。
目录创建
void __init proc_root_init(void)
{
……
proc_mkdir("fs", NULL);
……
}
struct proc_dir_entry *proc_mkdir_data(const char *name, umode_t mode,
struct proc_dir_entry *parent, void *data)
{
struct proc_dir_entry *ent;
if (mode == 0)
mode = S_IRUGO | S_IXUGO;
// 目录或者文件都是由结构体proc_dir_entry 来描述,S_IFDIR表示创建的是目录
ent = __proc_create(&parent, name, S_IFDIR | mode, 2);
if (ent) {
ent->data = data;
ent->proc_fops = &proc_dir_operations; // file_operations打开的时候会赋给inode
ent->proc_iops = &proc_dir_inode_operations; // inode_operations打开的时候会赋给inode
parent->nlink++;
//建立层次关系,proc_dir_entry->parent指向父目录,proc_dir_entry->subdir_node插入到parent->subdir中
if (proc_register(parent, ent) < 0) {
kfree(ent);
parent->nlink--;
ent = NULL;
}
}
return ent;
}对于目录来说proc_dir_operations都是空实现
static const struct file_operations proc_dir_operations = {
.llseek = generic_file_llseek,
.read = generic_read_dir,
.iterate_shared = proc_readdir,
}; proc_dir_inode_operations会在open的时候赋给inode,后续会重点讲解函数proc_lookup
static const struct inode_operations proc_dir_inode_operations = {
.lookup = proc_lookup,
.getattr = proc_getattr,
.setattr = proc_notify_change,
};文件创建
下面是一个linux-4.12.3/fs/proc/ version.c中的实现:
static const struct file_operations version_proc_fops = {
.open = version_proc_open,
.read = seq_read,
.llseek = seq_lseek,
.release = single_release,
};
static int __init proc_version_init(void)
{
proc_create("version", 0, NULL, &version_proc_fops);
return 0;
}上面函数最终会调用到proc_create_data,传递下来的参数&version_proc_fops对应到下面的proc_fops
struct proc_dir_entry *proc_create_data(const char *name, umode_t mode,
struct proc_dir_entry *parent,
const struct file_operations *proc_fops,
void *data)
{
struct proc_dir_entry *pde;
if ((mode & S_IFMT) == 0)
mode |= S_IFREG; //表示创建的是普通文件,
……
pde = __proc_create(&parent, name, mode, 1); //分配文件对应的proc_dir_entry并初始化
if (!pde)
goto out;
pde->proc_fops = proc_fops; //也就是version_proc_fops,文件打开的时候会赋给inode
pde->data = data;
pde->proc_iops = &proc_file_inode_operations; //对于普通文件来说很多接口都没有实现
if (proc_register(parent, pde) < 0) //建立文件在proc中的层次关系
goto out_free;
return pde;
……3.2 文件打开
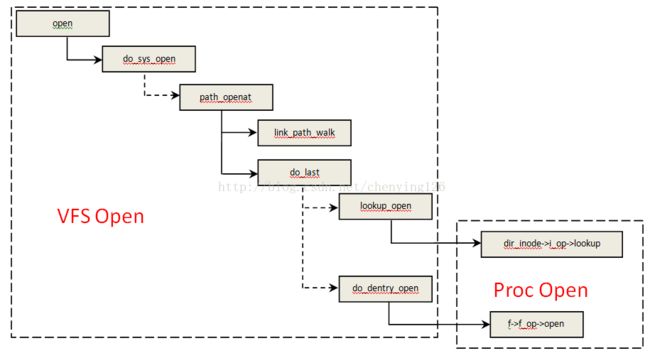
dir_inode->i_op->lookup :对应函数proc_lookup,用于查找目录下面的文件。
f->f_op->open: 这里对应函数proc_reg_open接着调用函数pde->proc_fops->open前面例子中对应到函数 version_proc_open。
文件查找
static const struct inode_operations proc_dir_inode_operations = {
.lookup = proc_lookup,
.getattr = proc_getattr,
.setattr = proc_notify_change,
};

pde_subdir_find:在父目录的dir->subdir.rb_node中查找看文件的proc_dir_entry是否存在;
proc_get_inode:创建proc_inode,其中内嵌vfs inode;
d_add:连接inode和dentry并将dentry添加到缓存;
struct inode *proc_get_inode(struct super_block *sb, struct proc_dir_entry *de)
{
struct inode *inode = new_inode_pseudo(sb);
if (inode) {
inode->i_ino = de->low_ino;
inode->i_mtime = inode->i_atime = inode->i_ctime = current_time(inode);
PROC_I(inode)->pde = de; //关联proc_inode和proc_dir_entry
……
if (de->mode) {
inode->i_mode = de->mode;
inode->i_uid = de->uid;
inode->i_gid = de->gid;
}
if (de->size)
inode->i_size = de->size;
inode->i_op = de->proc_iops;//如果是目录这里就是proc_dir_inode_operations
if (de->proc_fops) {
if (S_ISREG(inode->i_mode)) {
inode->i_fop = &proc_reg_file_ops; // 如果是普通文件
} else {
inode->i_fop = de->proc_fops; //如果是目录,
}
}
} else
pde_put(de);
return inode;
}文件打开
文件的file->f_op来源于inode->i_fop, 对应到proc中就是proc_reg_file_ops:
static const struct file_operations proc_reg_file_ops = {
.llseek = proc_reg_llseek,
.read = proc_reg_read,
.write = proc_reg_write,
.poll = proc_reg_poll,
.unlocked_ioctl = proc_reg_unlocked_ioctl,
.mmap = proc_reg_mmap,
.get_unmapped_area = proc_reg_get_unmapped_area,
.open = proc_reg_open,
.release = proc_reg_release,
};proc_reg_open会调用到pde->proc_fops->open,这里以version.c中的例子来讲解,这里的proc_fops就是version_proc_fops:
static const struct file_operations version_proc_fops = {
.open = version_proc_open,
.read = seq_read,
.llseek = seq_lseek,
.release = single_release,
};
static int version_proc_open(struct inode *inode, struct file *file)
{
return single_open(file, version_proc_show, NULL);
}
int single_open(struct file *file, int (*show)(struct seq_file *, void *),
void *data)
{
struct seq_operations *op = kmalloc(sizeof(*op), GFP_KERNEL);
int res = -ENOMEM;
if (op) {
op->start = single_start;
op->next = single_next;
op->stop = single_stop;
op->show = show; //也就是前面提到的version_proc_show
res = seq_open(file, op);
……
return res;
}
int seq_open(struct file *file, const struct seq_operations *op)
{
struct seq_file *p;
p = kzalloc(sizeof(*p), GFP_KERNEL);
file->private_data = p; //与vfs中的file连接
p->op = op; //设置顺序文件系统的seq_operations
p->file = file;
file->f_version = 0;
file->f_mode &= ~FMODE_PWRITE;
return 0;
}3.3文件读取
函数proc_reg_read是vfs read进入proc的入口。
static ssize_t proc_reg_read(struct file *file, char __user *buf, size_t count, loff_t *ppos)
{
ssize_t (*read)(struct file *, char __user *, size_t, loff_t *);
struct proc_dir_entry *pde = PDE(file_inode(file));
ssize_t rv = -EIO;
if (use_pde(pde)) {
read = pde->proc_fops->read;
if (read)
rv = read(file, buf, count, ppos);
unuse_pde(pde);
}
return rv;
}pde->proc_fops->read在前面的例子中对应函数seq_read,其具体实现如下:
ssize_t seq_read(struct file *file, char __user *buf, size_t size, loff_t *ppos)
{
struct seq_file *m = file->private_data;
size_t copied = 0;
loff_t pos;
size_t n;
void *p;
int err = 0;
if (!m->buf) {//因为这是一个通用函数,它并不知道会读取多少数据所以这里暂且分配一页数据
m->buf = seq_buf_alloc(m->size = PAGE_SIZE);
if (!m->buf)
goto Enomem;
}
/* if not empty - flush it first */
if (m->count) {//如果buffer中有数据先将数据拷贝到用户空间
n = min(m->count, size);
err = copy_to_user(buf, m->buf + m->from, n);
if (err)
goto Efault;
m->count -= n;
m->from += n;
size -= n;
buf += n;
copied += n;
if (!m->count) {
m->from = 0;
m->index++;
}
if (!size)
goto Done;
}
/* we need at least one record in buffer */
pos = m->index;
p = m->op->start(m, &pos);
while (1) {//测试先前分配的buffer够不够容纳将要读取的数据,如果不够就释放重新分配更大内存
err = PTR_ERR(p);
if (!p || IS_ERR(p))
break;
err = m->op->show(m, p); //尝试将数据拷贝到buffer中
if (err < 0)
break;
if (unlikely(err))
m->count = 0;
if (unlikely(!m->count)) {
p = m->op->next(m, p, &pos);
m->index = pos;
continue;
}
if (m->count < m->size) //如果m->count 等于 m->size就说明buffer满了,buffer不够用
goto Fill;
m->op->stop(m, p);
kvfree(m->buf);//释放掉之前不够用的buffer
m->count = 0;
m->buf = seq_buf_alloc(m->size <<= 1);//分配更大内存
if (!m->buf)
goto Enomem;
m->version = 0;
pos = m->index;
p = m->op->start(m, &pos);
}
m->op->stop(m, p);
m->count = 0;
goto Done;
Fill:
/* they want more? let's try to get some more */
while (m->count < size) {
size_t offs = m->count;
loff_t next = pos;
p = m->op->next(m, p, &next);
if (!p || IS_ERR(p)) {
err = PTR_ERR(p);
break;
}
err = m->op->show(m, p);//将剩余的数据拷贝到buffer
if (seq_has_overflowed(m) || err) {
m->count = offs;
if (likely(err <= 0))
break;
}
pos = next;
}
m->op->stop(m, p);
n = min(m->count, size);
err = copy_to_user(buf, m->buf, n);//将buffer中的数据拷贝到用户空间内存
if (err)
goto Efault;
copied += n;
m->count -= n;
if (m->count)
m->from = n;
else
pos++;
m->index = pos;
Done:
if (!copied)
copied = err;
else {
*ppos += copied;
m->read_pos += copied;
}
file->f_version = m->version;
mutex_unlock(&m->lock);
return copied;
}