【hadoop 2.6】hadoop2.6伪分布模式环境的搭建测试使用
首先下载安装,这个就不说了,去apache官网下载安装,貌似186M,很大
解压后,我们看下目录结构如下:
[root@com23 hadoop-2.6.0]# ll
total 64
drwxr-xr-x 2 20000 20000 4096 Nov 14 05:20 bin
drwxr-xr-x 3 20000 20000 4096 Nov 14 05:20 etc
drwxr-xr-x 2 20000 20000 4096 Nov 14 05:20 include
drwxr-xr-x 2 root root 4096 Jan 14 14:52 input
drwxr-xr-x 3 20000 20000 4096 Nov 14 05:20 lib
drwxr-xr-x 2 20000 20000 4096 Nov 14 05:20 libexec
-rw-r--r-- 1 20000 20000 15429 Nov 14 05:20 LICENSE.txt
drwxr-xr-x 2 root root 4096 Jan 14 15:23 logs
-rw-r--r-- 1 20000 20000 101 Nov 14 05:20 NOTICE.txt
drwxr-xr-x 2 root root 4096 Jan 14 14:53 output
-rw-r--r-- 1 20000 20000 1366 Nov 14 05:20 README.txt
drwxr-xr-x 2 20000 20000 4096 Nov 14 05:20 sbin
drwxr-xr-x 4 20000 20000 4096 Nov 14 05:20 share解压好了之后,首先来一个standalone跑一个例子:
The following example copies the unpacked conf directory to use as input and then finds and displays every match of the given regular expression. Output is written to the given output directory.
$ mkdir input $ cp etc/hadoop/*.xml input $ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep input output 'dfs[a-z.]+' $ cat output/*下面来看看伪分布模式
涉及到两个配置文件
hadoop-2.6.0/etc/hadoop
core-ste.xml
fs.defaultFS
hdfs://localhost:9000
hdfs-site.xml
dfs.replication
1
在hadoop-env.sh和yarn-env.sh(如果用到的话,不过要配一起配了)
这里添加一个yarn的配置,mapreduce采用yarn框架的
mapred-site.xml
mapreduce.framework.name
yarn
yarn.nodemanager.aux-services
mapreduce_shuffle
下面建立ssh localhost免密码登录
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys都搞定了,开始执行了:
1、文件系统格式化
bin/hdfs namenode -format2、启动namenode和datanode
sbin/start-dfs.sh这一步结束,我们就可以打开hadoop的监控页面看看各个模块的情况了:http://localhost:50070
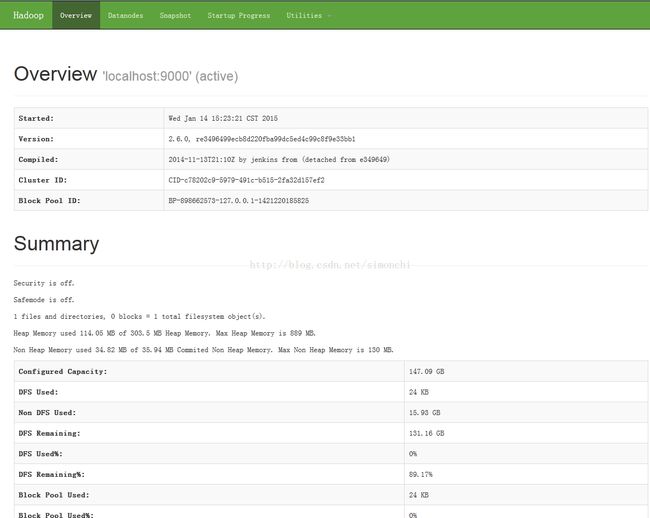
感觉2.6很酷炫啊!!
下面建立文件系统
bin/hdfs dfs -mkdir /user bin/hdfs dfs -mkdir /user/chiwei
执行完了,我们去到页面上观察下已经出现了我们刚刚创建的文件系统了
sh bin/hdfs dfs -put input /user/chiwei
将input文件夹下的内容放到刚刚创建的文件系统里

sh bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep /user/chiwei/input output 'dfs[a-z.]+'
通过以上命令使用example去分析一下刚刚的文件内容

已经产生输出了
查看内容到hadoop的文件系统去查看,而不是linux的文件系统
[root@com23 hadoop-2.6.0]# sh bin/hdfs dfs -cat /user/root/output/*
最后就是关闭文件系统,datanode,namenode,secondary namenode
[root@com23 hadoop-2.6.0]# sh sbin/stop-dfs.sh
15/01/14 15:56:44 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Stopping namenodes on [localhost]
localhost: stopping namenode
localhost: stopping datanode
Stopping secondary namenodes [0.0.0.0]
0.0.0.0: stopping secondarynamenode
15/01/14 15:57:07 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[root@com23 hadoop-2.6.0]#