shufflenetv1 ,shufflenetv2,mobilenetv1,mobilenetv2
首先,就目前而言,shufflenetv2的效果是最好的
这个四个网络都是对depthwiseconv网络的运用,深度可分离卷积相对于传统卷积的优点在于其计算量由巨大幅度的降低。
但是现今的深度学习框架对于深度可分离卷积的支持还是有好有坏的,有些框架,比如:darknet中就没有深度可分离卷积的实现,GitHub上有人分享了其实现方法,对于速度的提升确实很明显,但有很大的优化空间。
推荐:
MXNET,PYTORCH,TENSORFLOW
深度学习是个赢者通吃的局,不过想要步步领先也是很难的,
咱们还是按照时间顺序来
首先1.第一个是MobilenetV1,
MobilenetV1
这部分内容参考了https://blog.csdn.net/wfei101/article/details/78310226
还盗了几张图,侵权的话,立删
MobileNets模型基于深度可分解的卷积,它可以将标准卷积分解成一个深度卷积和一个点卷积(1 × 1卷积核)。深度卷积将每个卷积核应用到每一个通道,而1 × 1卷积用来组合通道卷积的输出。后文证明,这种分解可以有效减少计算量,降低模型大小
下图就是depthwiseCONV的图解

下面是深度可分离卷积的动态演示

一个卷积对应一个FM的channel,这样就少了通道之间的额信息交互,但是却大大降低了浮点计算量
本人认为深度可分离卷积是group conv的一种极致情况,
这样就不能不提到Xception 网络结构了
(论文:Xception: Deep Learning with Depthwise Separable Convolutions
论文链接:https://arxiv.org/abs/1610.02357)
在Xception的论文中提到了一种极致的group情况

这种情况是3*3卷积的filters == FM 的channel,这样一个卷积核对应一层channel,没有channel之间的信息交流,GPU或者CPU,同时并行channel个卷积操作(当然要考虑CPU或者GPU的并行效率)最后将所有的channel concate起来,完成3*3卷积提取特征的任务,最后再使用1*1卷积进行通道之间的信息交流。
那么深度可分离卷积和普通的卷积层之间的浮点计算量的比值是多少呢?
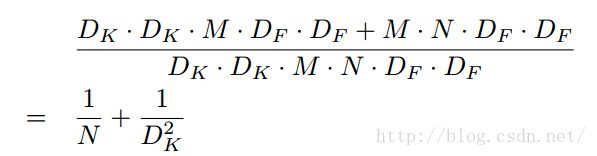
注意:默认输入的Feature map的通道数是M个
分子是一个3*3的M个filters的深度可分离卷积和1*1的N个filters的普通卷积的计算量
分母是一个普通的3*3 N个filters的卷积
MobileNets使用了大量的3 × 3的卷积核,同时准确率下降的很少,相比其他的方法确有优势。
mobilenet网络结构图
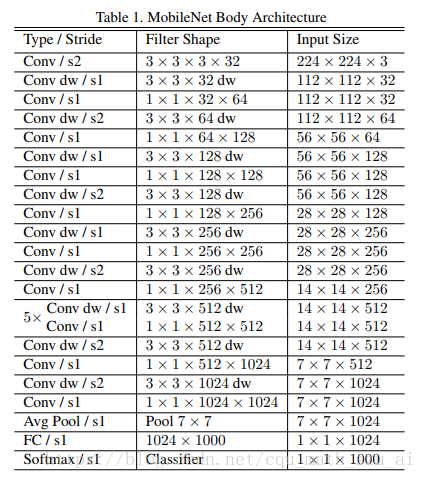
直桶型网络结构,估计有人会说这是逆潮流啊,因为在Resnet出世之后,就很少有直桶型的网络结构了,据本人印象之内,就有darknet19还是直桶型结构,但是当初yolov2作者设计这个网络时主要的考虑因素是计算速度,因为DarkNet网络框架对于非直筒型网络来说并不是很友好,其多线程并行部分写的有点差.
个人认为VGG16是直桶型结构的经典之作,而直桶型网络结构对于那些多进程优化的不好的深度学习框架还是很友好的,这里吐槽一下darknet,这么好的框架,作者继续深度优化一下啊
作者在社区上说了,mobilenetv1很早之前就搞出来了,后来看几年这个方向都没动静,于是就挂在arxiv上了(话说arxiv的论文都不审核的吗?直接挂上去就可以了?)

上图左边是一般的卷积层,右侧是Depthwise conv,没什么可说的。就是这个BN层的位置有点玄乎,有些网络是在卷积之前就进行BN,有些实在卷积之后,BN就是个神器,在好多地方多可以用到,用到了之后效果还不错。
最新出来一种SELU激活函数,是集BN和activattion为一体的函数,这篇论文102页,喜欢啃难题的同学可以去啃一啃
https://arxiv.org/pdf/1706.02515.pdf
那这个函数到底有没有效果呢?
那得看具体怎么使用,使用的不好,连relu的效果都不及
在一般常规的图像算法上
BN+selu的效果比BN+relu
当然我只实验了几次,没有全部的试验一遍,在有些结构网络上面可能会出现一些偏差也是不一定的,大家在使用的使用请注意

这是Mobile netv1中的参数占比和计算量占比,可见1*1卷积占了绝大多数的计算量(1*1卷积主要是过滤和通道信息交互,所以这肯定是一个优化的方向)

这段话说的是,每个网络层的通道数可以按比例调节,当然通道数多,效果更好,通道数少,效果会差一点
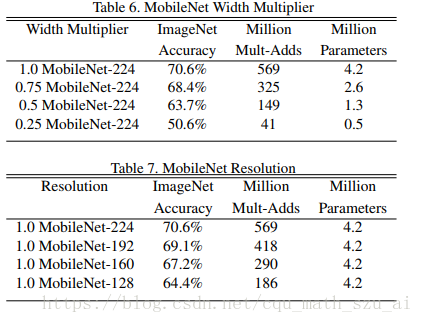
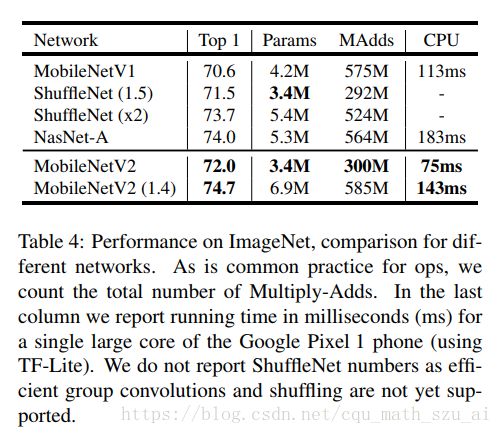
上图的准确率都是top1准确率

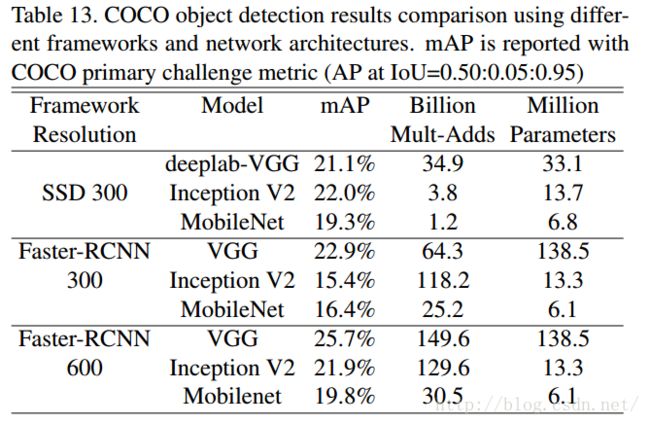
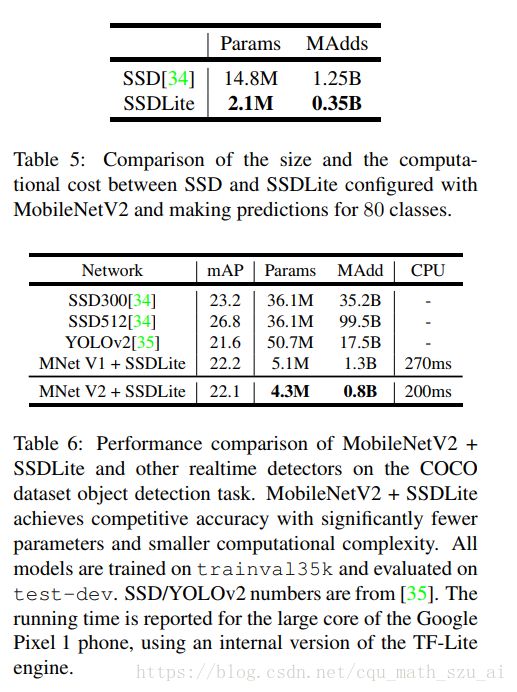
这里的实验主要是将MobileNets作为目标检测网络Faster R-CNN和SSD的基底(base network),和其他模型在COCO数据集上进行了对比。(为什么不在VOC PASCAL上进行对比,应该更直观吧?也不给一个帧率,不知道速度怎么样)
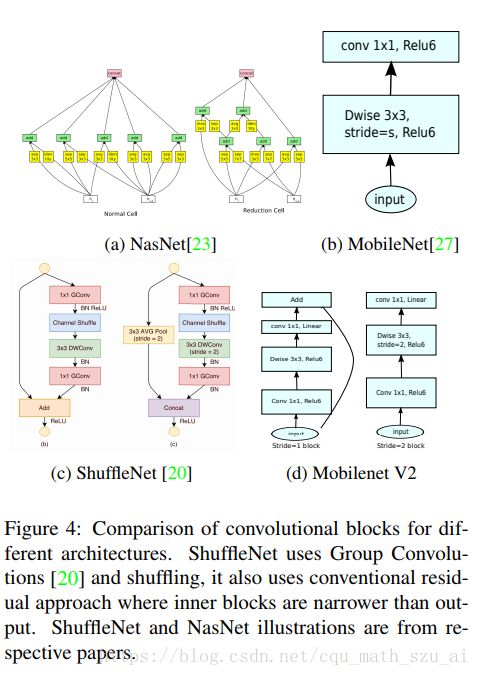
shufflenetv1
ShuffleNet 网络结构同样沿袭了稀疏连接的设计理念。作者通过分析 Xception 和 ResNeXt 模型,发现这两种结构通过卷积核拆分虽然计算复杂度均较原始卷积运算有所下降,然而拆分所产生的逐点卷积计算量却相当可观,成为了新的瓶颈。例如对于 ResNeXt 模型逐点卷积占据了 93.4% 的运算复杂度。可见,为了进一步提升模型的速度,就必须寻求更为高效的结构来取代逐点卷积。
受 ResNeXt 的启发,作者提出使用分组逐点卷积(group pointwise convolution)来代替原来的结构。通过将卷积运算的输入限制在每个组内,模型的计算量取得了显著的下降。然而这样做也带来了明显的问题:在多层逐点卷积堆叠时,模型的信息流被分割在各个组内,组与组之间没有信息交换(如图 1(a) 所示)。这将可能影响到模型的表示能力和识别精度。
如图

这里我们可以看到了
Mobilenet是使用1*1卷积网络去进行通道之间的信息交流,
而shufflenetv1采用了一种另外的方式: channel shuffle,把每一个通道打乱重排,再加上1*1卷积,
基于分组逐点卷积和通道重排操作,作者提出了全新的 ShuffleNet 结构单元,如图 2 所示。该结构继承了“残差网络”(ResNet)[3]的设计思想,在此基础上做出了一系列改进来提升模型的效率:首先,使用逐通道卷积替换原有的 3x3 卷积,降低卷积操作抽取空间特征的复杂度,如图 2(a)所示;接着,将原先结构中前后两个 1x1 逐点卷积分组化,并在两层之间添加通道重排操作,进一步降低卷积运算的跨通道计算量。最终的结构单元如图 2(b) 所示。类似地,文中还提出了另一种结构单元(图2(c)),专门用于特征图的降采样。
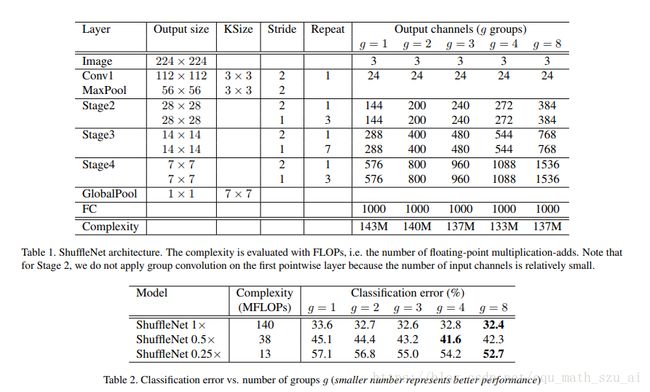
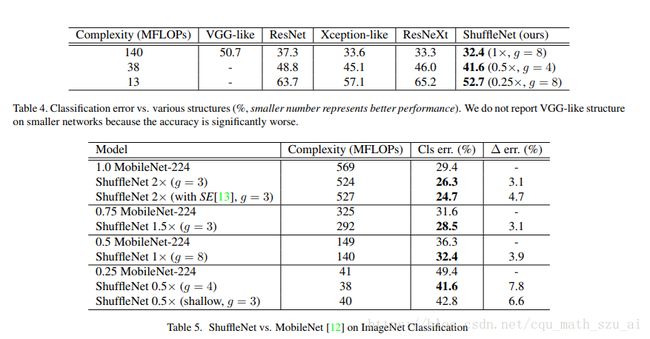
借助 ShuffleNet 结构单元,作者构建了完整的 ShuffeNet 网络模型。它主要由 16 个 ShuffleNet 结构单元堆叠而成,分属网络的三个阶段,每经过一个阶段特征图的空间尺寸减半,而通道数翻倍。整个模型的总计算量约为 140 MFLOPs。通过简单地将各层通道数进行放缩,可以得到其他任意复杂度的模型。
当卷积运算的分组数越多,模型的计算量就越低;这就意味着当总计算量一定时,较大的分组数可以允许较多的通道数,

说实在的,我个人是不喜欢POOL操作的,无论是maxpool还是avg-pool,现在还有非线性平滑pool,
因为在源码实现上,都是需要数层的for循环,大家写过代码的都知道,for循环最好时间,就算是写C,那耗时也长
所以,我个人倾向于用dwconv+1*1conv去替换掉pool,这样的替换,在CPU上面跑的时间长了,但是在GPU上面跑的速度会增加不少
别忘了add也是一种element-wise操作
这种操作最耗时间,我一直在想着怎么去取代shortcut(res)的操作,反正以后GPU是主流,现在手机上面也有了GPU,觉得以后GPU会成主流,手机现在要求打游戏帧率越高,那么GPU肯定会越来越强,
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。这个问题还未解决?????我得试试
接下来就是我最喜欢的两个网络了,这俩网络在我心中的地位和ALexnet与Resnet的地位是一样,都是充满了艺术、美、、、
mobilenetv2
mobilenetv2有一个思想:既然3*3卷积主要用提取特征,那么我将3*3卷积的通道数尽可能提高,效果是不是会更好?
这样Mobilenetv2就采用一种类是与柳叶的样子的网络,中间3*3卷积channel多,两边少
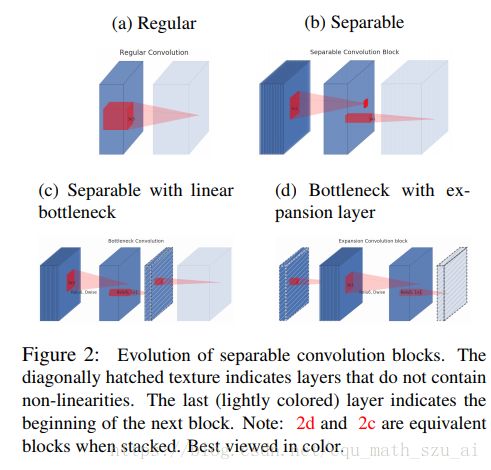
这个和以往的有所不同,以往的算法是先压缩,然后用3*3卷积处理,因为3*3卷积所需要的计算量太多,但是现在是3*3卷积计算量少了,所以它先膨胀,把用1*1卷积通道数拉起来,然后再用3*3的DWCONV去处理

至于膨胀多大,就由一个膨胀系数t来控制

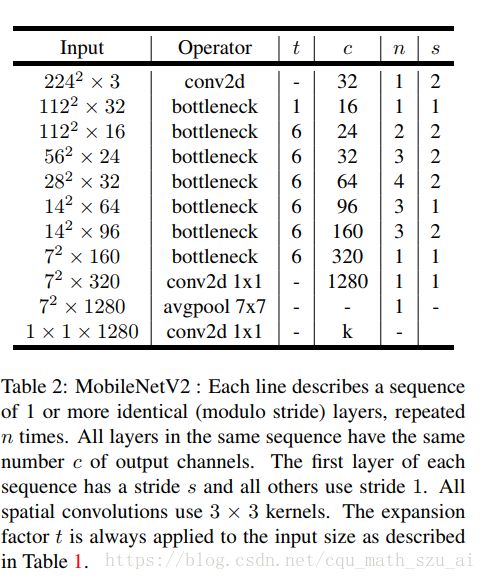
这样设计有几个好处,3*3网络可以有足够的通道数去提特征,而使用类似柳叶型的结构的作用有一个好处,
我觉得很重要,大家想想,在resnet中,两边大中间小,那么用identity-skip的时候会怎样,element-wise add计算量是不是大大增加了,速度铁定变慢,那么在Mobilenetv2 中呢,使用这种结构,两边尽量的收缩,中间尽量放大,这样的就尽可能的缩小的element-wise add的计算量,(其实还有提出来使用element-wise product的,效果比add好一点,若是大家想的话,可以试试)
可能压缩都是精华。所以每次膨胀之后,再压缩,都会压出来一点点精华,
最后的1*1*1280的conv也不容忽视哦,一般的是在avgpool之后使用一个全连接层。直接输出结果,这个简单的1*1conv结构,省去了不少计算量哦
这1.4,0.75,0.5等等都是一个系数,主要是在res相加部分的channel数目上,
shufflenet-v2
不愧是国内顶尖的图像算法研究机构,这篇论文的质量,个人感觉有点高。
一些新提出来的nas-net,mnasnet,等等都是增强学习再加上500块GPU硬怼出来的,不过,效果还是很好
先膜拜一下大厂,500块GPU啊

ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
由博客https://blog.csdn.net/u011995719/article/details/81409245上面得到的论文链接
https://pan.baidu.com/s/1so7aD3hLKO-0PB8h4HWliw
论文直接指出:FLOPS数量并不能直接线性的衡量计算速度,很多时候,计算速度还和你的平台框架,有些平台的多线程优化的就很不错,当然速度也会有提升。速度还和硬件设备有关,
论文里面给了一张图

我们一般在计算计算量的时候,只会去计算浮点计算量,也就是图中卷积操作所需要的时间,
根据上图分析可以得出,其实,CONV虽然说是占用了大量的时间,但是并不是全部的时间,对于MobilenetV2,shufflenet v1来说
很大一部分时间是在element-wise 操作上面,
这里简要说一下什么是element-wise的操作
1. Batch normalization ,归一化操作,每次进行归一化操作的时候会将所有的element全部计算一遍,而且这部分是很耗时间啊的,这部分是在CPU上面进行的,可以在GPU上面计算吗?至少我现在是没有找到可以在GPU加速的BN,GPU只是对于矩阵操作加速很大,一般情况下,加速其实不明显的,
2. activate function,激活函数,这显而易见,所有的元素都需要过一遍
3. identity-skip 就是res中的shortcut,我喜欢用shortcut称呼,这个是element-wise add 操作
4. 现在有的一个element-wise product操作
5. 所有的pooling都是,我在前面有讲过,pooling这玩意儿应该有很大的提升空间,其实我觉得avgpool操作在某种程度上是可以进行卷积加速的,就是卷积核的参数都为1,而且卷积和参数固定不变,但是至今没见到过有人这样写这个模块
可能还有,但是现在想不起来了,
另外一些占时间就是IO了,而且根据个人经验,网络层数越大,在IO上面占用的时间越多
由shufflenetv2得到的启发:
两个原则:
1. 衡量模型运行速度,应采用如运行时间(speed\runtime)这样的指标;
2. 应在具体的运行平台上进行评估、衡量。
四个指导方针:
1. 卷积核数量尽量与输入通道数相同(即输入通道数等于输出通道数);
上面的字我加粗,说明很重要,为什么这么说?作者给出了一个实验证明,

这个实验说明,在input_channels equals output_channels时,计算的效率是最高的
文章提出了一个MAC的概念(我以前没见过,如果这个MAC概念以前出现过,请通知我改正,谢谢)
这个MAC是什么呢?是 the memory access cost,或者是the number of memory access operations
MAC=hw(c1+c2)+c1c2
而我们的一般卷积的浮点计算怎么算的:
B=hwc1c2
这样就有
MAC >= 2*sqrt(h*w*B)+B/(hw)
当c1=c2的时候,MAC取下确界值
2. 谨慎使用group convolutions,注意group convolutions的效率;
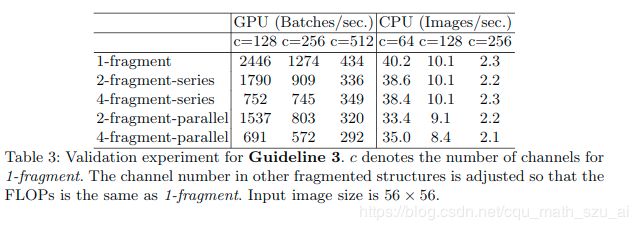
3. 降低网络碎片化程度;
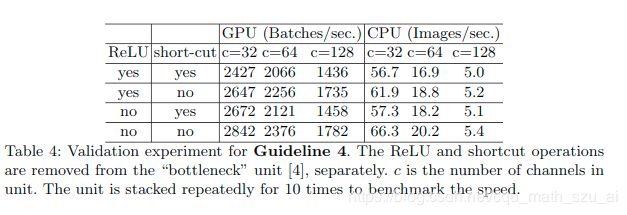
4. 减少元素级运算。
个人见解:
group conv的计算量看起来是比较低,但是实际算法跑起来,慢。。。。。。。。。。。。。。。。。。。。。。。!!!!!!!
因为group conv卷积在实现的时候就是将Feature Map进行分片,
GPU对矩阵的操作支持的很好,但是这样group conv就会抹除掉这种优势