Keras学习之3:回归问题(boston_housing数据为例)
本实验使用boston_housing数据集对房价数据进行回归分析,数据来自1970年代,波斯顿周边地区的房价,是用于机器学习的经典数据集。该数据集很小,共计506条数据,分为404个训练样本和102个测试样本,因此需要采用K-Fold,这里取K=4。每条数据包含13个特征,分别为:
- CRIM - per capita crime rate by town
- ZN - proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS - proportion of non-retail business acres per town.
- CHAS - Charles River dummy variable (1 if tract bounds river; 0 otherwise)
- NOX - nitric oxides concentration (parts per 10 million)
- RM - average number of rooms per dwelling
- AGE - proportion of owner-occupied units built prior to 1940
- DIS - weighted distances to five Boston employment centres
- RAD - index of accessibility to radial highways
- TAX - full-value property-tax rate per $10,000
- PTRATIO - pupil-teacher ratio by town
- B - 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT - % lower status of the population
由于每个维度的特征取值范围不同,因此需要先做数据的Normalization。具体代码实现如下:
from keras.datasets import boston_housing
from keras import models
from keras import layers
import numpy as np
import matplotlib.pyplot as plt
#train_data.shape:(404, 13),test_data.shape:(102, 13),
#train_targets.shape:(404,),test_targets.shape:(102,)
#the data compromises 13 features
#the targets are the median values of owner-occupied homes,in thousands of dollars
(train_data,train_targets),(test_data,test_targets)=boston_housing.load_data()
#feature-wise normalization
mean = train_data.mean(axis=0)
train_data -=mean
std = train_data.std(axis=0)
train_data/=std
#never use any quantity computed on the test data
test_data-=mean
test_data/=std
#build the model
#because we need to build a model several times,we use function to cons
def build_model():
model = models.Sequential()
model.add(layers.Dense(64,activation='relu',input_shape=(train_data.shape[1],)))
model.add(layers.Dense(64,activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop',loss='mse',metrics=['mae'])
return model
#K-fold validation
k = 4
num_val_samples = len(train_data) // k
num_epochs = 500
all_scores = []
all_mae_histories = []
#K-fold validation and logs
k = 4
num_val_samples = len(train_data) // k
num_epochs = 500
all_scores = []
all_mae_histories = []
for i in range(k):
print('正在处理fold #',i)
#preparing the validation data:data from partition #k
val_data = train_data[i*num_val_samples:(i+1)*num_val_samples]
val_targets = train_targets[i*num_val_samples:(i+1)*num_val_samples]
#preparing the training data:data from all other partitions
partial_train_data = np.concatenate(
[train_data[:i*num_val_samples],
train_data[((i+1)*num_val_samples):]],
axis=0
)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[((i + 1) * num_val_samples):]],
axis=0
)
#build the model
model = build_model()
#train the model,silent mode
history = model.fit(partial_train_data,partial_train_targets,validation_data=(val_data,val_targets),epochs=num_epochs,batch_size=1,verbose=0)
#evaluate the model in the validation data
mae_history = history.history['val_mean_absolute_error']
val_mse,val_mae = model.evaluate(val_data,val_targets,verbose=0)
all_scores.append(val_mae)
all_mae_histories.append(mae_history)
print("Complete!")
average_mae_history = [
np.mean([x[i] for x in all_mae_histories]) for i in range(num_epochs)]
mean_score = np.mean(all_scores)
print("mean_score:",mean_score)绘制出validation score,图片不是很有辨识度:
#plotting validation scores
plt.plot(range(1,len(average_mae_history)+1),average_mae_history)
plt.xlabel('Epochs')
plt.ylabel('Validation MAE')
plt.show()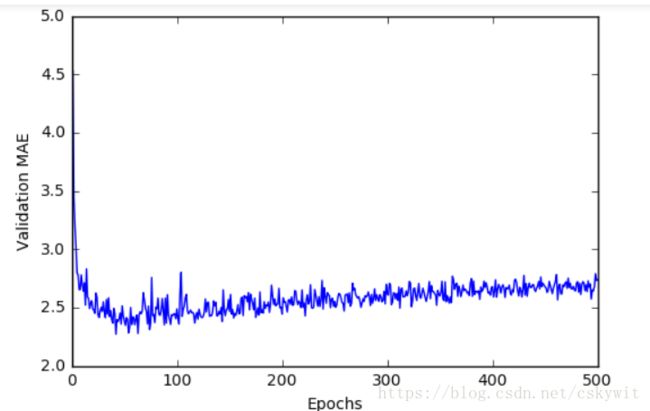
采用移动平均平滑曲线重新绘图:
#plotting validation scores-excluding the first 10 data points
#using moving average to smooth the curve
def smooth_curve(points,factor=0.9):
smoothed_points = []
for point in points:
if smoothed_points:
previous = smoothed_points[-1]
smoothed_points.append(previous*factor+point*(1-factor))
else:
smoothed_points.append(point)
return smoothed_points
#remove head 10 points
smooth_mae_history = smooth_curve(average_mae_history[10:])
plt.plot(range(1,len(smooth_mae_history)+1),smooth_mae_history)
plt.xlabel('Epochs')
plt.ylabel(('Validation MAE'))
plt.show()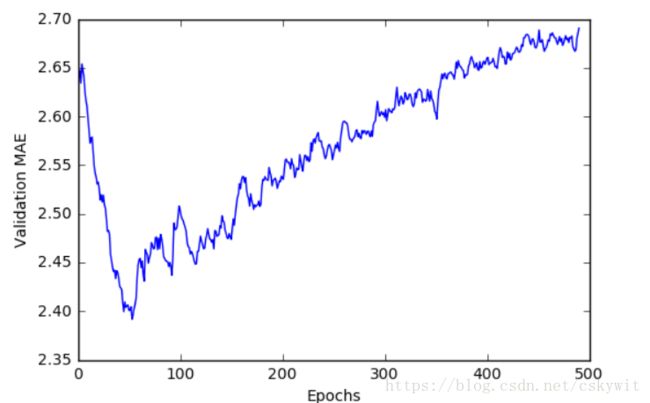
可以看出在第80个Epochs是validation score最好,后面开始overfitting,重新构建模型:
from the plot above ,the Validation MAE reaches the lowest in the 80th epochs
model =build_model()
model.fit(train_data,train_targets,epochs=80,batch_size=16,verbose=0)
test_mse_score,test_mae_score = model.evaluate(test_data,test_targets)
print("final test_mae_score:",test_mae_score)102/102 [==============================] - 0s 853us/step
final test_mae_score: 2.667761251038196
实验小结:
1、回归和分类使用不同的损失函数,在回归中通常使用Mean Square Error(MSE)
2、评价标准通常使用Mean Absolute Error,分类中通常使用accuracy
3、当样本数据量小的时候,通常使用K-Fold方法使训练的模型更可靠