web高性能使用openresty的一些高级用法、redis的常用法、简易防火墙、禁止终端
记录使用openresty在web中的高级使用技术
openresty内部处理流程说明
nginx中这三个阶段的执行顺序:access--》content--》body_filter;
access_by_lua_file:获取协议版本-->获取bodys数据-->协议解码-->设置body数据
content_by_lua_file:正常处理业务逻辑,零修改
body_filter_by_lua_file:判断协议版本-->协议编码
1、与其他location配合使用
内部调用:例如对数据库、内部公共函数的统一接口,可以把它们放到统一的location中,通常情况下,为了保护这些内部接口函数,都会把这些设置为internal。可以让内部接口相对独立,不受外界干扰。

如图 30行。interal设置为内部location,直接访问报404。
其中的函数介绍:
单个子请求:
ngx.location.capture("/sum",{args={a=10,b=33}})这个函数是lua内部来调用nginx的其他location函数,第二参数表示入参吧。多个子请求:
res,res2 = ngx.location.capture_multi('uri1','uri2',...)ngx.req.get_uri_args()函数为回去请求url的参数。
注意:

ngx.sleep(0.1) 休眠0.1毫秒
ngx.now() 获取服务器当前时间;
ngx.location.capture_multi({},{}) : 表示并行执行两个请求,当两个请求没有依赖关系,这种方式可以极大的提高查询效率。可以被广泛应用于广告系统,高并发前端展示(并行无依赖界面,降级开关等) 如上图 58行。
2、nginx内部跳转

ngx.exec() 纯粹是内部跳转并且没有引入任何额外的HTTP信号。
使用内部重定向,发现浏览器uri不会发生变化,但会有一样的输出结果。
alias 与root 的区别:
因为root属性指定的值是要加入到最终路径的,所以访问的位置变成了/var/lib/www/website/。而我不想把访问的URI加入到路径中。所以就需要使用alias属性,其会抛弃URI,直接访问alias指定的位置, 所以最终路径变成/var/lib/www/
3、外部重定向
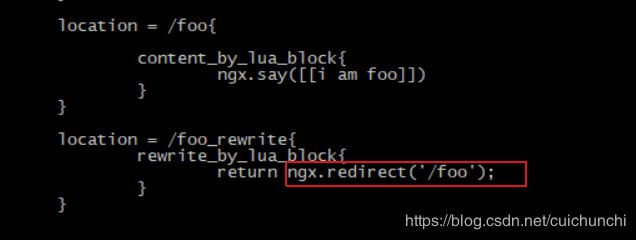
ngx.redirect():当请求http://10.23.148.149:9002/foo_rewrite会直接重定向到http://10.23.148.149:9002/foo,外部重定向是可以跨域名的。浏览器URL被改写了,也就是重定向的功能。返回结果同B。
4、获取url的参数
ngx.req.get_uri_args、ngx.req.get_post_args一个获取get请求的参数,一个是post请i去的参数
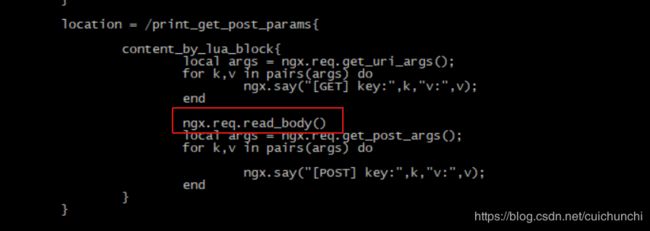

注意:在解析body post的参数之前, 一定要先读取body,不然会报错。
ngx.req.read_body():读取body函数
5、传递请求uri的参数
当获取到了参数,自然是需要这些参数来完成业务逻辑。URI内容传递过程中是需要调用ngx.encode_args进行规则转义。
也可以不使用ngx.encode_args,但是写法上比较丑。
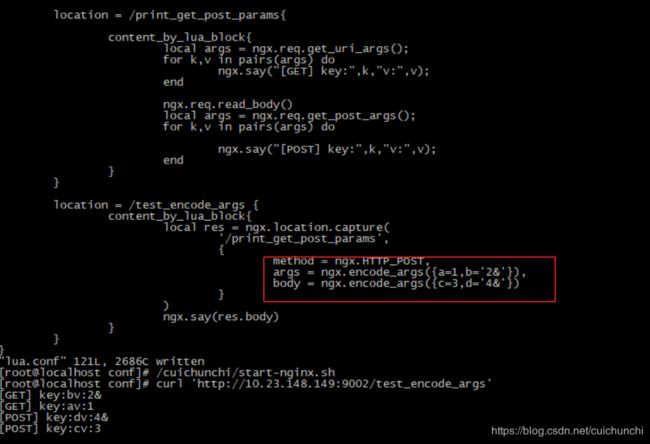
注意:对于使用ngx.location.capture,args参数是可以接受字符串或者lua表的。
6、获取请求body
在nnginx的典型应用场景中,几乎都是读取HTTP请求头信息,例如负载均衡、反向代理等,对于API或者web 服务,获取body信息在某些场景就是有必要的了。
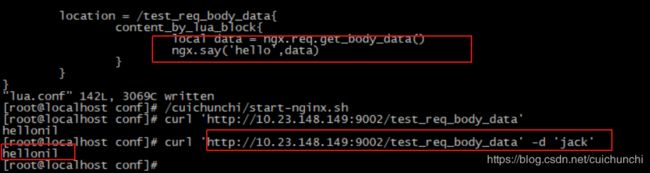
未获取到jack body 信息,注意:需要添加lua指令 lua_need_request_body on;默认读取body信息。
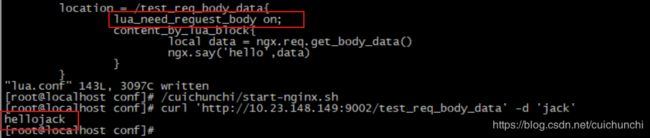
添加后即可获取到body信息。
大多数场景可以使用 ngx.req.read_body() 函数来获取body 的post参数即可。不推荐使用lua_need_request_body指令。
7、简易防火墙、黑白名单的配置



其中的 ngx.var.remote_addr 表示获取nginx的内置绑定变量。
8、防止SQL注入问题。可以使用resty.mysql的lua脚本库来建立与mysql的链接
9、使用resty.http库资源,函数完成了连接池、http请求。
9、redis的使用以及redis连接池

这是一个标准的redis接口调用,如果代码调用频率不高,没有任何问题,如果重度依赖redis,且有大量的创建连接---数据操作--关闭连接,这就发现代码中很多的重复。
local function close_redis(red)
if not red then
return
end
local ok, err = red:close()
if not ok then
ngx.say("close redis error : ", err)
end
end
local redis = require("resty.redis")
--创建实例
local red = redis:new()
--设置超时(毫秒)
red:set_timeout(1000)
--建立连接
local ip = "127.0.0.1"
local port = 6660
local ok, err = red:connect(ip, port)
if not ok then
ngx.say("connect to redis error : ", err)
return close_redis(red)
end
--调用API进行处理
ok, err = red:set("msg", "hello world")
if not ok then
ngx.say("set msg error : ", err)
return close_redis(red)
end
--调用API获取数据
local resp, err = red:get("msg")
if not resp then
ngx.say("get msg error : ", err)
return close_redis(red)
end
--得到的数据为空处理
if resp == ngx.null then
resp = '' --比如默认值
end
ngx.say("msg : ", resp)
close_redis(red) 使用连接池来复用连接
建立TCP连接需要三次握手而释放TCP连接需要四次握手,而这些往返时延仅需要一次,以后应该复用TCP连接,此时就可以考虑使用连接池,即连接池可以复用连接。
我们只需要将之前的close_redis函数改造为如下即可:
local function close_redis(red)
if not red then
return
end
--释放连接(连接池实现)
local pool_max_idle_time = 10000 --毫秒
local pool_size = 100 --连接池大小
local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.say("set keepalive error : ", err)
end
end 即设置空闲连接超时时间防止连接一直占用不释放;设置连接池大小来复用连接。
此处假设调用red:set_keepalive(),连接池大小通过nginx.conf中http部分的如下指令定义:
#默认连接池大小,默认30
lua_socket_pool_size 30;
#默认超时时间,默认60s
lua_socket_keepalive_timeout 60s;
注意:
a、连接池是每Worker进程的,而不是每Server的;
b、当连接超过最大连接池大小时,会按照LRU算法回收空闲连接为新连接使用;
c、连接池中的空闲连接出现异常时会自动被移除;
d、连接池是通过ip和port标识的,即相同的ip和port会使用同一个连接池(即使是不同类型的客户端如Redis、Memcached);
e、连接池第一次set_keepalive时连接池大小就确定下了,不会再变更;
10、PipeLine压缩请求数量
当我们有连续多个命令需要发送给redis时,如果m每个命令都以一个数据包发送给redis,将会降低服务端的并发能力。因为每发送一个TCP报文,会存在网络延迟及操作系统的处理延迟。大部分情况下,网络延迟要远大于CPU的处理延迟,所以网络延迟会成功系统性能的瓶颈,使得并发上不去。pipeline的机制是将多个命令汇聚到一个请求中,可以极大的减少请求数量减少网络延时。在实际应用场景中,正确使用pipeline对性能的提升十分明显。

11、script压缩复杂请求
从pipeline中,我们知道对于多个简单的redis命令可以汇聚到一个请求中,提升服务端的并发能力。然后,在有些场景下,我们每次命令的输入需要引用上一个命令的结果作为入参,甚至还需要对第一个结果进行一些加工,再把加工结果当成第二个命令的输入。pipeline难以处理这样的场景。但是可以使用redis里面的script来压缩这些复杂的命令。
其核心思想是redism命令里嵌入lua脚本,来实现一些复杂操作。其脚本相关命令有:
eval、evalsha、script exists、 script flush、 script kill 、script load

这样就可以将两个get请求放到一个TCP请求中,做到减少TCP请求数据,减少网络延时。