语音信号预处理及特征参数提取
1. WAVE文件格式
在进行语音信号处理时,基本上会采用WAVE文件进行处理。WAVE文件格式有什么特点呢?为什么要使用WAVE文件呢?
1.1 资源互换文件格式——RIFF
在windows环境下,大部分的多媒体文件都依循着一些通用的结构来存放,这些结构称为“资源互换文件格式”(Resources Interchange File Format),简称RIFF。RIFF可以看作一种树状结构,其基本构成单位是块(chunk)。每个块由“辨别码”、“数据大小”及“数据”等构成。 RIFF文件的前4字节为其辨别码“RIFF"的ASCII字符码,紧跟其后的双字节数据则标示整个文件大小(单位为字节Byte)。由于表示文件长度或块长度的”数据大小“信息占用4Byte,所以,事实上一个WAVE文件或文件中块的长度为数据大小加8。
RIFF文件的前4字节为其辨别码“RIFF"的ASCII字符码,紧跟其后的双字节数据则标示整个文件大小(单位为字节Byte)。由于表示文件长度或块长度的”数据大小“信息占用4Byte,所以,事实上一个WAVE文件或文件中块的长度为数据大小加8。
1.2 WAVE文件格式
WAVE文件格式是windows中关于声音的一种标准格式,也是RIFF文件格式支持的一种格式,这种格式已成为Windows中的基本声音格式。整个WAVE文件可以分成两部分:前一部分为文件头,后一部分为数据块。根据其编码方式和采样数的不同,这两部分的大小有所不同。在WAVE文件中,所采用的编码方式有PCM(Pulse Code Modulation-脉冲编码调制)和ADPCM(Adaptive Differential Pulse Code Modulation-自适应差分脉冲编码调制)两种。
WAVE文件是非常简单的一种RIFF文件,它的格式类型为"WAVE"。RIFF块包含两个子块,这两个子块的ID分别是"fmt"和"data",其中"fmt"子块由结构PCMWAVEFORMAT所组成,其子块的大小就是sizeofof(PCMWAVEFORMAT),数据组成就是PCMWAVEFORMAT结构中的数据。
下面是一个语音的数据:
 下面是数据中每个字节的内容:
下面是数据中每个字节的内容:
2. 语音的预处理
在对语音信号进行分析和处理之前,必须对其进行预加重、分帧、加窗等预处理操作。这些操作的目的是消除因为人类发声器官本身和由于采集语音信号的设备所带来的混叠、高次谐波失真、高频等等因素,对语音信号质量的影响。尽可能保证后续语音处理得到的信号更均匀、平滑,为信号参数提取提供优质的参数,提高语音处理质量。
2.1 预加重
语音信号s(n)的平均功率谱受声门激励和口鼻辐射的影响,高频端大约在800Hz以上按6dB/oct (倍频程)衰减,频率越高相应的成分越小,为此要在对语音信号s(n)进行分析之前对其高频部分加以提升。通常的措施是用数字滤波器实现预加重,预加重网络的输出 和输入的语音信号s(n)的关系为:

其中a为预加重系数,一般取,本系统中取a= 0.9375。
单词 interesting数据显示

单词 interesting数据经预加重后
2.2 分帧
贯穿于语音分析全过程的是“短时分析技术”。语音信号具有时变特性,但是在一个短时间范围内(一般认为在10~30ms的短时间内),其特性基本保持不变即相对稳定,因而可以将其看作是一个准稳态过程,即语音信号具有短时平稳性。所以任何语音信号的分析和处理必须建立在“短时”的基础上,即进行“短时分析”,将语音信号分段来分析其特征参数,其中每一段称为一“帧”,帧长一般取为10~30ms。这样,对于整体的语音信号来讲,分析出的是由每一帧特征参数组成的特征参数时间序列。
2.3 加窗
由于语音信号具有短时平稳性,我们可以对信号进行分帧处理。紧接着还要对其加窗处理。窗的目的是可以认为对抽样n附近的语音波形加以强调而对波形的其余部分加以减弱。对语音信号的各个短段进行处理,实际上就是对各个短段进行某种变换或施以某种运算。用得最多的三种窗函数是矩形窗、汉明窗(Hamming)和汉宁窗(Hanning),其定义分别为: 矩形窗和汉明窗的比较:
矩形窗和汉明窗的比较:
矩形窗,主瓣较窄,具有较高的频率分辨率,但具有较高的旁瓣,相邻谐波干扰比较严重。与矩形窗相比,汉明窗得到的频谱却要平滑得多。
2.4 端点检测
2.4.1 短时能量
短时能量序列反映了语音振幅或能量随着时间缓慢变化的规律
2.4.2 过零率

语音信号处理中的端点检测主要是为了自动检测出语音的起始点及结束点。
这里我们采用了双门限比较法来进行端点检测。双门限比较法以短时能量E和短时平均过零率Z作为特征,结合Z和E的优点,使检测更为准确,有效降低系统的处理时间,能排除无声段的噪声干扰,从而提高的语音信号的处理性能。

function [x1,x2] = vad(x)
%幅度归一化到[-1,1]
x = double(x);
x = x / max(abs(x));
%常数设置
FrameLen = 240;
FrameInc = 80;
amp1 = 10;
amp2 = 2;
zcr1 = 10;
zcr2 = 5;
maxsilence = 8; % 6*10ms = 30ms
minlen = 15; % 15*10ms = 150ms
status = 0;
count = 0;
silence = 0;
%计算过零率
tmp1 = enframe(x(1:end-1), FrameLen, FrameInc);
tmp2 = enframe(x(2:end) , FrameLen, FrameInc);
signs = (tmp1.*tmp2)<0;
diffs = (tmp1 -tmp2)>0.02;
zcr = sum(signs.*diffs, 2);
%计算短时能量
amp = sum(abs(enframe(filter([1 -0.9375], 1, x), FrameLen, FrameInc)), 2);
%调整能量门限
amp1 = min(amp1, max(amp)/4);
amp2 = min(amp2, max(amp)/8);
%开始端点检测
x1 = 0;
x2 = 0;
for n=1:length(zcr)
goto = 0;
switch status
case {0,1} % 0 = 静音, 1 = 可能开始
if amp(n) > amp1 % 确信进入语音段
x1 = max(n-count-1,1);
status = 2;
silence = 0;
count = count + 1;
elseif amp(n) > amp2 | ... % 可能处于语音段
zcr(n) > zcr2
status = 1;
count = count + 1;
else % 静音状态
status = 0;
count = 0;
end
case 2, % 2 = 语音段
if amp(n) > amp2 | ... % 保持在语音段
zcr(n) > zcr2
count = count + 1;
else % 语音将结束
silence = silence+1;
if silence < maxsilence % 静音还不够长,尚未结束
count = count + 1;
elseif count < minlen % 语音长度太短,认为是噪声
status = 0;
silence = 0;
count = 0;
else % 语音结束
status = 3;
end
end
case 3,
break;
end
end
count = count-silence/2;
x2 = x1 + count -1;
subplot(311)
plot(x)
axis([1 length(x) -1 1])
ylabel('Speech');
line([x1*FrameInc x1*FrameInc], [-1 1], 'Color', 'red');
line([x2*FrameInc x2*FrameInc], [-1 1], 'Color', 'red');
subplot(312)
plot(amp);
axis([1 length(amp) 0 max(amp)])
ylabel('Energy');
line([x1 x1], [min(amp),max(amp)], 'Color', 'red');
line([x2 x2], [min(amp),max(amp)], 'Color', 'red');
subplot(313)
plot(zcr);
axis([1 length(zcr) 0 max(zcr)])
ylabel('ZCR');
line([x1 x1], [min(zcr),max(zcr)], 'Color', 'red');
line([x2 x2], [min(zcr),max(zcr)], 'Color', 'red');

3. MFCC特征参数提取
什么是语音的特征参数?特征参数包括什么?怎么提取?
在语音信号中,包含着非常丰富的特征参数,不同的特征向量表征着不同的物理和声学意义。选择什么特征参数对说话人识别系统的成败意义重大。如果选择了好的特征参数,将有助于提高识别率。特征提取就是要尽量取出或削减语音信号中与识别无关的信息的影响,减少后续识别阶段需处理的数据量,生成表征语音信号中携带的说话人信息的特征参数。根据语音特征的不同用途,需要提取不同的特征参数,从而保证识别的准确率。
常用的语音特征参数有LPCC 和MFCC。LPCC 参数是根据声管模型建立的特征参数, 主要反映声道响应。MFCC 参数是基于人的听觉特性利用人听觉的临界带效应, 在Mel 标度频率域提取出来的倒谱特征参数。
Mel倒谱系数是根据人类听觉系统的特性提出的,模拟人耳对不同频率语音的感知。人耳分辨声音频率的过程就像一种取对数的操作。例如:在Mel频域内,人对音调的感知能力为线性关系,如果两段语音的Mel频率差两倍,则人在感知上也差两倍。
MFCC算法过程:
(1) 快速傅里叶变换(FFT)
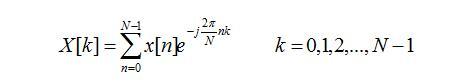

(2) 将实际频率尺度转换为Mel频率尺度:

(3) 配置三角形滤波器组并计算每一个三角形滤波器对信号幅度谱滤波后的输出:

(4) 对所有滤波器输出作对数运算,再进一步做离散余弦变换(DTC),即可得到MFCC:

function ccc = mfcc(x) % 归一化mel滤波器组系数 bank=melbankm(24,256,8000,0,0.5,'m'); bank=full(bank); bank=bank/max(bank(:)); % DCT系数,12*24 for k=1:12 n=0:23; dctcoef(k,:)=cos((2*n+1)*k*pi/(2*24)); end % 归一化倒谱提升窗口 w = 1 + 6 * sin(pi * [1:12] ./ 12); w = w/max(w); % 预加重滤波器 xx=double(x); xx=filter([1 -0.9375],1,xx); % 语音信号分帧 xx=enframe(xx,256,80); % 计算每帧的MFCC参数 for i=1:size(xx,1) y = xx(i,:); s = y' .* hamming(256); t = abs(fft(s)); t = t.^2; c1=dctcoef * log(bank * t(1:129)); c2 = c1.*w'; m(i,:)=c2'; end %差分系数 dtm = zeros(size(m)); for i=3:size(m,1)-2 dtm(i,:) = -2*m(i-2,:) - m(i-1,:) + m(i+1,:) + 2*m(i+2,:); end dtm = dtm / 3; %合并mfcc参数和一阶差分mfcc参数 ccc = [m dtm]; %去除首尾两帧,因为这两帧的一阶差分参数为0 ccc = ccc(3:size(m,1)-2,:);