ModuleNotFoundError: No module named 'scrapy.contrib'------使用ImagesPipeline时候--参考官方文档
貌似我写的时候还没有搜索到其他同学写这个问题,我就写一下吧。。。。。。
我貌似在使用的时候遇到问题:写下载图片使用内置的ImagesPipeline时候
Traceback (most recent call last):
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python36\lib\site-packages\twisted\internet\defer.py", line 1418, in _inlineCallbacks
result = g.send(result)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python36\lib\site-packages\scrapy\crawler.py", line 80, in crawl
self.engine = self._create_engine()
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python36\lib\site-packages\scrapy\crawler.py", line 105, in _create_engine
return ExecutionEngine(self, lambda _: self.stop())
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python36\lib\site-packages\scrapy\core\engine.py", line 70, in __init__
self.scraper = Scraper(crawler)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python36\lib\site-packages\scrapy\core\scraper.py", line 71, in __init__
self.itemproc = itemproc_cls.from_crawler(crawler)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python36\lib\site-packages\scrapy\middleware.py", line 53, in from_crawler
return cls.from_settings(crawler.settings, crawler)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python36\lib\site-packages\scrapy\middleware.py", line 34, in from_settings
mwcls = load_object(clspath)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python36\lib\site-packages\scrapy\utils\misc.py", line 44, in load_object
mod = import_module(module)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python36\lib\importlib\__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "", line 994, in _gcd_import
File "", line 971, in _find_and_load
File "", line 941, in _find_and_load_unlocked
File "", line 219, in _call_with_frames_removed
File "", line 994, in _gcd_import
File "", line 971, in _find_and_load
File "", line 941, in _find_and_load_unlocked
File "", line 219, in _call_with_frames_removed
File "", line 994, in _gcd_import
File "", line 971, in _find_and_load
File "", line 953, in _find_and_load_unlocked
ModuleNotFoundError: No module named 'scrapy.contrib' 也就是
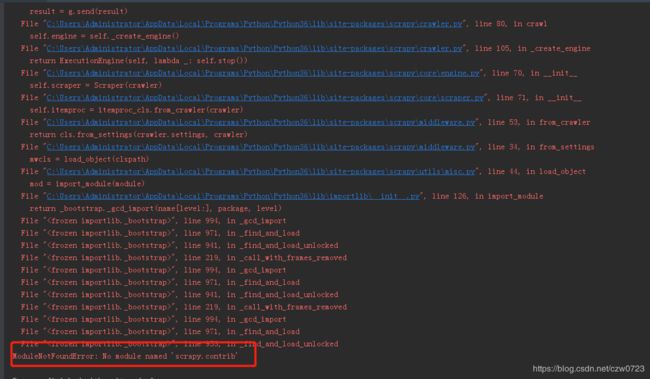
其实报错的原因只是。。。。。他没有这个包。。。因为其实这个包在。。
from scrapy.pipelines.images import ImagesPipeline这样子所以其实正确的写法,使用内置的是这样子写得(注意我注释的内容)
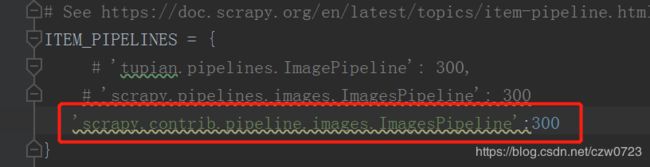
ITEM_PIPELINES = {
# 'tupian.pipelines.ImagePipeline': 300,
'scrapy.pipelines.images.ImagesPipeline': 300
# 'scrapy.contrib.pipeline.images.ImagesPipeline':300
}这样子就可以成功使用内置的东西额。。。巨坑。
我的整个setting.py如下
# -*- coding: utf-8 -*-
# Scrapy settings for tupian project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://doc.scrapy.org/en/latest/topics/settings.html
# https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# https://doc.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'tupian'
SPIDER_MODULES = ['tupian.spiders']
NEWSPIDER_MODULE = 'tupian.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://doc.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
# CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
# COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
# TELNETCONSOLE_ENABLED = False
# Override the default request headers:
# DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
# }
# Enable or disable spider middlewares
# See https://doc.scrapy.org/en/latest/topics/spider-middleware.html
# SPIDER_MIDDLEWARES = {
# 'tupian.middlewares.TupianSpiderMiddleware': 543,
# }
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# 'tupian.middlewares.TupianDownloaderMiddleware': 543,
# }
# Enable or disable extensions
# See https://doc.scrapy.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
# }
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
# 'tupian.pipelines.ImagePipeline': 300,
'scrapy.pipelines.images.ImagesPipeline': 300
# 'scrapy.contrib.pipeline.images.ImagesPipeline':300
}
IMAGES_STORE ='e:/img2'
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
# AUTOTHROTTLE_ENABLED = True
# The initial download delay
# AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
# AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
# AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# HTTPCACHE_ENABLED = True
# HTTPCACHE_EXPIRATION_SECS = 0
# HTTPCACHE_DIR = 'httpcache'
# HTTPCACHE_IGNORE_HTTP_CODES = []
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
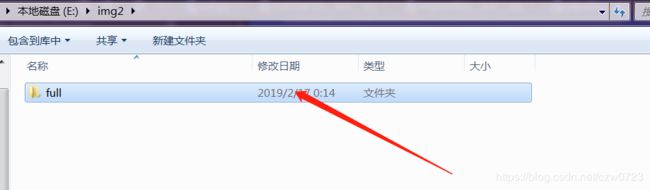
结果如下:e:/img2下面会有full文件夹,full下面就是下载的图片
完整代码可以去这里获取https://gitee.com/caizhw3/use-insider-ImagePipeline/tree/master