科大讯飞刷新纪录,机器阅读理解如何超越人类平均水平? | 技术头条

「2019 Python开发者日」明日开启,扫码咨询 ↑↑↑
记者 | 琥珀
出品 | AI科技大本营(公众号ID:rgznai100)
对于日常从事模型训练的研究人员来讲,无论是图像处理还是语音识别,都离不开一些高质量的数据集,通过它们以改善模型性能。
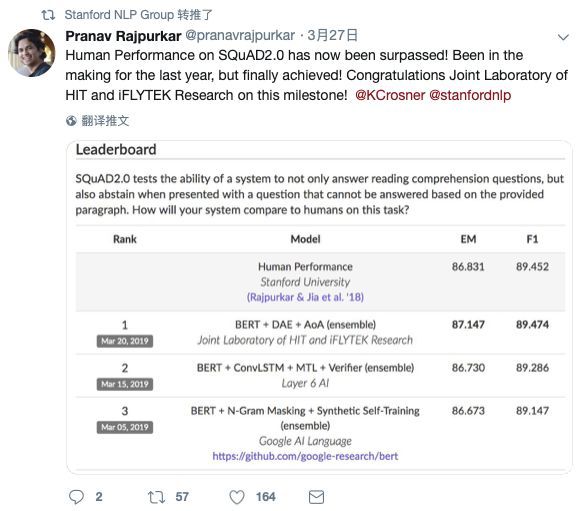
近日,科大讯飞凭借所研发的 ConvBERT 模型在对话型阅读理解评测 QuAC 上荣获冠军,全面刷新所有评测指标,其中 F1(模糊准确率)达到 68.0;随后,科大讯飞再次登上 SQuAD 2.0 挑战赛榜首,同时在 EM(精准匹配率)和 F1(模糊匹配率)两项指标上超越人类平均水平,创下测试新记录。

(QuAC榜单)

(SQuAD 2.0榜单)
实际上,各大研究机构或单位频频在当前主流的数据集上刷榜。有人并不认为经常刷榜有太大的意义,更重要的是如何模型的最新研究成果应用在实际中。对此,频频霸榜 SQuAD、QuAC、CoQA 等数据集的科大讯飞对以上问题是如何看待的呢?近日,AI 科技大本营采访了科大讯飞 AI 研究院资深级研究员、研究主管崔一鸣,并深度探究科大讯飞当前的技术与研究水平。
模型思路
问:浅谈讯飞提交的 “BERT + DAE + AoA” 模型技术相关解读,BERT 与 AoA 的融合过程与思路是怎样的?
答:本次提交的模型“BERT + DAE + AoA”,顾名思义,可从三个方面去剖析:
BERT:由谷歌提出的自然语言语义表征模型 BERT,在不同的自然语言处理任务上均获得了显著效果提升,也是目前各个评测系统中不可或缺的部分,是系统的基础部件。
DAE:另外,本次提交的系统包含 DAE(DA Enhanced)。这里的 DA 有两层含义,一个是数据增强(Data Augmentation),另一个是领域自适应(Domain Adaptation)。在 ACL 2017 会议上,我们就开始研究利用伪训练数据提升神经网络模型效果,并将之应用于中文零指代任务中获得显著性能提升。那么放在阅读理解中,就是要考虑如何能够自动生成大量的伪数据来进一步扩充训练数据,即 <篇章,问题,答案> 三元组。用过 BERT 的人都知道,在 BERT 的基础上很多原来的技术都不再有效,这就迫使我们从其他的角度来提升模型效果。可以看到微软提出的 MT-DNN 的这种多任务学习也是利用了多种数据的优势来提升 NLP 各个任务效果的。虽然方法不同,但有一点是相同的——即重视数据。
AoA:我们团队持续积累和改进的层叠式注意力机制(Attention-over-Attention,AoA)在不同任务上有不同的变种,比如在 SQuAD 1.1 时期的交互式层叠注意力(Interactive AoA)以及融合式(Hybrid AoA)等。实际上和众多的注意力计算方法一样,AoA 也是计算二元注意力的一种方法。在 SQuAD 2.0 任务上,我们重点关注 “回答” 和“拒答”之间的二元关系建模,通过 AoA 机制将两者联系起来,使得预测两者的时候能够达到 “信息互通”,而不是孤立的考虑“回答” 和“拒答”。
数据集之于 AI 应用的重要性
问:目前在自然语言处理评测方面,讯飞比较重视有哪些数据集?对比斯坦福最新问答数据集 CoQA,与 SQuAD 有哪些区别?
答:这里有个误区,不是为了做什么数据集而开展什么任务,而应该是为了开展什么任务选择了什么数据集。
哈工大讯飞联合实验室(Joint Laboratory of HIT and iFLYTEK Research, HFL)是国内外最早启动机器阅读理解研究的团队,从早期的填空型阅读理解(CNN/Daily Mail、CBT 等)、篇章片段抽取型阅读理解(SQuAD 等)、面向综合推理的阅读理解(RACE 等)到近期出现的对话型阅读理解(CoQA、QuAC 等)等任务都有涉及。
与业界所熟知的机器阅读理解评测 SQuAD 一样,CoQA 挑战赛同样由斯坦福大学发起,但侧重点与 SQuAD 评测不同。首先,CoQA 数据集中的问题不再是单轮的一问一答的形式,而是扩展到多轮的对话交互。当前问题的解答需要依赖历史对话记录,使得问题理解的难度大大增加。另外一个不同之处在于,CoQA 数据的答案不再是完全来自于篇章中的某一个连续片段,其答案可以是 Yes/No 或其它一些没有出现在篇章中的内容,使得该数据集更加符合真实的应用场景。总的来说,CoQA 挑战赛更加注重机器阅读理解技术在多轮对话中的应用,更加贴近产品。

CoQA 挑战赛数据示例
问:机器阅读理解数据集对讯飞模型训练的优化和落地带来了哪些影响?是否改善了现有的应用体验?
答:目前业界公开的机器阅读理解数据集无疑极大的推动了机器阅读理解领域的技术发展,也是验证技术进展的有效媒介。机器阅读理解技术的发展会推动产品的迭代发展,可以相对提升产品用户体验。
但与此同时,要清楚认识到研究到产品落地还是存在一定的、甚至极大的差异。一个产品的成功不仅仅依靠底层的技术,还依赖很多外围的因素。举个例子,我们将机器阅读理解技术应用在汽车智能说明书产品中时遇到的其中一个问题就是只有很少的训练数据,这使得初期模型效果很不好。所以模型再好如果没有充足的训练数据还是很难达到良好的效果。后期我们在训练数据的获取方面做了很多工作,其中一个重要环节就是如何从其他领域 “借” 数据,从而扩充现有的训练数据。所以如何能够形成技术和数据之间的 “涟漪效应” 是技术在产品化过程中需要重点考虑的内容,而且并非仅单单依靠技术的提升。
机器阅读理解的未来
问:在之前的分享中,您也提到了对机器阅读理解未来发展方向的看法,能否具体展开论述?
答:除了此前的提到的“引入深层推理,外部知识的阅读理解”,我主要讲讲另外两点:
1)阅读理解过程的可解释性:
这个话题实际上比较大,可以归结到神经网络模型的可解释性上。在多数场合下,用户是不需要知道为什么机器给出这样那样的答案,只需要知道最终的结果就可以了。但在一些特定领域,例如医疗、司法,如果机器仅仅给出最终的决策会很难信服用户。举个例子,如果在未来 AI 技术提升到了新的台阶,或许医院会使用 “AI 诊疗系统” 来辅助医护人员的日常工作。但如果机器不能给出诊断结果的依据,作为医护人员会很难给出更加精准的诊断结果,同时大大增加患者对医院的不信任。所以对于特定领域,不仅需要机器能够 “知其然” 更要“知其所以然”。这就使得机器阅读理解,甚至上升到整个 AI 技术的可解释性显得尤为重要。
2)阅读理解与其他自然语言处理任务的结合:
阅读理解从狭义上来说是对给定篇章理解并回答相关问题的任务,从广义上讲其实就是对上下文的理解。我们和哈工大的张伟男副教授在去年的 COLING 2018 上发表了一篇文章,将阅读理解的思想融入多轮对话任务的回复生成中并取得了不错的效果。其中历史的对话信息可以看做是阅读理解中的“篇章”,而当前的询问(Query)可以看做阅读理解中的“问题”,所得到的对话回复则是“答案”。这样我们就可以利用阅读理解的思想对多轮对话回复生成任务进行建模。目前,CoQA、QuAC 这类对话型阅读理解任务实际上就是将阅读理解与多轮对话任务结合的例子。相信未来阅读理解技术能够助力更多自然语言处理任务。
如何看待“刷榜”?
问:有人并不认为经常刷榜有太大的价值和意义,讯飞如何看待的?
答:关于 “刷榜” 现象,我从两方面分析这个问题。
首先,从 “刷” 的频率来考虑这个问题。目前榜单上的一些 “常客” 实际上都保持在 3~6 个月左右为间隔来提交结果验证,如果从这个角度来看 “刷” 的速度并不是那么快。但因为像 SQuAD 这类评测参赛队伍众多,目前刷新频率大概是一周一次,所以给人一种榜单日新月异的感觉。
其次,从 “刷” 的目的来考虑这个问题。对于高校来说,有这样一个公平的评测平台无疑可以大大增加研究成果曝光的几率,促进学术交流。对于企业来说,这样的一些公开评测平台是验证产品技术的有效手段。我上面也提到,一个产品的成功不仅仅是依靠技术的提升,是多种因素共同作用下产生的结果。所以想找到产品效果提升的来源到底是技术的提升还是数据的优化又或者是其他的因素,是比较困难的。所以通过这样的公开评测可以将其他因素剥离开,可以更 “纯净地” 评测技术方案的好坏,从而更好的制定下一步产品提升的方案。所以如果是为了推动技术进步、促进学术交流、提升产品效果等目的 “刷榜” 并不是什么坏事。
(本文为 AI大本营原创文章,转载请微信联系 1092722531)
◆
倒计时1天
◆
「2019 Python开发者日」演讲议题全揭晓!这一次我们依然“只讲技术,拒绝空谈”10余位一线Python技术专家共同打造一场硬核技术大会。更有深度培训实操环节,为开发者们带来更多深度实战机会。目前大会倒计时 1 天,更多详细信息请咨询13581782348(微信同号)。

推荐阅读:
抵制996!Python之父发声背后,这个社区一呼百应!
39个国外SCI抢发6万篇中国英文论文?然而,真正的问题是……
什么是网络爬虫?有什么用?怎么爬?终于有人讲明白了
“重构”黑洞:26岁MIT研究生的新算法 | 人物志
程序员 996 再上热搜,黑名单增至 84 家!
京东“地震”
V神玩起freestyle! 5位以太坊核心大咖在悉尼的演讲精华全在这了!| 直击EDCON
为什么给黑洞拍照需要这么长时间?
刺激!我31岁敲代码10年,明天退休!
![]()
❤点击“阅读原文”,了解「2019 Python开发者日」