论文: https://arxiv.org/abs/1803.02349
题外话:
阿里和香港理工联合发布的这篇文章,整体来说,还挺有意思的。
刚开始随便翻翻看看结构图的时候,会觉得:这也能发文章???
后来,细看后发现:哦~~还不错
文章简介:
基于阿里巴巴电商推荐系统的十亿规模的商品嵌入
与词向量类似,为每一个商品生成一个向量,向量间一一匹配,将相似的设定为推荐的候选
这篇文章的着重点在RS的matching,而不是ranking
针对阿里的数据集应用需要解决的三个难题:
1)数据量大
2)数据稀疏性(用户仅点击过库中数据的一小部分)→通过图谱结构解决,而不是传统的协同过滤
3)冷启动:店家会不定期上新,这些上新的商品并没有发生过用户行为,如何处理这些数据→将边信息考虑进去
渐进地提出了3个框架:BES, GES, EGES
数据:基于用户行为(点击顺序)构成的商品图谱(数据清洗:为节省计算空间以及考虑到用户的兴趣会随时间改变,构建序列时长限定为1个小时;去除刷单的用户,每月购买件数>1000或历史购买数>3500),每条边的权值由用户行为决定,如有100个用户从A点到了B,那个A到B的权值暂定为100

BES: base graph embedding
这是本篇文章中最基础的一个框架,借用的deep walk的算法,random walk后得到序列,扔进skip-gram训练

GES: graph embedding with side information
这一框架,将边信息考虑进去,边信息是指商品的属性,如品牌,店家,材质,价格等,因为认为用户的偏好可能跟这些属性有关。
在网络输入时,将商品的one-hot与各个属性的one-hot输入,embedding后直接concat,通过一个隐含层,后面的跟BES差不错
EGES:
enhanced graph embedding with side information
这一框架,基于GES,认为每一个属性是带权值的,每一条边,不应同等对待。即用户同时喜欢这两件衣服,可能是因为他们都是牛仔外套,或者因为他们都是优衣库的。因此,在得到商品及属性的embedding后,乘以一个权值再进去隐含层

结果:

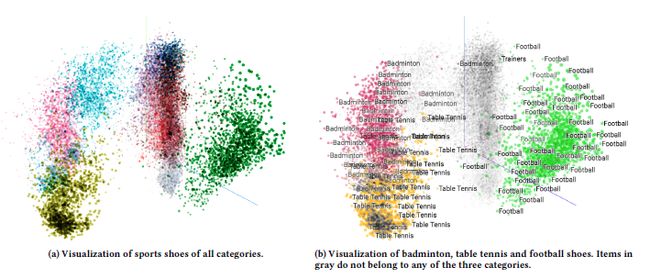
从下图的可视化可以看出,相同种类的可以被分到临近的区域