【Hadoop】hadoop+spark配置
不是教程,教程请看http://www.cnblogs.com/zyrblog/p/8510506.html
只是个人笔记
发现了一个尴尬事
首先需要说明的是,spark+hdfs是标准的业界应用搭配,从hdfs里读文件,用spark处理
但如果只是为了学spark,建议搭建单节点的伪分布式,文件读取全从本地读取,少个hdfs少点破事,因为如果用的是真的分布式,那么读取本地文件的时候,要求每个节点都有一个对应的文件才行。
准备材料
- 一台能联网的电脑
- VMware 14
- Centos 7 1801 64bit 我还是喜欢centos多一些,old fashion,好吧其实是装了一次ubuntu发现里面缺的东西有点多,ifconfig,vim都没有还得自己安,烦
- jdk-8u191-linux-x64.tar.gz
- spark-2.3.3-bin-hadoop2.7.tgz
- hadoop-2.9.1.tar.gz
- Scala 2.11.12
spark hadoop java scala之间有版本约束,要注意看文档,
spark对hadoop和scala和java的版本有要求,scala对java的版本也有要求
安装虚拟机
装好vmware 安装linux系统注意再安装的时候一定要选择稍后安装操作系统,否则默认是最小化安装,里面的东西都不全,还要后装很多东西
时区一定要选对!!
尽量装英文的
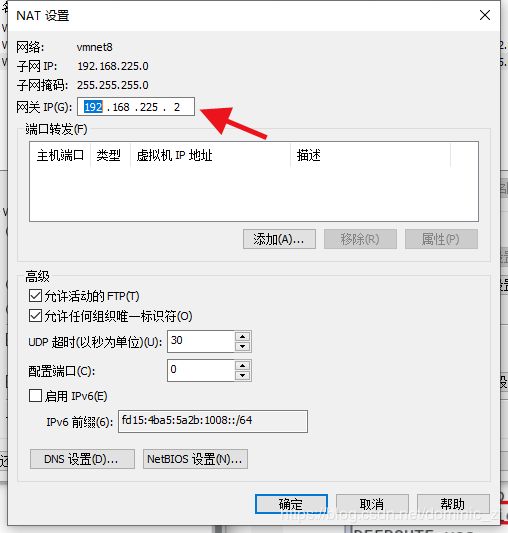
配置虚拟机各种东西之后,网络选择nat,之后再改ip
安装的时候要完整安装,一定完整安装,要不屁事太多烦得很
别忘了设置用户密码,不同主机的用户名保证一致

装完之后改息屏时间,改分辨率,改清华镜像,ping一下主机看看联通不
https://mirrors.tuna.tsinghua.edu.cn/help/centos/
然后进root,用visudo修改sudoer文件
然后改固定ip,红框内是需要添加或者修改的,我配的是master 192.168.225.3 slave是192.168.225.4
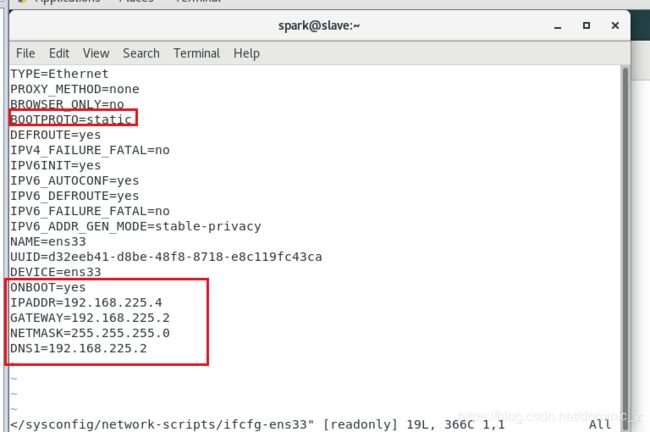
别忘了遵守VMware的nat机制,DNS要写的,写和网关一致
改hosts,在/etc/hosts里改
host里别有奇怪的字符,下划线也不行
关防火墙,关防火墙开机启动,这玩意指不定什么时候坏事
还有配置免密登录,master到自己和到slaves们都要免密
确定能联网!!!确认两台机器的时间设置可以GNU手动同步网络时间
ntpdate ntp.api.bz
然后拍个快照别忘了
hadoop配置
Java配置
从主机往虚拟机复制东西的时候,请右键复制粘贴,不能直接拖,会丢数据
另外Centos7自带了openjdk,删掉,一共四个
使用CentOS7卸载自带jdk安装自己的JDK1.8
然后安装java,修改profile
删除完想着source一下profile文件,更新一下java的路径
Hadoop
hadoop配置
http://www.cnblogs.com/zyrblog/p/8510506.html
再根据CZ的那个day6的docx文档
博客里的yarn文件里下面这俩不用配,因为默认就是这俩值,博客里也没配置java路径,需要再hadoop-env.sh里给定java的家目录,master和slave都要

验证hadoop
进hadoop/bin/hdfs namenode -format
hadoop/sbin/start-dfs.sh
hadoop/sbin/start-yarn.sh
然后jps看看进程跑起来没
namenode

datanode
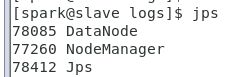
node是dfs的,manager是yarn的,少一个都不行
然后打开个浏览器,进192.168.225.4:50070有界面就OK了
如果想方便一点的话可以把hadoop/bin添加到path
hadoop fs -mkdir -p /wordcount/input
hdfs dfs -put ./hadoop-spark-namenode-master.log /wordcount/input
有文件就正常了
然后执行一个内置的wordcount范例
hadoop jar share/hadoop/mapreduce/sources/hadoop-mapreduce-examples-2.9.1-sources.jar org.apache.hadoop.examples.WordCount /wordcount/input /wordcount/output
然后看看输出结果
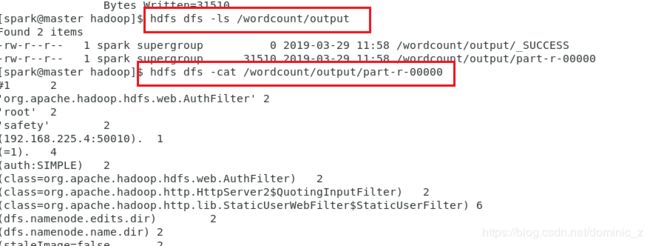
然后sbin/stop-dfs.sh,sbin/stop-yarn.sh
拍个快照
万一报错,报错就去看log,yarn和dfs关闭的情况下logs文件夹里的东西随便删
过程中遇到了一个incompatible clusterids错误
按照http://blog.chinaunix.net/uid-20682147-id-4214553.html说的解决了
“Incompatible clusterIDs”的错误原因是在执行“hdfs namenode -format”之前,没有清空DataNode节点的data目录。
是因为我执行了好几次的hdfs namenode -format,因为配置错了好几次。。嗯。。。。
Spark
教程https://www.cnblogs.com/zyrblog/p/8527048.html
结合CZ的day28 spark基础文档
注意文档内要求的scala版本

装scala
和装java差不太多
Spark
博主说有个东西很重要,下图的配置都很重要,下图就是三种指定hadoop类路径的方法,第一行是如果hadoop家目录已经在环境变量里的配置方法,但是还是推荐绝对路径配置吧,这玩意可以让spark更简单地连接上hadoop

配置完之后spark-shell一下

报了个警告,心里不爽
![]()
解决方案
运行Spark-shell,解决Unable to load native-hadoop library for your platform
直接在spark-env.sh里指定如下就行
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native/
其他配置按照博客里的来,spark-env.sh文件里有各个参数的解释,但是这个博主仍然没有配置javahome,2019614发现,不配javahome也行 = =
给个我的配置
export SPARK_MASTER_HOST=master
export JAVA_HOME=/home/spark/app/jdk
export SPARK_DIST_CLASSPATH=$(/home/spark/app/hadoop/bin/hadoop classpath)
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native/
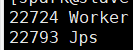
然后spark/sbin/start-all.sh,然后jps
![]()
然后打http://192.168.225.3:8080/和http://192.168.225.4:8081/看看是不是有webui,一个是master的一个是worker的
下面这个是master的,有一个worker,没错
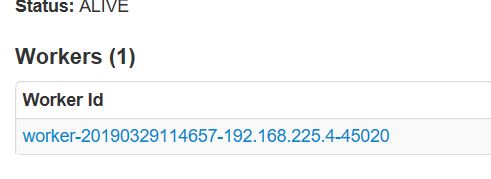
测试spark
开dfs和yarn,做个wordcount需要hdfs里的文件
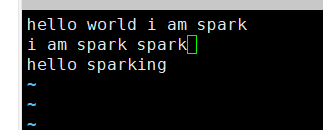
然后上传上去

然后开spark-shell

ok连上了,hdfs的9000端口是hdfs的入口,这个是在hadoop的core-site.xml里配置的
至此hadoop+spark配置完成
当然,其实spark自己也能玩,只是hadoop提供了一个dfs而已,没有hadoop,spark可以直接读本地的文件,这时候spark-env.sh里就不用配置和hadoop相关的东西就可以了,但是master和slave什么的还是要的
补充一个只有spark没有hadoop的本地环境搭建方法
其实很简单
先配置java和scala
然后改spark-env.sh
export SPARK_MASTER_HOST=master
再改slaves文件
master
IDEA
就解压,然后执行bin/idea.sh,就会有idea的初始化进程
这个可以先= =不创建了吧,没必要吧,算了创建一下吧,装idea的话内存啊cpu啊什么的给足一些,否则很容易卡
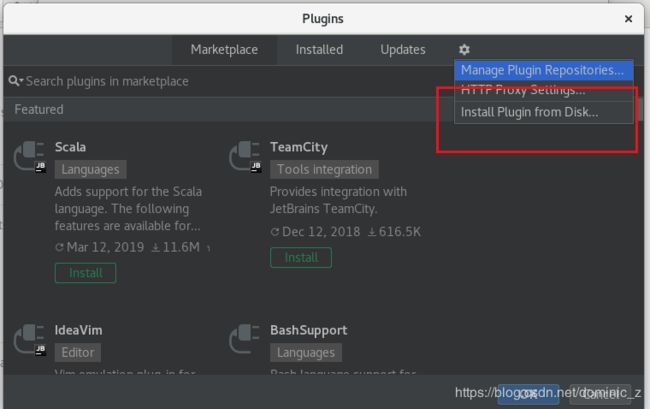
装个scala插件,在线装太慢了,我主机在
http://plugins.jetbrains.com/idea找然后下个离线安装包扔进去就行
尽量用sbt构建项目,但是= =好TMD慢,算了用idea构造吧
我觉得在linux虚拟机里用idea进行本地程序调试最舒服了,具体怎么做请看图解spark那本书的第一章