大数据Spark “蘑菇云”行动第87课:Hive嵌套查询与Case、When、Then案例实战
大数据Spark “蘑菇云”行动第87课:Hive嵌套查询与Case、When、Then案例实战
上一节课的数据库连接资源释放代码
/**
* 4、释放资源
*/
public static void release(Connection con, Statement st, ResultSet rs){
if(rs != null){
try {
rs.close();
} catch (SQLException e) {
e.printStackTrace();
}finally{
rs = null;
}
}
if(st != null){
try {
st.close();
} catch (SQLException e) {
e.printStackTrace();
}finally{
st = null;
}
}
if(con != null){
try {
con.close();
} catch (SQLException e) {
e.printStackTrace();
}finally{
con = null;
}
}
}
原始的子查询:
select subquery.member.....(SELECT .... FROM table) subquery
hive> 的操作:
show databases;
use default;
show tables;
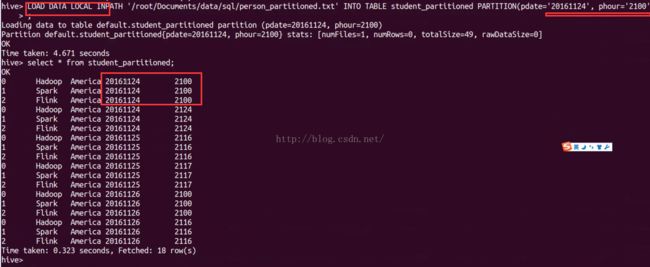
select * from student_partitioned;
//子查询
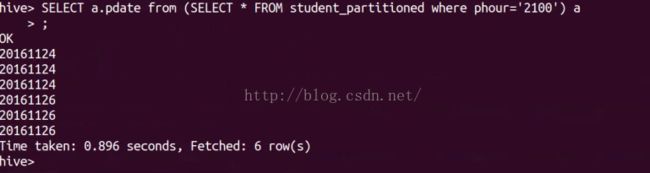
SELECT a.pdata from (select * from student_partitioned where phour='2100') a
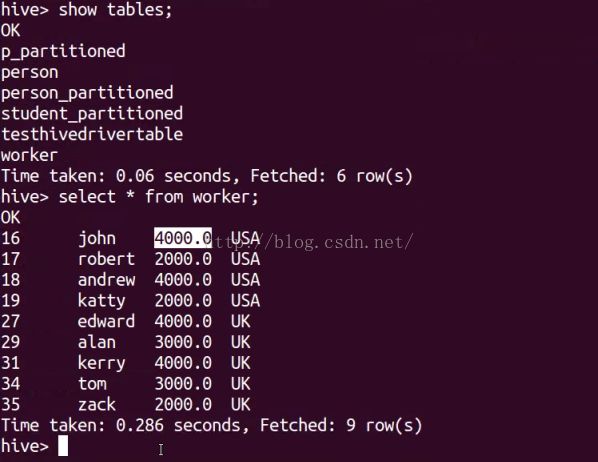
show tables;
select * from worker;
drop table worker;
show tables;
//重新来一次,建立表员工信息加薪水、级别
create external table employee (userid int, name string,address string,salary double,level string) comment 'partiaoned tble example' partitoned by (pdata string,phour,string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'");
desc employee
//PARTITIONED BY (pdate STRING, phour STRING)改变了一下语句顺序,会报错。
create external table employee (userid INT, name STRING, address STRING, salary Double, level String) comment 'Partitioned Talbe Example' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n' PARTITIONED BY (pdate STRING, phour STRING) stored as textfile;
//去掉了level,再来了一次
hive>drop table worker;
hive>create external table employee (userid int, name string,address string,salary double ) comment 'partiaoned tble example' partitoned by (pdata string,phour,string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'");
hive>desc employee
hive>load data local inpath '/..../employee.txt int tables employee partiton(pdata='20161127',phour='2055')
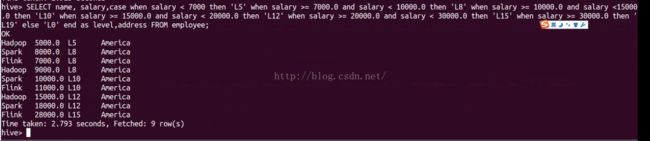
hive>select name,salary,
case
when salary < 7000 then 'L5'
when salary >=7000 and salary < 10000 .0 then 'L8'
when salary >= 10000.0 and salary <15000.0 then 'L10'
when salary >= 15000 .0 and salary < 20000.0 then 'L12'
when salary >= 20000 and salary < 30000.0 then 'L15'
when salary >=30000.0 then 'L19'
else 'L0'
end as level,address
from employee;
SELECT name, salary,case when salary < 7000 then 'L5' when salary >= 7000.0 and salary < 10000.0 then 'L8' when salary >= 10000.0 and salary <15000.0 then 'L10' when salary >= 15000.0 and salary < 20000.0 then 'L12' when salary >= 20000.0 and salary < 30000.0 then 'L15' when salary >= 30000.0 then 'L19' else 'L0' end as level,address FROM employee;