数据内容为1990年加州人口普查中所收集的信息。具体内容包括:各个区域内的收入的中位数,人口数量,房龄中位数,家庭数,总共房间数,总共卧室数,经纬度。
这里的分析任务是完成房屋价值预测的多元回归分析,但不考虑数据集中的多重共线性将会使得回归非常不稳定,预测值较小的变化则会导致结果极大的变化。此时正是主成分分析发挥作用的时候。因而主成分分析可以作为回归分析或者分类等分析内容的基础步骤。
---------
#读取数据
> houses<- read.csv(file="C:....\houses.txt",header=FALSE,sep="")
#查看数据
> head(houses)
V1 V2 V3 V4 V5 V6 V7 V8 V9
1 452600 8.3252 41 880 129 322 126 37.88 -122.23
2 358500 8.3014 21 7099 1106 2401 1138 37.86 -122.22
3 352100 7.2574 52 1467 190 496 177 37.85 -122.24
4 341300 5.6431 52 1274 235 558 219 37.85 -122.25
5 342200 3.8462 52 1627 280 565 259 37.85 -122.25
6 269700 4.0368 52 919 213 413 193 37.85 -122.25
#命名
> names(houses)<-c("MVAL","MINC","HAGE","ROOMS","BEDRMS","POPN","HHLDS","LAT","LONG")
#数据描述
> summary(houses)

##从数据描述中看到变量中有很大的差异,故需要对数据进行规则化处理。
#数据规则化
> houses$MINC_Z<-(houses$MINC-mean(houses$MINC))/sd(houses$MINC)
#其他数据同样方式处理
> houses$LONG_Z<-(houses$LONG-mean(houses$LONG))/sd(houses$LONG)
#取出规则化的数据,命名为数据集houses_z
> houses_z<- subset(houses,select = c(10:17))
#通过相关性矩阵,探索变量之间的相关性,
>cor(houses_z)

#随机选择90%的数据用于训练集,剩下10%的数据用作训练集
> choose<-runif(dim(houses_z)[1],0,1)
> train.house<-houses_z[which(choose>=.1),]
#加载库psych
> library(psych)
#训练集数据进行主成分分析
> pcal<-principal(train.house,nfactors = 8,rotate="none",scores = TRUE)
#特征值,负载矩阵和解释变异
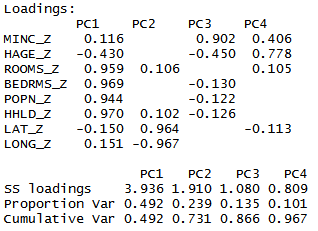
> pcal$loadings

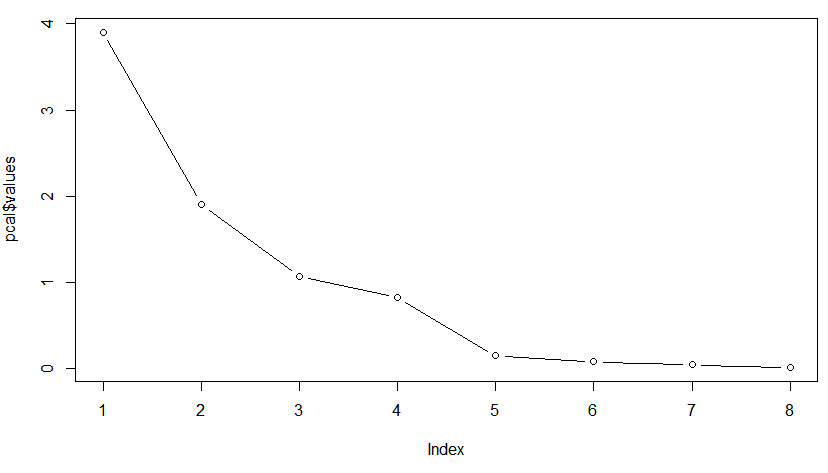
##从解释变异中可以看到第一主成分解释了48.8%的数据变异。那么应该提取多少个主成分?特征值为1表示该成分解释至少一个变量价值的变异性,因而只有特征值大于1的主成分应该保留,这样我们有三个主成分应当保存,然而我们看到主成分4的特征变量为0.823,非常接近1, 那么是否应该保留这个主成分?这里可以去参考其他的标准。第一个标准就是解释变异标准,及分析人员定义他认为的主成分应该具有多大的变异程度,是85%,90%还是更高,如果要求高于95%,那么应该保存第四个主成分,因为累计到第四个主成分解释了96.3%的变异。除此之外,还有一种标准就是坡度图标准,坡度图标准就是曲线开始变得平缓时候的那一点就是最多主成分的取值。如下图展示,按照坡度图标准,提取不超过4个主成分。
#坡度图
> plot(pcal$values,type="b")
##结果解读:
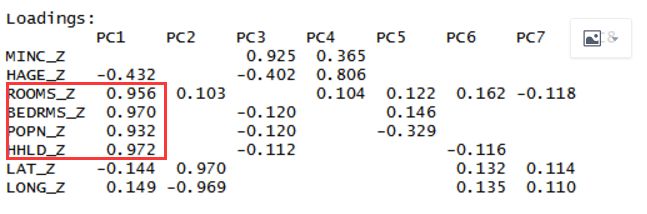
主成分一:按照权重成分的相关系数,我们选取房间数,卧室数,人口数,家庭数。可以将其归类为大小主成分
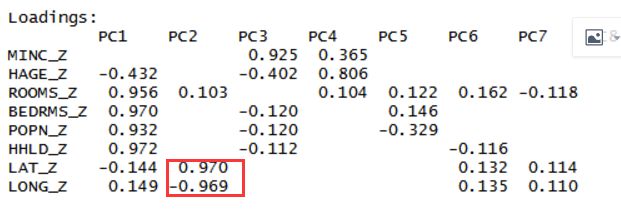
主成分二:由地理位置信息组成的经纬度信息
主成分三:平均收入构成收入因素
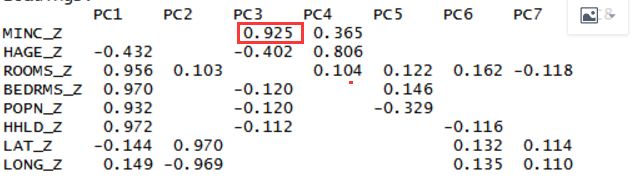
主城分四:平均房龄构成房龄因素、
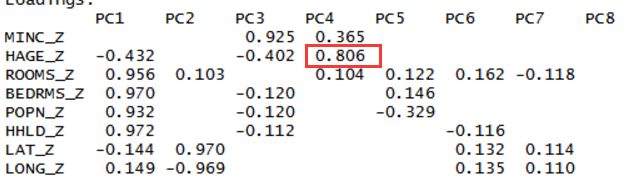
#针对测试数据集进行主成分分析
##该步骤即通过样本分裂来进行主成分的验证,来看训练数据集的结果是否对整体数据内容具有概括性。从如下结果能够看到,虽然测试集结果中的权重和解释变异与训练集中并非完全一致。但主成分的提取和权重的解释是与训练集一致的。
> pca2<-principal(test.house,nfactors=4,rotate = "none",scores = TRUE)
> pca2$loadings