《Python机器学习基础教程》模型评估指标(精度、混淆矩阵、准确率、召回率、f-分数、准确率召回率曲线、ROC曲线以及AUC)
《Python机器学习基础教程》笔记
总结监督模型在给定数据集上的表现有很多种方法,例如,精度、混淆矩阵、准确率、召回率、f-分数、准确率召回率曲线、ROC曲线以及AUC。下面先以二分类为例,解释各种评估指标的含义,然后再拓展多分类的指标,最后简单介绍一下回归指标。
一、二分类
首先需要掌握几个术语的含义:
①假正例(FP):预测错误,预测为“正”类,但实际是“反”类。
②假反例(FN):预测错误,预测为“反”类,但实际是“正”类。
③真正例(TP):预测正确,预测为“正”类,实际也是“正”类。
④真反例(TN):预测正确,预测为“反”类,实际也是“反”类。
1. 精度:正确分类的样本所占的比例。
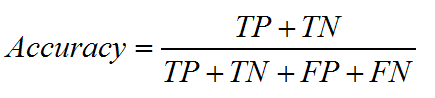
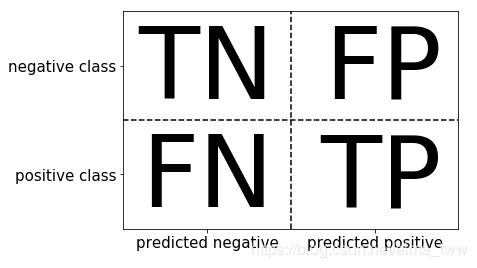
2. 混淆矩阵:行对应真实标签,列对应预测标签。对角线上的元素对应于正确的分类,而其他元素则告诉我们一个类别中有多少样本被错误地划分到其他类别中。即
3. 准确率:被预测为正例的样本中有多少是真正的正例。
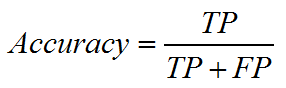
4. 召回率:正类样本中有多少被预测为正类。

5. f-分数:准确率与召回率的调和平均
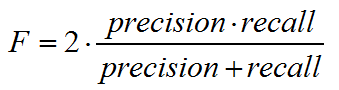
6. 准确率召回率曲线:对decision_function的每一个阈值,求得一个准确率和召回率,分别作为横坐标和纵坐标作图。
总结准确率-召回率曲线的一种方法是计算该曲线下的积分或面积,也叫作平均准确率。
7. ROC曲线:和准确率召回率曲线类似,纵坐标为召回率,但横坐标为假正例率(反类样本中被误判为正类的样品比例):

对于ROC曲线,理想的曲线要靠近左上角(召回率高、假正例低)
8. AUC:ROC曲线下的面积。
二、多分类
1. 多分类问题的所有指标基本上都来着于二分类指标,但是要对所有类别进行平均。利用classification_report函数,可以计算每个类别的准确率、召回率和f-分数。
2. 对于多分类问题中的不平衡数据集,最常用的指标就是多分类版本的f-分数。多分类f-分数背后的想法是,对每个类别计算一个二分类f-分数,其中该类别是正类,其他所有类别组成反类,然后使用以下策略之一对这些按类别f-分数进行平均:
①宏平均:计算未加权的按类别 f1-分数,对所有类别给出相同权重。
②加权平均:以每个类别的支持作为权重来计算按类别 f1-分数的平均值。
③微平均:计算所有类别中假正例、假反例和真正例的总数,然后利用这些计数来计算准确率、召回率和 f1-分数。
如果对每个样本等同看待,那么推荐使用微平均 f1-分数,如果对每个类别等同看待,则推荐使用宏平均 f1-分数。
三、回归指标
![]() 是评估回归模型的直观指标。
是评估回归模型的直观指标。
四、总结
Scikit-Learn提供了一种非常简单的评估方法,即scoring参数,它可以同时用于GridSearchCV和cross_val_score,只需要提供一个字符串,用于描述要使用的评估指标即可。
对于分类问题,scoring参数最重要的取值包括:accuracy(默认值)、roc_auc(ROC曲线下方的面积)、average_precision(准确率-召回率曲线下方的面积)、f1、f1_macro、f1_micro、f1_weighted;对于回归问题,最常用的取值包括:r2(![]() 分数)、mean_squared_error(均分误差)和mean_absolute_error(平均绝对误差)。
分数)、mean_squared_error(均分误差)和mean_absolute_error(平均绝对误差)。