开源 serverless 产品原理剖析 - Kubeless
背景
Serverless 架构的出现让开发者不用过多地考虑传统的服务器采购、硬件运维、网络拓扑、资源扩容等问题,可以将更多的精力放在业务的拓展和创新上。
随着 serverless 概念的深入人心,各大云计算厂商纷纷推出了各自的 serverless 产品,其中比较有代表性的有 AWS lambda、Azure Function、Google Cloud Functions、阿里云函数计算等。
另外,CNCF 也于 2016 年创立了 Serverless Working Group,它致力于 cloud native 和 serverless 技术的结合。下图是 CNCF serverless 全景图,它将这些产品分成了工具型、安全型、框架型和平台型等类别。
同时,容器以及容器编排工具的出现,大大降低了 serverless 产品的开发成本,促进了一大批优秀开源 serverless 产品的诞生,它们大多构建于 kubernetes 之上,如下图所示。
Kubeless 简介
本文将要介绍的 kubeless 便是这些开源 serverless 产品的典型代表。根据官方的定义,kubeless 是 kubernetes native 的无服务计算框架,它可以让用户在 kubernetes 之上使用 FaaS 构建高级应用程序。从 CNCF 视角,kubeless 属于平台型产品。
Kubless 有三个核心概念:
Functions - 代表需要被执行的用户代码,同时包含运行时依赖、构建指令等信息;
Triggers - 代表和函数关联的事件源。如果把事件源比作生产者,函数比作执行者,那么触发器就是联系两者的桥梁;
Runtime - 代表函数运行时所依赖的环境。
原理剖析
本章节将以 kubeless 为例介绍 serverless 产品需要具备的基本能力,以及 kubeless 是如何利用 K8s 现有功能来实现它们的。这些基本能力包括:
敏捷构建 - 能够基于用户提交的源码迅速构建可执行的函数,简化部署流程;
灵活触发 - 能够方便地基于各类事件触发函数的执行,并能方便快捷地集成新的事件源;
自动伸缩 - 能够根据业务需求,自动完成扩容缩容,无须人工干预。
本文所做的调研基于kubeless v1.0.0和k8s 1.13。
敏捷构建
CNCF 对函数生命周期的定义如下图所示。用户只需提供源码和函数说明,构建部署等工作通常由 serverless 平台完成。 因此,基于用户提交的源码迅速构建可执行函数是 serverless 产品必须具备的基础能力。

在 kubeless 里,创建函数非常简单:

该命令各参数含义如下:
hello:将要部署的函数名称;
--runtime python2.7: 指定使用 python 2.7 作为运行环境。Kubeless 可供选择的运行环境请参考链接 runtimes。
--from-file test.py:指定函数源码文件(支持 zip 格式)。
--handler test.hello:指定使用 test.py 中的 hello 方法处理请求。
函数资源与 K8s Operator
Kubeless 函数是一个自定义 K8s 对象,本质上是 k8s operator。k8s operator 原理如下图所示:
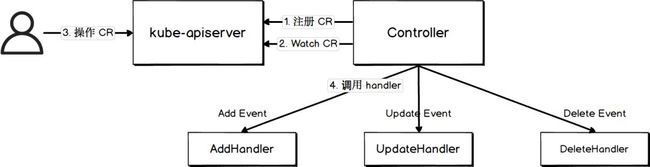
下面以 kubeless 函数为例,描述 K8s operator 的一般工作流程:
使用 k8s 的 CustomResourceDefinition(CRD) 定义资源,这里创建了一个名为functions.kubeless.io的 CRD 来代表 kubeless 函数;
创建一个 controller 监听自定义资源的 ADD、UPDATE、DELETE 事件并绑定 hander。这里创建了一个名为function-controller的 CRD controller,该 controller 会监听针对 function 的 ADD、UPDATE、DELETE 事件,并绑定 handler(参阅 AddEventHandler);
用户执行创建、更新、删除自定义资源的命令;
Controller 根据监听到的事件调用相应的 handler。
除了函数外,下文将要介绍的 trigger 也是一个 k8s operator。
函数构成
Kubeless 的 function-controller监听到针对 function 的 ADD 事件后,会触发相应 handler 创建函数。一个函数由若干 K8s 对象组成,包括 ConfigMap、Service、Deployment、Pod 等,其结构如下图所示:
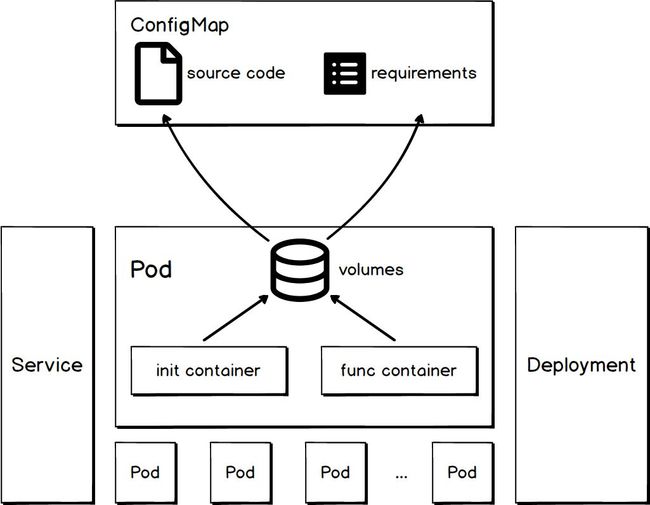
ConfigMap
函数中的 ConfigMap 用于描述函数源码和依赖。

Service
函数中的 Service 用于描述该函数的访问方式。该 Service 会与执行 function 逻辑的 Pods 相关联,类型是 ClusterIP。
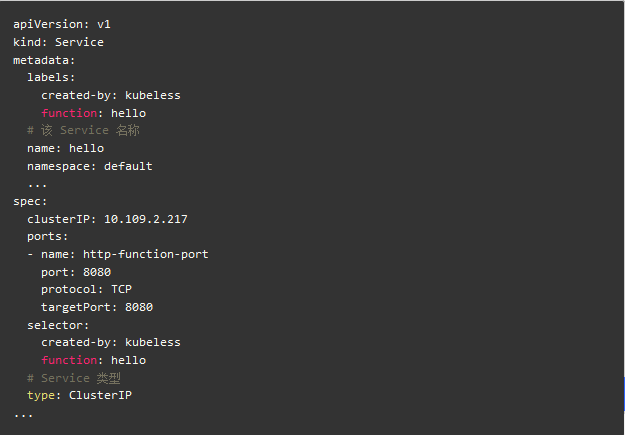
Deployment
函数中的 Deployment 用于编排执行函数逻辑的 Pods,通过它可以描述函数期望的个数。
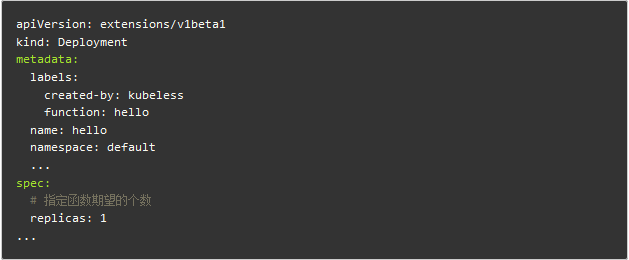
Pod
函数中的 Pod 包含真正执行函数逻辑的容器。
Volumes
Pod 中的 volumes 段指定了该函数的 ConfigMap。这会将 ConfigMap 中的源码和依赖添加到 volumeMounts.mountPath 指定的目录里面。从容器视角来看,文件路径为/src/test.py和 /src/requirements。

Init Container
Pod 中的 Init Container 主要作用如下:
将源码和依赖文件拷贝到指定目录;
安装第三方依赖。
Func Container
Pod 中的 Func Container 会加载 Init Container 准备好的源码和依赖并执行函数。不同 runtime 加载代码的方式大同小异,可参考 kubeless.py,Handler.java。
小结
Kubeless 通过综合运用 K8s 中的多种组件以及利用各语言的动态加载能力实现了从用户源码到可执行的函数的构建逻辑;
考虑了函数运行的安全性,通过 Security Context 机制限制容器中的进程以非 root 身份运行。
灵活触发
一款成熟的 serverless 产品需要具备灵活触发能力,以满足事件源的多样性需求,同时需要能够方便快捷地接入新事件源。CNCF 将函数的触发方式分成了如下图所示的几种类别,关于它们的详细介绍可参考链接 Function Invocation Types。
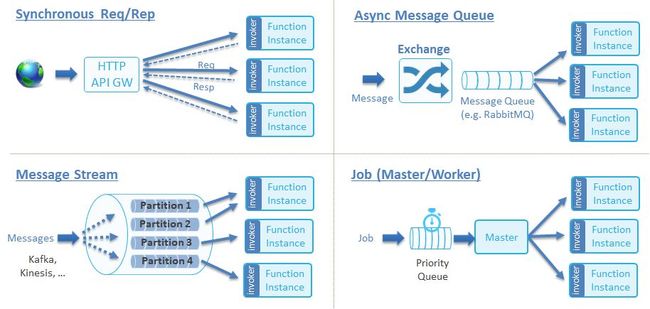
对于 kubeless 的函数,最简单的触发方式是使用 kubeless CLI,另外还支持通过各种触发器。下表展示了 kubeless 函数目前支持的触发方式以及它们所属的类别。
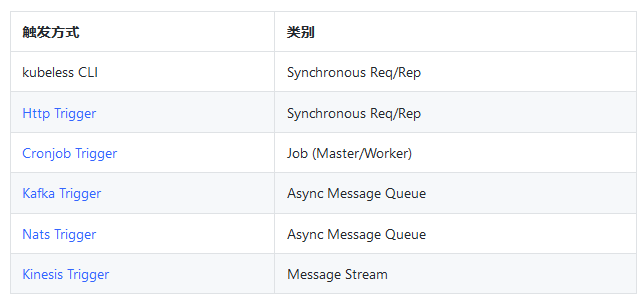
下图展示了 kubeless 函数部分触发方式的原理:
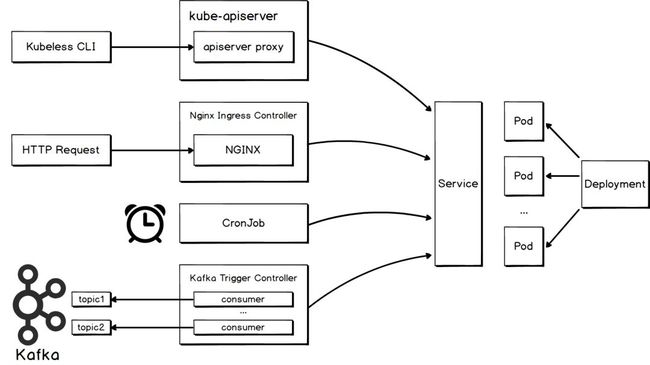
HTTP trigger
如果希望通过发送 HTTP 请求触发函数执行,需要为函数创建 HTTP 触发器。 Kubeless 利用 K8s ingress 机制实现了 http trigger。Kubeless 创建了一个名为httptriggers.kubeless.io的 CRD 来代表 http trigger 对象。同时,kubeless 包含一个名为http-trigger-controller的 CRD controller,它会持续监听针对 http trigger 和 function 的 ADD、UPDATE、DELETE 事件,并执行对应的操作。
以下命令将为函数 hello 创建一个名为http-hello的 http trigger,并指定选用 nginx 作为 gateway。

该命令会创建如下 ingress 对象,可以参考 CreateIngress 深入了解 ingress 的创建逻辑。

Ingress 只是用于描述路由规则,要让规则生效、实现请求转发,集群中需要有一个正在运行的 ingress controller。可供选择的 ingress controller 有 Contour、F5 BIG-IP Controller for Kubernetes、Kong Ingress Controllerfor Kubernetes、NGINX Ingress Controller for Kubernetes、Traefik 等。这种路由规则描述和路由功能实现相分离的思想很好地提现了 K8s 始终坚持的需求和供给分离的设计理念。
上文中的命令在创建 trigger 时指定了 nginx 作为 gateway,因此需要部署一个 nginx-ingress-controller。该 controller 的基本工作原理如下:
以 pod 的形式运行在独立的命名空间中;
以 hostPort 的形式暴露出来供外界访问;
内部运行着一个 nginx 实例;
监听和 ingress、service 等资源相关的事件。如果发现这些事件最终会影响到路由规则,ingress controller 会采用向 Lua hander 发送新的 endpoints 列表或者直接修改 nginx.conf 并 reload nginx 等手段达到更新路由规则的目的。
想要更深入地了解 nginx-ingress-controller 的工作原理可参考文章 how-it-works。
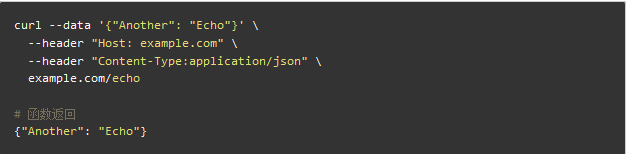
完成上述工作后,我们便可以通过发送 HTTP 请求触发函数 hello 的执行:
HTTP 请求首先会由 nginx-ingress-controller 中的 nginx 处理;
Nginx 根据 nginx.conf 中的路由规则将请求转发给函数对应的 service;
最后,请求会转发至挂载在 service 后的某个函数进行处理。
样例如下:
Cronjob trigger
如果希望定期触发函数执行,需要为函数创建 cronjob 触发器。K8s 支持通过 CronJob 定期运行任务,kubeless 利用这个特性实现了 cronjob trigger。Kubeless 创建了一个名为cronjobtriggers.kubeless.io的 CRD 来代表 cronjob trigger 对象。同时,kubeless 包含一个名为cronjob-trigger-controller的 CRD controller,它会持续监听针对 cronjob trigger 和 function 的 ADD、UPDATE、DELETE 事件,并执行对应的操作。
以下命令将为函数 hello 创建一个名为scheduled-invoke-hello的 cronjob trigger,该触发器每分钟会触发函数 hello 执行一次。

该命令会创建如下 CronJob 对象,可以参考 EnsureCronJob 深入了解 CronJob 的创建逻辑。

自定义 trigger
如果发现 kubeless 默认提供的触发器无法满足业务需求,可以自定义新的触发器。新触发器的构建流程如下:
为新的事件源创建一个 CRD 来描述事件源触发器;
在自定义资源对象的 spec 里描述该事件源的属性,例如 KafkaTriggerSpec、HTTPTriggerSpec;
为该 CRD 创建一个 CRD controller。
该 controller 需要持续监听针对事件源触发器和 function 的 CRUD 操作并作出正确的处理。例如,controller 监听到 function 的删除事件,需要把和该 function 关联的触发器一并删掉;
当事件发生时,触发关联函数的执行。
我们可以看到,自定义 trigger 的流程遵循了 K8s Operator 设计模式。
小结
Kubeless 提供了一些基本常用的触发器,如果有其他事件源也可以通过自定义触发器接入;
不同事件源的接入方式不同,但最终都是通过访问函数 ClusterIP 类型的 service 触发函数执行。
自动伸缩
K8s 通过 Horizontal Pod Autoscaler 实现 pod 的自动水平伸缩。Kubeless 的 function 通过 K8s deployment 部署运行,因此天然可以利用 HPA 实现自动伸缩。
度量数据获取
自动伸缩的第一步是要让 HPA 能够获取度量数据。目前,kubeless 中的函数支持基于 cpu 和 qps 这两种指标进行自动伸缩。下图展示了 HPA 获取这两种度量数据的途径。

内置度量指标 cpu
CPU 使用率属于内置度量指标,对于这类指标 HPA 可以通过 metrics API 从 Metrics Server 中获取数据。Metrics Server 是 Heapster 的继承者,它可以通过kubernetes.summary_api从 Kubelet、cAdvisor 中获取度量数据。
自定义度量指标 qps
QPS 属于自定义度量指标,想要获取这类指标的度量数据需要完成下列步骤。
部署用于存储度量数据的系统,这里选择已经被纳入 CNCF 的 Prometheus。Prometheus 是一套开源监控&告警&时序数据解决方案,并且被 DigitalOcean、Red Hat、SUSE 和 Weaveworks 这些 cloud native 领导者广泛使用;
采集度量数据,并写入部署好的 Prometheus 中。Kubeless 提供的函数框架会在函数每次被调用时,将下列度量数据 function_duration_seconds、function_calls_total、function_failures_total 写入 Prometheus(可参考 python 样例)。
部署实现了 custom metrics API 的 custom API server。这里,因为度量数据被存入了 Prometheus,因此选择部署 k8s-prometheus-adapter,它可以从 Prometheus 中获取度量数据。
完成上述步骤后,HPA 就可以通过 custom metrics API 从 Prometheus Adapter 中获取 qps 度量数据。详细配置步骤可参考文章 kubeless-autoscaling。
K8s 度量指标简介
有时基于 cpu 和 qps 这两种度量指标对函数进行自动伸缩还远远不够。如果希望基于其它度量指标,需要了解 K8s 定义的度量指标类型及其获取方式。
目前,K8s 1.13 版本支持的度量指标类型如下:

准备好相应的度量数据和获取数据的组件,HPA 就能基于它们对函数进行自动伸缩。更多关于 K8s 度量指标的介绍可参考文章 hpa-external-metrics。
度量数据使用
知道了 HPA 获取度量数据的途径后,下面描述 HPA 如何基于这些数据对函数进行自动伸缩。
基于 cpu 使用率
假设已经存在一个名为 hello 的函数,以下命令将为该函数创建一个基于 cpu 使用率的 HPA,它将运行该函数的 pod 数量控制在 1 到 3 之间,并通过增加或减少 pod 个数使得所有 pod 的平均 cpu 使用率维持在 70%。
Kubeless 使用的是 autoscaling/v2alpha1 版本的 HPA API,该命令将要创建的 HPA 如下:
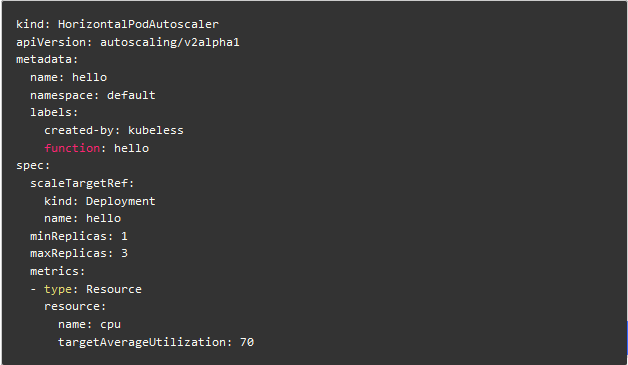
该 HPA 计算目标 pod 数量的公式如下:

基于 qps
以下命令将为函数 hello 创建一个基于 qps 的 HPA,它将运行该函数的 pod 数量控制在 1 到 5 之间,并通过增加或减少 pod 个数确保所有挂在服务 hello 后的 pod 每秒能处理的请求次数之和达到 2000。
该命令将要创建的 HPA 如下:
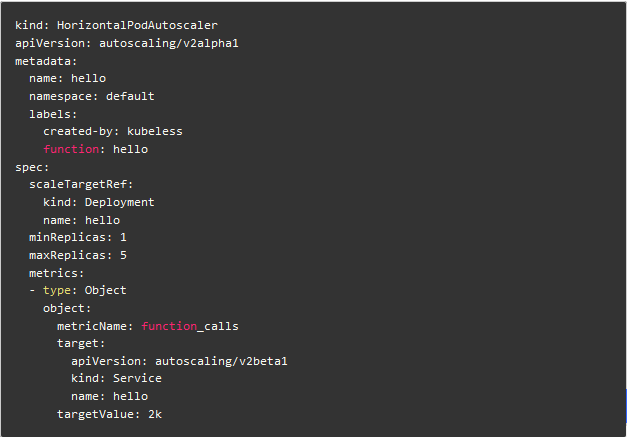
基于多项指标
如果计划基于多项度量指标对函数进行自动伸缩,需要直接为运行 function 的 deployment 创建 HPA。
使用如下 yaml 文件可以为函数 hello 创建一个名为hello-cpu-and-memory的 HPA,它将运行该函数的 pod 数量控制在 1 到 10 之间,并尝试让所有 pod 的平均 cpu 使用率维持在 50%,平均 memory 使用量维持在 200MB。对于多项度量指标,K8s 会计算出每项指标需要的 pod 数量,取其中的最大值作为最终的目标 pod 数量。

自动伸缩策略
一个理想的自动伸缩策略应当处理好下列场景:
当负载激增时,函数能迅速扩展以应对突发流量;
当负载下降时,函数能立即收缩以节省资源消耗;
具备抗噪声干扰能力,能够精确计算出目标容量;
能够避免自动伸缩过于频繁造成系统抖动。
Kubeless 依赖的 HPA 充分考虑了上述情形,不断改进和完善其使用的自动伸缩策略。下面以 K8s 1.13 版本为例描述该策略。如果想要更加深入地了解策略原理请参考链接 horizontal。
HPA 每隔一段时间会根据获取的度量数据同步一次和该 HPA 关联的 RC / Deployment 中的 pod 个数,时间间隔通过 kube-controller-manager 的参数--horizontal-pod-autoscaler-sync-period指定,默认为 15s。在每一次同步过程中,HPA 需要经历如下图所示的计算流程。
计算目标副本数
分别计算 HPA 列表中每项指标需要的 pod 数量,记为 replicaCountProposal。选择其中的最大值作为 metricDesiredReplicas。在计算每项指标的 replicaCountProposal 过程中会考虑下列因素:
允许目标度量值和实际度量值存在一定程度的误差,如果在误差范围内直接使用 currentReplicas 作为 replicaCountProposal。这样做是为了在可接受范围内避免伸缩过于频繁造成系统抖动,该误差值可以通过 kube-controller-manager 的参数--horizontal-pod-autoscaler-tolerance指定,默认值是 0.1。
当一个 pod 刚刚启动时,该 pod 反映的度量值往往不是很准确,HPA 会将这种 pod 视为 unready。在计算度量值时,HPA 会跳过处于 unready 状态的 pod。这样做是为了消除噪声干扰,可以通过 kube-controller-manager 的参数--horizontal-pod-autoscaler-cpu-initialization-period(默认为 5 分钟)和--horizontal-pod-autoscaler-initial-readiness-delay(默认为 30 秒)调整 pod 被认为处于 unready 状态的时间。
平滑目标副本数
将最近一段时间计算出的 metricDesiredReplicas 记录下来,取其中的最大值作为 stabilizedRecommendation。这样做是为了让缩容过程变得平滑,消除度量数据异常波动造成的影响。该时间段可以通过参数--horizontal-pod-autoscaler-downscale-stabilization-window指定,默认为 5 分钟。
规范目标副本数
限制 desiredReplicas 最大为 currentReplicas * scaleUpLimitFactor,这样做是为了防止因 采集到了“虚假的”度量数据造成扩容过快。目前 scaleUpLimitFactor 无法通过参数设定,其值固定为 2。
限制 desiredReplicas 大于等于 hpaMinReplicas,小于等于 hpaMaxReplicas。
执行扩容缩容操作
如果通过上述步骤计算出的 desiredReplicas 不等于 currentReplicas,则“执行”扩容缩容操作。这里所说的执行只是将 desiredReplicas 赋值给 RC / Deployment 中的 replicas,pod 的创建销毁会由 kube-scheduler 和 worker node 上的 kubelet 异步完成的。
小结
Kubeless 提供的自动伸缩功能是对 K8s HPA 的简单封装,避免了将创建 HPA 的复杂细节直接暴露给用户。
Kubeless 目前提供的度量指标过少,功能过于简单。如果用户希望基于新的度量指标、综合多项度量指标或者调整自动伸缩的效果,需要深入了解 HPA 的细节。
目前 HPA 的扩容缩容策略是基于既成事实被动地调整目标副本数,还无法根据历史规律预测性地进行扩容缩容。
总结
Kubeless 基于 K8s 提供了较为完整的 serverless 解决方案,但和一些商业 serverless 产品还存在一定差距:
Kubeless 并未在镜像拉取、代码下载、容器启动等方面做过多优化,导致函数冷启动时间过长;
Kubeless 并未过多考虑多租户的问题,如果希望多个用户的函数运行在同一个集群里,还需要进行二次开发。

end
在数据采集器中用TensorFlow进行实时机器学习
理解五个基本概念,让你更像机器学习专家
想成为数据科学家?先做到这6点吧!
云数据库 MongoDB 4.0 全新升级,震撼来袭
更多精彩