链接:http://shiyanjun.cn/archives/1855.html
https://www.slideshare.net/FlinkForward/flink-forward-berlin-2017-tzuli-gordon-tai-managing-state-in-apache-flink(有关于状态的序列化)
开启
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(60000);
env.setStateBackend(new FsStateBackend("hdfs://home/wangxiaotong/data/flink/checkpoints"));
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
上面调用enableExternalizedCheckpoints设置为ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION,表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint处理。上面代码配置了执行Checkpointing的时间间隔为1分钟。
保存多个Checkpoint
默认情况下,如果设置了Checkpoint选项,则Flink只保留最近成功生成的1个Checkpoint,而当Flink程序失败时,可以从最近的这个Checkpoint来进行恢复。但是,如果我们希望保留多个Checkpoint,并能够根据实际需要选择其中一个进行恢复,这样会更加灵活,比如,我们发现最近4个小时数据记录处理有问题,希望将整个状态还原到4小时之前。
Flink可以支持保留多个Checkpoint,需要在Flink的配置文件conf/flink-conf.yaml中,添加如下配置,指定最多需要保存Checkpoint的个数:
state.checkpoints.num-retained: 20
在HDFS的相应文件夹下面会产生多个checkpoint文件。
从Checkpoint进行恢复
如果Flink程序异常失败,或者最近一段时间内数据处理错误,我们可以将程序从某一个Checkpoint点,比如chk-860进行回放,执行如下命令:
bin/flink run -s hdfs://namenode01.td.com/flink-1.5.3/flink-checkpoints/582e17d2cc343e6c56255d111bae0191/chk-860/_metadata flink-app-jobs.jar
从上面我们可以看到,前面Flink Job的ID为582e17d2cc343e6c56255d111bae0191,所有的Checkpoint文件都在以Job ID为名称的目录里面,当Job停掉后,重新从某个Checkpoint点(chk-860)进行恢复时,重新生成Job ID(这里是11bbc5d9933e4ff7e25198a760e9792e),而对应的Checkpoint编号会从该次运行基于的编号继续连续生成:chk-861、chk-862、chk-863等等。
Flink Savepoint
Savepoint会在Flink Job之外存储自包含(self-contained)结构的Checkpoint,它使用Flink的Checkpointing机制来创建一个非增量的Snapshot,里面包含Streaming程序的状态,并将Checkpoint的数据存储到外部存储系统中。
Flink程序中包含两种状态数据,一种是用户定义的状态(User-defined State),他们是基于Flink的Transformation函数来创建或者修改得到的状态数据;另一种是系统状态(System State),他们是指作为Operator计算一部分的数据Buffer等状态数据,比如在使用Window Function时,在Window内部缓存Streaming数据记录。为了能够在创建Savepoint过程中,唯一识别对应的Operator的状态数据,Flink提供了API来为程序中每个Operator设置ID,这样可以在后续更新/升级程序的时候,可以在Savepoint数据中基于Operator ID来与对应的状态信息进行匹配,从而实现恢复。当然,如果我们不指定Operator ID,Flink也会我们自动生成对应的Operator状态ID。
而且,强烈建议手动为每个Operator设置ID,即使未来Flink应用程序可能会改动很大,比如替换原来的Operator实现、增加新的Operator、删除Operator等等,至少我们有可能与Savepoint中存储的Operator状态对应上。另外,保存的Savepoint状态数据,毕竟是基于当时程序及其内存数据结构生成的,所以如果未来Flink程序改动比较大,尤其是对应的需要操作的内存数据结构都变化了,可能根本就无法从原来旧的Savepoint正确地恢复。
下面,我们以Flink官网文档中给定的例子,来看下如何设置Operator ID,代码如下所示:
DataStream stream = env.
// Stateful source (e.g. Kafka) with ID
.addSource(new StatefulSource())
.uid("source-id") // ID for the source operator
.shuffle()
// Stateful mapper with ID
.map(new StatefulMapper())
.uid("mapper-id") // ID for the mapper
// Stateless printing sink
.print(); // Auto-generated ID
创建Savepoint
创建一个Savepoint,需要指定对应Savepoint目录,有两种方式来指定:
一种是,需要配置Savepoint的默认路径,需要在Flink的配置文件conf/flink-conf.yaml中,添加如下配置,设置Savepoint存储目录,例如如下所示:
state.savepoints.dir: hdfs://namenode01.td.com/flink-1.5.3/flink-savepoints
另一种是,在手动执行savepoint命令的时候,指定Savepoint存储目录,命令格式如下所示:
bin/flink savepoint :jobId [:targetDirectory]
例如,正在运行的Flink Job对应的ID为40dcc6d2ba90f13930abce295de8d038,使用默认state.savepoints.dir配置指定的Savepoint目录,执行如下命令:
bin/flink savepoint 40dcc6d2ba90f13930abce295de8d038
可以看到,在目录hdfs://namenode01.td.com/flink-1.5.3/flink-savepoints/savepoint-40dcc6-4790807da3b0下面生成了ID为40dcc6d2ba90f13930abce295de8d038的Job的Savepoint数据。
为正在运行的Flink Job指定一个目录存储Savepoint数据,执行如下命令:
bin/flink savepoint 40dcc6d2ba90f13930abce295de8d038 hdfs://namenode01.td.com/tmp/flink/savepoints
可以看到,在目录 hdfs://namenode01.td.com/tmp/flink/savepoints/savepoint-40dcc6-a90008f0f82f下面生成了ID为40dcc6d2ba90f13930abce295de8d038的Job的Savepoint数据。
从Savepoint恢复
现在,我们可以停掉Job 40dcc6d2ba90f13930abce295de8d038,然后通过Savepoint命令来恢复Job运行,命令格式如下所示:
bin/flink run -s :savepointPath [:runArgs]
以上面保存的Savepoint为例,恢复Job运行,执行如下命令:
bin/flink run -s hdfs://namenode01.td.com/tmp/flink/savepoints/savepoint-40dcc6-a90008f0f82f flink-app-jobs.jar
可以看到,启动一个新的Flink Job,ID为cdbae3af1b7441839e7c03bab0d0eefd。
Savepoint目录结构
下面,我们看一下Savepoint目录下面存储内容的结构,如下所示:
hdfs dfs -ls /flink-1.5.3/flink-savepoints/savepoint-11bbc5-bd967f90709b
Found 5 items
-rw-r--r-- 3 hadoop supergroup 4935 2018-09-02 01:21 /flink-1.5.3/flink-savepoints/savepoint-11bbc5-bd967f90709b/50231e5f-1d05-435f-b288-06d5946407d6
-rw-r--r-- 3 hadoop supergroup 4599 2018-09-02 01:21 /flink-1.5.3/flink-savepoints/savepoint-11bbc5-bd967f90709b/7a025ad8-207c-47b6-9cab-c13938939159
-rw-r--r-- 3 hadoop supergroup 4976 2018-09-02 01:21 /flink-1.5.3/flink-savepoints/savepoint-11bbc5-bd967f90709b/_metadata
-rw-r--r-- 3 hadoop supergroup 4348 2018-09-02 01:21 /flink-1.5.3/flink-savepoints/savepoint-11bbc5-bd967f90709b/bd9b0849-aad2-4dd4-a5e0-89297718a13c
-rw-r--r-- 3 hadoop supergroup 4724 2018-09-02 01:21 /flink-1.5.3/flink-savepoints/savepoint-11bbc5-bd967f90709b/be8c1370-d10c-476f-bfe1-dd0c0e7d498a
如上面列出的HDFS路径中,11bbc5是Flink Job ID字符串前6个字符,后面bd967f90709b是随机生成的字符串,然后savepoint-11bbc5-bd967f90709b作为存储此次Savepoint数据的根目录,最后savepoint-11bbc5-bd967f90709b目录下面_metadata文件包含了Savepoint的元数据信息,其中序列化包含了savepoint-11bbc5-bd967f90709b目录下面其它文件的路径,这些文件内容都是序列化的状态信息。
使用EventTime与WaterMark
WaterMark通过数据源或水印生成器插入到流中。
下面,我们通过实际编程实践,来说明一些需要遵守的基本原则,以便在开发中进行合理设置。
在开发Flink流数据处理程序时,需要指定Time Notion,Flink API提供了TimeCharacteristic枚举类,内部定义了3种Time Notion(参考上面说明)。设置Time Notion的示例代码,如下所示:
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
上面,我们指定了基于TimeCharacteristic.EventTime来进行数据处理。如果我们没有显式指定TimeCharacteristic,默认使用TimeCharacteristic.ProcessTime。
基于EventTime的数据处理,需要对进入的数据元素指派时间戳,并且指定如何生成WaterMark,这样才能通过WaterMark来机制控制输入数据的完整性(事件到达),以便触发对指定Window进行计算。有两种方式实现时间戳指派和生成WaterMark:
- 在Flink程序一开始调用assignTimestampsAndWatermarks()进行指派
- 在Source Operator中直接指派
下面,我们会基于这两种方式进行编码实现:
调用assignTimestampsAndWatermarks()进行指派
TimeWindow的大小设置为1分钟(60000ms),允许延迟到达时间设置为50秒(50000ms),并且为了模拟流数据元素事件时间早于当前处理系统的系统时间,设置延迟时间为2分钟(120000ms)。
我们自定义实现了一个用来模拟的Source Operator,代码如下所示:
class StringLineEventSource(val latenessMillis: Long) extends RichParallelSourceFunction[String] {
val LOG = LoggerFactory.getLogger(classOf[StringLineEventSource])
@volatile private var running = true
val channelSet = Seq("a", "b", "c", "d")
val behaviorTypes = Seq(
"INSTALL", "OPEN", "BROWSE", "CLICK",
"PURCHASE", "CLOSE", "UNINSTALL")
val rand = Random
override def run(ctx: SourceContext[String]): Unit = {
val numElements = Long.MaxValue
var count = 0L
while (running && count < numElements) {
val channel = channelSet(rand.nextInt(channelSet.size))
val event = generateEvent()
LOG.debug("Event: " + event)
val ts = event(0)
val id = event(1)
val behaviorType = event(2)
ctx.collect(Seq(ts, channel, id, behaviorType).mkString("\t"))
count += 1
TimeUnit.MILLISECONDS.sleep(5L)
}
}
private def generateEvent(): Seq[String] = {
// simulate 10 seconds lateness
val ts = Instant.ofEpochMilli(System.currentTimeMillis)
.minusMillis(latenessMillis)
.toEpochMilli
val id = UUID.randomUUID().toString
val behaviorType = behaviorTypes(rand.nextInt(behaviorTypes.size))
// (ts, id, behaviorType)
Seq(ts.toString, id, behaviorType)
}
override def cancel(): Unit = running = false
}
流数据中的数据元素为字符串记录行的格式,包含字段:事件时间、渠道、用户编号、用户行为类型。这里,我们直接调用SourceContext.collect()方法,将数据元素发送到下游进行处理。
在Flink程序中,通过调用stream: DataStream[T]的assignTimestampsAndWatermarks()进行时间戳的指派,并生成WaterMark。然后,基于Keyed Window生成Tumbling Window(不存在Window重叠)来操作数据记录。最后,将计算结果输出到Kafka中去。
对应的实现代码,如下所示:
def main(args: Array[String]): Unit = {
val params = ParameterTool.fromArgs(args)
checkParams(params)
val sourceLatenessMillis = params.getRequired("source-lateness-millis").toLong
maxLaggedTimeMillis = params.getLong("window-lagged-millis", DEFAULT_MAX_LAGGED_TIME)
val windowSizeMillis = params.getRequired("window-size-millis").toLong
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) // 设置为TimeCharacteristic.EventTime
val stream: DataStream[String] = env.addSource(new StringLineEventSource(sourceLatenessMillis))
// create a Kafka producer for Kafka 0.9.x
val kafkaProducer = new FlinkKafkaProducer09(
params.getRequired("window-result-topic"),
new SimpleStringSchema, params.getProperties
)
stream
.setParallelism(1)
.assignTimestampsAndWatermarks( // 指派时间戳,并生成WaterMark
new BoundedOutOfOrdernessTimestampExtractor[String](Time.milliseconds(maxLaggedTimeMillis)) {
override def extractTimestamp(element: String): Long = {
element.split("\t")(0).toLong
}
})
.setParallelism(2)
.map(line => {
// ts, channel, id, behaviorType
val a = line.split("\t")
val channel = a(1)
((channel, a(3)), 1L)
})
.setParallelism(3)
.keyBy(0)
.window(TumblingEventTimeWindows.of(Time.milliseconds(windowSizeMillis))) // 使用Keyed Window
.process(new EventTimeWindowReduceFunction())
.setParallelism(4)
.map(t => {
val windowStart = t._1
val windowEnd = t._2
val channel = t._3
val behaviorType = t._4
val count = t._5
Seq(windowStart, windowEnd, channel, behaviorType, count).mkString("\t")
})
.setParallelism(3)
.addSink(kafkaProducer)
.setParallelism(3)
env.execute(getClass.getSimpleName)
}
上面,我们使用了Flink内建实现的BoundedOutOfOrdernessTimestampExtractor来指派时间戳和生成WaterMark。这里,我们实现了从事件记录中提取时间戳的逻辑,实际生成WaterMark的逻辑使用BoundedOutOfOrdernessTimestampExtractor提供的默认逻辑,在getCurrentWatermark()方法中。我们来看下BoundedOutOfOrdernessTimestampExtractor的实现,代码如下所示:
public abstract class BoundedOutOfOrdernessTimestampExtractor implements AssignerWithPeriodicWatermarks {
private static final long serialVersionUID = 1L;
private long currentMaxTimestamp;
private long lastEmittedWatermark = Long.MIN_VALUE;
private final long maxOutOfOrderness;
public BoundedOutOfOrdernessTimestampExtractor(Time maxOutOfOrderness) {
if (maxOutOfOrderness.toMilliseconds() < 0) {
throw new RuntimeException("Tried to set the maximum allowed " +
"lateness to " + maxOutOfOrderness + ". This parameter cannot be negative.");
}
this.maxOutOfOrderness = maxOutOfOrderness.toMilliseconds();
this.currentMaxTimestamp = Long.MIN_VALUE + this.maxOutOfOrderness; // 初始设置当前最大事件时间戳
}
public long getMaxOutOfOrdernessInMillis() {
return maxOutOfOrderness;
}
public abstract long extractTimestamp(T element);
@Override
public final Watermark getCurrentWatermark() {
long potentialWM = currentMaxTimestamp - maxOutOfOrderness; // 当前最大事件时间戳,减去允许最大延迟到达时间
if (potentialWM >= lastEmittedWatermark) { // 检查上一次emit的WaterMark时间戳,如果比lastEmittedWatermark大则更新其值
lastEmittedWatermark = potentialWM;
}
return new Watermark(lastEmittedWatermark);
}
@Override
public final long extractTimestamp(T element, long previousElementTimestamp) {
long timestamp = extractTimestamp(element);
if (timestamp > currentMaxTimestamp) { // 检查新到达的数据元素的事件时间,用currentMaxTimestamp记录下当前最大的
currentMaxTimestamp = timestamp;
}
return timestamp;
}
}
可以看到,在getCurrentWatermark()和extractTimestamp()方法中,lastEmittedWatermark是WaterMark中的时间戳,计算它时,总是根据当前进入Flink处理系统的数据元素的最大的事件时间currentMaxTimestamp,然后再减去一个maxOutOfOrderness(外部配置的支持最大延迟到达的时间),也就说,这里面实现的WaterMark中的时间戳序列是非严格单调递增的。
我们实现的Flink程序为EventTimeTumblingWindowAnalytics,提交到Flink集群运行,执行如下命令:
bin/flink run --class org.shirdrn.flink.windowing.EventTimeTumblingWindowAnalytics flink-demo-assembly-0.0.1-SNAPSHOT.jar \
--window-result-topic windowed-result-topic \
--zookeeper.connect 172.16.117.63:2181,172.16.117.64:2181,172.16.117.65:2181 \
--bootstrap.servers ali-bj01-tst-cluster-002.xiweiai.cn:9092,ali-bj01-tst-cluster-003.xiweiai.cn:9092,ali-bj01-tst-cluster-004.xiweiai.cn:9092 \
--source-lateness-millis 120000 \
--window-lagged-millis 50000 \
--window-size-millis 60000
在Source Operator中直接指派
和上面我们最终期望的逻辑基本保持一致,我们把指派时间戳和生成WaterMark的逻辑,提取出来放到Source Operator实现中,对应的关键代码片段,如下所示:
var lastEmittedWatermark = Long.MinValue
var currentMaxTimestamp = Long.MinValue + maxLaggedTimeMillis
... ...
ctx.collectWithTimestamp(Seq(ts, channel, id, behaviorType).mkString("\t"), ts.toLong)
ctx.emitWatermark(getCurrentWatermark(ts.toLong))
... ...
private def getCurrentWatermark(ts: Long): Watermark = {
if (ts > currentMaxTimestamp) {
currentMaxTimestamp = ts
}
val watermarkTs = currentMaxTimestamp - maxLaggedTimeMillis
if (watermarkTs >= lastEmittedWatermark) {
lastEmittedWatermark = watermarkTs
}
new Watermark(lastEmittedWatermark)
}
需要在Flink程序的main方法中,将外部配置的与WaterMark生成相关的参数值,传到Source Operator实现类中,如下所示:
val stream: DataStream[String] = env.addSource(
new StringLineEventSourceWithTsAndWaterMark(sourceLatenessMillis, maxLaggedTimeMillis))
同时,把前面调用assignTimestampsAndWatermarks()的方法去掉即可。
编译后,提交到Flink集群运行,可以查看输出结果,和前面类似,输出结果正是我们所期望的。
Keyed Window与Non-Keyed Window
链接:http://shiyanjun.cn/archives/1775.html
从编程API上看,Keyed Window编程结构,可以直接对输入的stream按照Key进行操作,输入的stream中识别Key,即输入stream中的每个数据元素哪一部分是作为Key来关联这个数据元素的,这样就可以对stream中的数据元素基于Key进行相关计算操作,如keyBy,可以根据Key进行分组(相同的Key必然可以分到同一组中去)。如果输入的stream中没有Key,比如就是一条日志记录信息,那么无法对其进行keyBy操作。而对于Non-Keyed Window编程结构来说,无论输入的stream具有何种结构(比如是否具有Key),它都认为是无结构的,不能对其进行keyBy操作,而且如果使用Non-Keyed Window函数操作,就会对该stream进行分组(具体如何分组依赖于我们选择的WindowAssigner,它负责将stream中的每个数据元素指派到一个或多个Window中),指派到一个或多个Window中,然后后续应用到该stream上的计算都是对Window中的这些数据元素进行操作。
从计算上看,Keyed Window编程结构会将输入的stream转换成Keyed stream,逻辑上会对应多个Keyed stream,每个Keyed stream会独立进行计算,这就使得多个Task可以对Windowing操作进行并行处理,具有相同Key的数据元素会被发到同一个Task中进行处理。而对于Non-Keyed Window编程结构,Non-Keyed stream逻辑上将不能split成多个stream,所有的Windowing操作逻辑只能在一个Task中进行处理,也就是说计算并行度为1。
在实际编程过程中,我们可以看到DataStream的API也有对应的方法timeWindow()和timeWindowAll(),他们也分别对应着Keyed Window和Non-Keyed Window。
sate
转载自过往记忆(https://www.iteblog.com/)
链接:https://www.iteblog.com/archives/2417.html

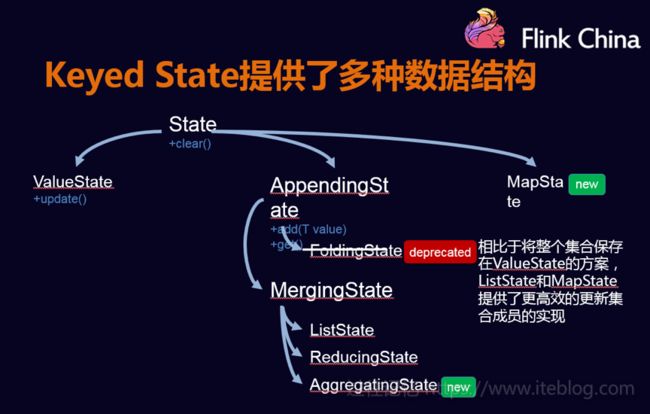
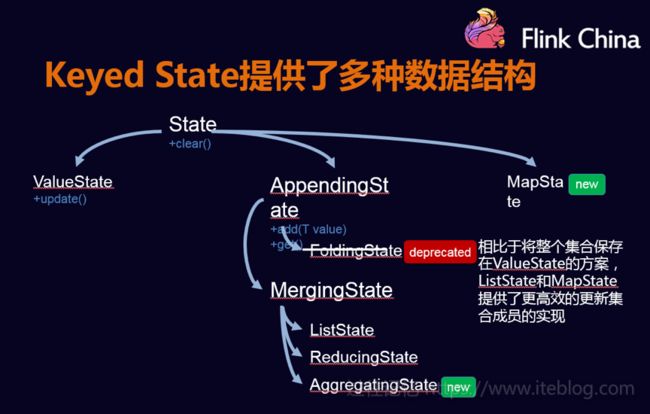
note:Operator States的数据结构不像Keyed States丰富,现在只支持List


用户可以根据自己的需求选择,如果数据量较小,可以存放到MemoryStateBackend和FsStateBackend中,如果数据量较大,可以放到RockDB中。
WindowFunction (Legacy)
窗口的处理函数,但是获取的contextual信息少,也没有一些先进的特征,比如per-window keyed state。未来将会被抛弃。
public interface WindowFunction extends Function, Serializable {
/**
* Evaluates the window and outputs none or several elements.
*
* @param key The key for which this window is evaluated.
* @param window The window that is being evaluated.
* @param input The elements in the window being evaluated.
* @param out A collector for emitting elements.
*
* @throws Exception The function may throw exceptions to fail the program and trigger recovery.
*/
void apply(KEY key, W window, Iterable input, Collector out) throws Exception;
}
DataStream> input = ...;
input
.keyBy()
.window()
.apply(new MyWindowFunction());
时间窗口的机制
Tumbling windows are aligned to epoch, i.e, 1970-01-01T00:00:00. So with a tumbling window of 10 seconds 2017-07-03T20:19:35Z would to into the window from [2017-07-03T20:19:30Z, 2017-07-03T20:19:40Z) and 2017-07-03T20:22:30Z would into [2017-07-03T20:22:30Z, 2017-07-03T20:22:40Z).
35的事件触发的窗口是[30-40)的窗口。
MapStateDescriptor
public void open(Configuration parameters) throws Exception {
MapStateDescriptor descriptor =
new MapStateDescriptor<>(
"words", // the state name
BasicTypeInfo.STRING_TYPE_INFO, // type information
TypeInformation.of(new TypeHint() {})
); // default value of the state, if nothing was set
// sum = getRuntimeContext().getState(descriptor);
}
public void open(Configuration parameters) throws Exception {
MapStateDescriptor descriptor =
new MapStateDescriptor<>(
"words", // the state name
String.class, // type information
Word.class
); // default value of the state, if nothing was set
// sum = getRuntimeContext().getState(descriptor);
}
设计草稿
时间、窗口、水印
链接:https://cwiki.apache.org/confluence/display/FLINK/Time+and+Order+in+Streams(好)
讲了窗口,时间,水印的概念,还有时间窗口计算后的时间戳应该怎么赋值。
state、fault tolence
链接:https://cwiki.apache.org/confluence/display/FLINK/Stateful+Stream+Processing#StatefulStreamProcessing-Stateinstreamingprograms

Streams and Operations on Streams
链接:https://cwiki.apache.org/confluence/display/FLINK/Streams+and+Operations+on+Streams
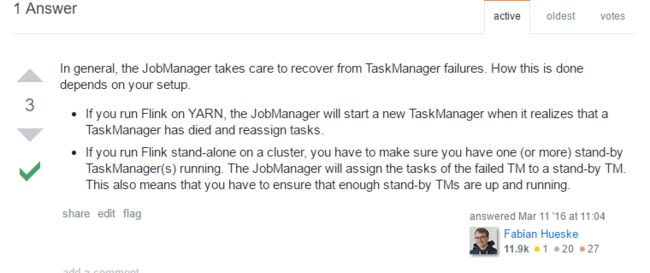
TaskManager故障恢复
JobManager可以通过配置高可用的zookeeper来保证故障恢复,TaskManager怎么故障恢复能?
Keep in mind that in In stand alone mode a TM process that has exited
won't be automatically restarted though.
实践所得:在standalone集群模式下,杀死一个TaskManager,那么机器上的这个TaskManager不会重启,会使用其他机器剩余可用的TaskManager中slots来运行失败的task。
Slots
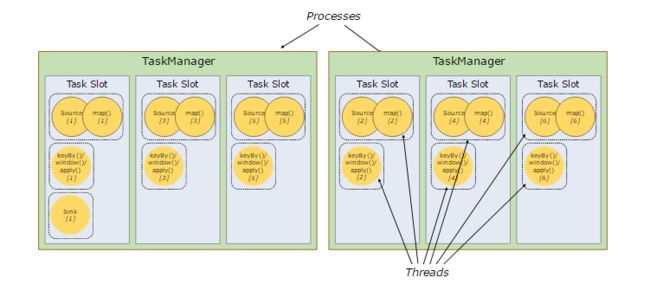
A Flink cluster needs exactly as many task slots as the highest parallelism used in the job. No need to calculate how many tasks (with varying parallelism) a program contains in total.
flink使用的slot数目是最高的并行度数目。
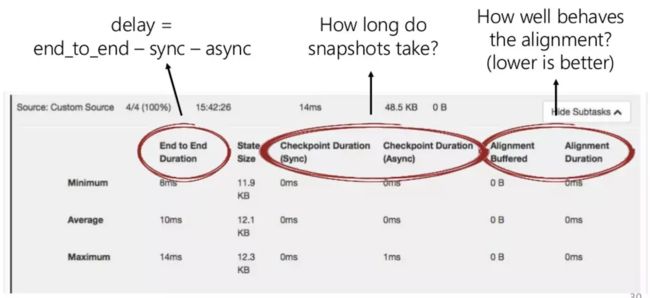
alignment
alignment的影响

Asynchronous State Snapshots
只有RockDB里面才有

各种state的例子
链接:https://www.slideshare.net/tillrohrmann/fault-tolerance-and-job-recovery-in-apache-flink


state backend

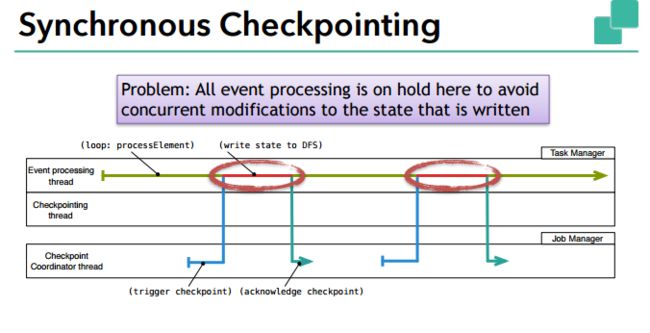
同步和异步的checkpoint区别

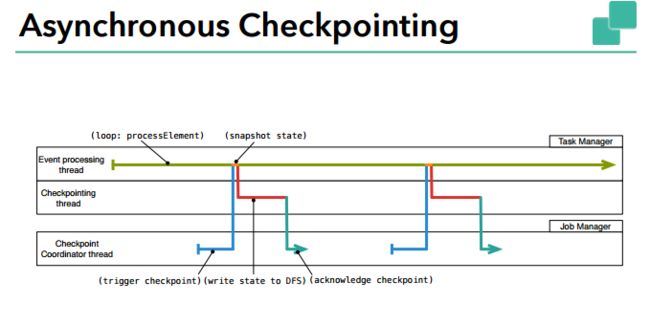

异步
链接:https://www.jianshu.com/p/a2a0dade97b8
我们注意到上面描述的机制意味着当 operator 向后端存储快照时,会停止处理输入的数据。这种同步操作会在每次快照创建时引入延迟。
我们完全可以在存储快照时,让 operator 继续处理数据,让快照存储在后台异步运行。为了做到这一点,operator 必须能够生成一个后续修改不影响之前状态的状态对象。例如 RocksDB 中使用的写时复制( copy-on-write )类型的数据结构。
接收到输入的 barrier 时,operator异步快照复制出的状态(注:checkpoint的同步部分,复制状态可能会花费较多的时间,这也是为什么checkpoint同步部分时间很长的原因)。然后立即发射 barrier 到输出流,继续正常的流处理。一旦后台异步快照完成,它就会向 checkpoint coordinator(JobManager)确认 checkpoint 完成。现在 checkpoint 完成的充分条件是:所有 sink 接收到了 barrier,所有有状态 operator 都确认完成了状态备份(可能会比 sink 接收到 barrier 晚)。
RocksDBStateBackend 模式对于较大的 Key 进行更新操作时序列化和反序列化耗时很多。可以考虑使用 FsStateBackend 模式替代。
Checkpoint UI信息