Python3高级项目实战最新教程
Week 01
内容概要:if...else for循环 while循环
多行注释:‘’‘ ’‘’,还可以用作字符串的多行输出(赋给一个变量)
格式化输出:+号字符串拼接、%s方法、.format方法
linux chmod 755:linux chmod 755
#!/usr/bin/env python #Linux下python解释器的路径
print "hello,world"
参考:Python之路,Day1 - Python基础1
Week 02
内容概要:模块初识 列表、元组操作 字符串操作 字典操作
sys模块:sys.path sys.argv
os模块:
Python 3中bytes/string的区别
列表删除元素:.remove() .pop() del
列表的一些方法:.count() .clear() .reverse() .sort() .extend() .copy():浅拷贝=copy.copy() (copy.deepcopy():深拷贝)

参考:Python之路,Day1 - Python基础1
Python之路,Day2 - Python基础2
Week 03
内容概要:集合操作 文件操作 字符编码与转码 函数式编程
文件操作
f = open('A01_170201_215121413.ME', 'r', encoding='utf-8')
# for line in f.readlines():
# print(line)
for line in f:
print(line)
函数式编程
面向对象: 类-----class
面向过程: 过程-----def,表观上比函数少return返回值
函数式编程: 函数-----def,三大优点:代码复用、保持一致性、可扩展性
def test(x, y):
print(x)
print(y)
# test01(x=2,3) # 错误!关键字参数不能在位置参数前面!
test(2, y=3) # 关键字参数一定要在位置参数后面
# *args:接收N个位置参数,转换成元组的形式
def test01(x,*args):
print(x)
print(args[0])
print(args[1])
print(args)
test01(1,2,3)
test01(1,*[2,3])
# **kwargs:接收N个关键字参数,转换成字典的形式
def test02(name,**kwargs):
print(name)
print(kwargs['sex'])
print(kwargs['age'])
print(kwargs)
test02(name='famir',sex='male',age=22)
test02('famir',**{'sex':'male','age':22})
参考:Python之路,Day2 - Python基础2
Python之路,Day3 - Python基础3
Week 04
内容概要:装饰器 迭代器&生成器 Json & pickle 数据序列化 软件目录结构规范 作业:ATM项目开发
装饰器


高阶函数
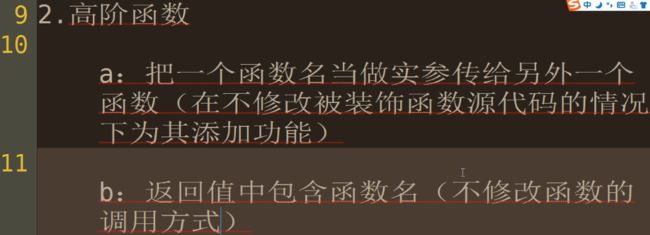
嵌套函数
定义: 在一个函数体内用def声明一个新的函数,而不是调用一个新的函数
装饰器示例
import time
def timer(func):
def warpper(*args, **kwargs):
start_time = time.time()
func(*args, **kwargs)
stop_time = time.time()
print('the function run time is %s' % (stop_time-start_time))
return warpper
@timer # 等价于tst=timer(tst)
def tst(name, age):
time.sleep(2)
print('in the tst:', name, age)
tst('famir', 22)
生成器
yield
迭代器
凡是可作用于for循环的对象都是Iterable类型;
凡是可作用于next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列;
集合数据类型如list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
Python的for循环本质上就是通过不断调用next()函数实现的。
Json & pickle 数据序列化
参考 http://www.cnblogs.com/alex3714/articles/5161349.html
软件目录结构规范
Foo/
|-- bin/
| |-- foo
|
|-- foo/
| |-- tests/
| | |-- init.py
| | |-- test_main.py
| |
| |-- init.py
| |-- main.py
|
|-- docs/
| |-- conf.py
| |-- abc.rst
|
|-- setup.py
|-- requirements.txt
|-- README
参考:Python之路,Day4 - Python基础4 (new版)
python装饰器
Week 05
5.1 模块Module与包Package
https://blog.csdn.net/famirtse/article/details/80009365#t0
5.2 模块的分类:
- 标准库(内置模块)
- 开源模块
- 自定义模块
1.标准库
1. time与datetime
time.time():从1970年1月1日开始计算的秒数时间戳(Unix系统诞生于1970年)
time.sleep()
time.gmtime():世界标准时间
time.localtime():本地时间(输入时间戳,输出本地时间元组)
time.strftime()
time.strptime()
2. random模块
3. os模块
4. sys模块
5. shutil模块
高级的 文件、文件夹、压缩包 处理模块
参考 http://www.cnblogs.com/wupeiqi/articles/4963027.html
6. json和pickle模块
用于序列化的两个模块
- json,用于字符串 和 普通的python数据类型间进行转换
- pickle,用于python特有的类型 和 广泛的python数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
7. shelve模块
shelve模块是一个简单的k,v将内存数据通过文件持久化的模块,可以持久化任何pickle可支持的python数据格式
8. Xml模块
9. Configparser模块
10. Hashlib、Hmac模块
11. 正则表达式Re模块
常用正则表达式符号:
'.' 默认匹配除\n之外的任意一个字符,若指定flag DOTALL,则匹配任意字符,包括换行
'^' 匹配字符开头,若指定flags MULTILINE,这种也可以匹配上(r"^a","\nabc\neee",flags=re.MULTILINE)
'$' 匹配字符结尾,或e.search("foo$","bfoo\nsdfsf",flags=re.MULTILINE).group()也可以
'*' 匹配*号前的字符0次或多次,re.findall("ab*","cabb3abcbbac") 结果为['abb', 'ab', 'a']
'+' 匹配前一个字符1次或多次,re.findall("ab+","ab+cd+abb+bba") 结果['ab', 'abb']
'?' 匹配前一个字符1次或0次
'{m}' 匹配前一个字符m次
'{n,m}' 匹配前一个字符n到m次,re.findall("ab{1,3}","abb abc abbcbbb") 结果'abb', 'ab', 'abb']
'|' 匹配|左或|右的字符,re.search("abc|ABC","ABCBabcCD").group() 结果'ABC'
'(...)' 分组匹配,re.search("(abc){2}a(123|456)c", "abcabca456c").group() 结果 abcabca456c
'\A' 只从字符开头匹配,re.search("\Aabc","alexabc") 是匹配不到的
'\Z' 匹配字符结尾,同$
'\d' 匹配数字0-9
'\D' 匹配非数字
'\w' 匹配[A-Za-z0-9]
'\W' 匹配非[A-Za-z0-9]
'\s' 匹配空白字符、\t、\n、\r , re.search("\s+","ab\tc1\n3").group() 结果 '\t'
'(?P...)' 分组匹配 re.search("(?P[0-9]{4})(?P[0-9]{2})(?P[0-9]{4})","371481199306143242").groupdict("city") 结果{'province': '3714', 'city': '81', 'birthday': '1993'}
最常用的匹配语法:
re.match 从头开始匹配
re.search 匹配包含
re.findall 把所有匹配到的字符放到以列表中的元素返回
re.split 以匹配到的字符当做列表分隔符
re.sub 匹配字符并替换
反斜杠的困扰:
与大多数编程语言相同,正则表达式里使用"“作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符”",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\“表示。同样,匹配一个数字的”\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
仅需轻轻知道的几个匹配模式:
re.I(re.IGNORECASE): 忽略大小写(括号内是完整写法,下同)
re.M(MULTILINE): 多行模式,改变'^'和'$'的行为(参见上图)
re.S(DOTALL): 点任意匹配模式,改变'.'的行为
参考:http://blog.51cto.com/egon09/1840425
https://www.cnblogs.com/alex3714/articles/5161349.html
Week 06
参考:https://www.cnblogs.com/alex3714/articles/5188179.html