花书第五章 机器学习
机器学习基础
机器学习怎样定义:
对于某类任务T 和性能度量P,一个计算机程序被认为可以从经验E 中学习是指,通过经验E 改进后,它在任务T 上由性能度量P 衡量的性能有所提升。
学习算法:
机器学习任务类型包括, 分类,输入缺失分类, 回归,转录,机器翻译,结构化输出,异常检测,合成和采样,缺失值填补,去噪,密度估计或概率质量函数估计。
输入缺失分类
当输入向量的每个度量不被保证的时候,分类问题将会变得更有挑战性。为了解决分类任务,学习算法只需要定义一个从输入向量映射到输出类别的函数。当一些输入可能丢失时,学习算法必须学习一组函数,而不是单个分类函数。 例如: 图片中缺失一块,或者数据缺失一部分的情况。
需要学习多个分类器,每个分类器对应一种特殊的情况,一种特征缺失的情况进行操作。
回归
给定输入预测数值(连续型),输出函数 f : R n → R f: \mathbb{R}^n \to \mathbb{R} f:Rn→R
转录
这类任务中,机器学习系统观测一些相对非结构化表示的数据,并转录信息为离散的文本形式。例如,光学字符识别要求计算机程序根据文本图片返回文字序列。是一种无监督学习算法。举例: 自动编码器 用于压缩。
结构化输出
输出时向量或者其他包含多个值得数据结构,并且构成输出的这些不同元素间的重要关系。举例:
- 图片的像素集分割,将每一个像素分配到特定类别。
- 为图片添加描述的任务 Image Caption
- 通过图片之中的信息,提取里面的文字等有用信息。 淘宝京东,自动识别送货地址。照片就行。 银行卡自动识别卡号等技术
异常检测
机器学习程序生成一组事件或对象中筛选。 并标记不正常或非典型的个体。
合成和采样
生成一些和训练数据相似的新样本。通过机器学习,合成和采样可能在媒体应用中非常有用。
Gan 生成对抗网络中,生成AI 画。转换画风格, 生成假样本 等等
缺失值填补
根据机器学习其他样本的信息,对缺失或者被污染的的信息进行填补
去噪
超分辨率算法,除去马赛克,低分辨率的图片变成高分辨率的图片
密度估计或概率质量函数估计
算法学习观测到的数据的结构,能够隐式到地捕获概率分布的结构。
性能度量
需要根据具体业务来判断用何种性能度量指标。 性能度量相关指标 可以参考 sklearn ,metrics 包。示例: 人脸识别例子。 如果我们不希望漏找人脸的情况下,我们通常会要求查全率比较高。 人脸解锁,通常要求速度快,实时性。我们希望查准率比较高,能够快速找到符合要求的人脸。
名词简介
数据集与设计矩阵
设计矩阵:所有情况下,数据集都是样本的集合,而样本是特征的集合。 表示数据集的的常用方法是设计矩阵。 每一行包含一个不同的样本,每一列对应不同的特征。 但是只有在每一样本都能表示成向量,并且这些向量的维度相同时,才能将一个数据集表示成设计矩阵。 有时候非结构化数据,如不同宽度和高度的照片集合,包含不同像素,就无法形成这种设计矩阵。
权重 与偏置
权重:线性系统中,一组决定每个特征值如何影响预测的向量值。
偏置:截距项b 通常被称为仿射变换的偏置参数。它和统计偏差中指代统计估计算法的某个量的期望估计偏离真实值的意思是不一样的。
独立同分布
每个数据集中的样本彼此互相独立地 (联合概率 等于各自概率的乘积),并且训练集和测试集是同分布的。
机器学习算法效果因素
降低训练误差。 缩小训练误差和测试误差的差距。
算法分类
无监督学习算法的相关解释
训练包含有很多特征的数据集,然后学习出这个数据集上有用的结构性质。在深度学习中,我们通常要学习生成数据集的整个概率分布,显示地,比如密度估计,或是隐式的,比如合成或去噪。 还有一些其他类型的无监督任务,例如聚类,将数据集分成相似样本的集合。
无监督学习 和 监督学习的大概定义
人们将回归、分类或者结构化输出问题成为监督学习。
将支持其他任务的密度估计称为无监督学习。
半监督学习: 一些样本有监督目标,但其他样本没有 。
强化学习: 学习算法并不是固定在一个固定的数据集上。
具体算法细节,请参照机器学习笔记。
容量、欠拟合和过拟合
欠拟合: 模型不能在训练集上的获得足够低的误差。 常见于模型训练初期
过拟合: 训练误差和测试误差之间的差距太大。 常见于模型训练一段时间以后发生。训练误差持续减小,测试集误差不降反升。
奥卡姆剃刀原则:在同样能够解释已知观测现象的假设中,我们应该挑选"最简单"的那一类。 更平滑,不复杂的那一类。
VC 维度: 分类器能够分类的训练样本的最大数目。 (可以参照林轩田 机器学习基石第七课 VC维度)
容量: 模型拟合各种函数的能力。容量低的模型可能很难拟合训练集。容量高的模型可能会过拟合。
控制训练算法容量的方法之一 是选择合适的假设空间。
当机器学习算法的容量适合于所执行任务的复杂度和所提供训练数据的数量时,算法效果通常会最佳
可以通过调整模型的容量: 控制模型是否偏向于过拟合或者欠拟合。
NFL(没有免费的午餐定理): 所有可能的数据生成分布上平均之后,或者可以说所有"问题"出现的机会相同 (假设), 每一个分类算法在未实现观测的点都有相同的错误率。
但是事实上这个假设在真实的世界中数据集上是不存在的。有数据集就有相关的归纳偏好,能够找到与之对应的
合适的算法。
超参数和验证集
通过验证集来调整超参数。 一般 训练集和验证集划分 8:2 7:3
交叉验证
原因: 测试集误差很小的话, 有问题, 一个小规模的测试集意味着平均测试误差估计的统计不确定性。不能判断算法之间的优劣。 使用k折交叉验证算法用于估计算法的泛化误差。
把训练集分成若干份,一次顺序从其中取一份作为验证集,其余做为训练集进行相应训练。 返回k 次的损失函数。
估计、偏差和方差
估计: 用一个模型去估计一个目标函数, 模型与潜在的分布记性拟合。
偏差: 偏离真实函数或参数的误差期望。
方差: 数据上任意特定采样可能导致的估计期望的偏差。 模型并不稳定
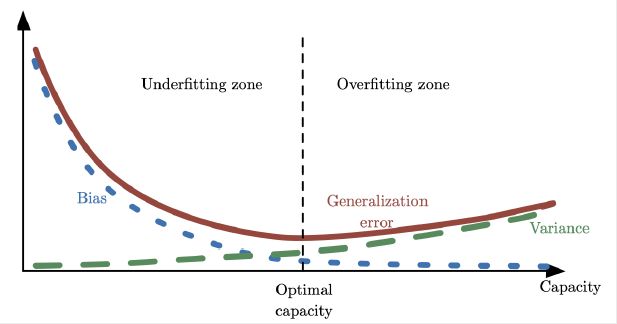
相关示意图