网页数据爬虫-R语言
最早接触爬虫是利用java写脚本,后来自学了利用python进行爬虫来做入门,会用scrapy,最近用了下R,找了几个不同类型的字段获取,当作好玩吧。
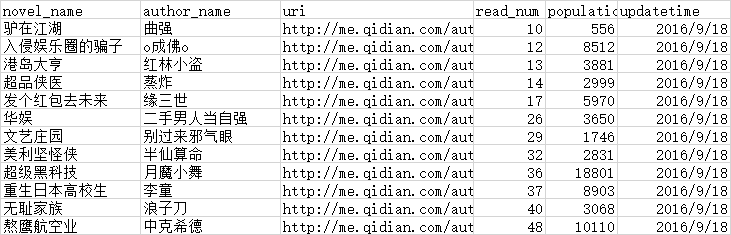
爬取内容


R代码
library(XML)
library(RCurl)
library(stringr)
giveNovel_name = function(rootNode){
novel_name <- xpathSApply(rootNode,"//div[@class='title']/h1/text()",xmlValue)
novel_name=gsub("([\r\n ])","",novel_name)
}
giveAuthor_name = function(rootNode){
author_name <- xpathSApply(rootNode,c("//div[@class='title']/span/a/span/text()"),xmlValue)
author_name=gsub("([\r\n ])","",author_name)
}
giveUri = function(rootNode){
uri <- xpathSApply(rootNode,c("//div[@class='title']//span//a"),xmlAttrs,"href")#xpath路径中属性获取
uri=gsub("([\r\n\t ])","",uri)
}
giveRead = function(rootNode){
read_num <- xpathSApply(rootNode,c("//div[@class='score_txt']/text()[1]"),xmlValue)
read_num=str_extract_all(read_num,"[0-9]+[0-9]")#从字符串中获取数字
}
##页面内请求获取评论量
giveReply = function(rootNode){
population <- xpathSApply(rootNode,c("//div[@class='data']//b//span[@id='lblReviewCnt']//text()"),xmlValue)
}
webData= function(URL){
Sys.sleep(runif(1,1,2))
wp<-getURL(URL,.encoding="UTF-8") #对应的网站编码
doc<-htmlParse(wp,asText=T,encoding="UTF-8")
rootNode<-xmlRoot(doc)
book_id=str_extract_all(URL,"[0-9]+[0-9]")[[1]]
url2=gsub(" ","",paste("http://c.pingba.qidian.com/BookComment.aspx?BookId=",book_id,""))##拼接页面内数据请求url
sub_wp<-getURL(url2,.encoding="UTF-8") #对应的网站编码
sub_doc<-htmlParse(sub_wp,asText=T,encoding="UTF-8")
sub_rootNode<-xmlRoot(sub_doc)
date<-Sys.Date()
data.frame(
novel_name=giveNovel_name(rootNode),
author_name=giveAuthor_name(rootNode),
uri=giveUri(rootNode)[3,1],
read_num=as.numeric(giveRead(rootNode)),
month_likenum=likenum[[1]][1],
population=giveReply(sub_rootNode),
updatetime=date#更新时间
)
}
上述完成了爬取得具体内容,作品的url可能是多个,可以进行批量抓取
##测试单个url##
URL="http://www.qidian.com/Book/3548786.aspx"
info<-webData(URL)#使用编写的函数,获得网页数据
write.table(info,"F:\\数据收集\\qidian_literature.csv",append=TRUE,col.names=FALSE,row.names = FALSE,sep=",")###将数据存到本地文件
####批处理####
con <- file("F:\\数据收集\\qidian_urls.csv", "r")
line=readLines(con,n=1)
while( length(line) != 0 ) {
info<-webData(line)#使用编写的函数,获得网页数据
write.table(info,"F:\\数据收集\\qidian_literature.csv",append=TRUE,col.names=FALSE,row.names = FALSE,sep=",")###将数据存到本地文件
line=readLines(con,n=1)
}
close(con)结果展示