kafka集群搭建
概要介绍
vmware克隆了三台机器(系统是centos6.5),首先配置三台机器的静态ip,可以看我之前的一篇点击打开链接。
现在我们要在三台centos系统主机上搭建一个kafka集群。
1.修改主机名和修改主机名配置文件
因为新克隆出来的三台主机,主机名还是原来的,现在修改它。
命令行中键入以下命令:
vi /etc/sysconfig/network
把HOSTNAME修改为新的 主机名"hadoop4"

修改主机名配置文件,键入以下命令:
vi /etc/hosts
其中最后三行是新添加的三台机器的ip 地址和主机名
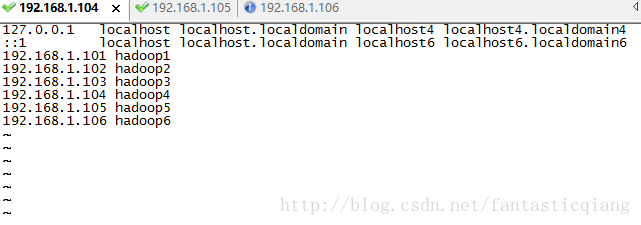
修改完毕后,reboot 命令重启机器
2.重新配置三台机器的ssh无密登录
查看当前用户跟 目录下是否有.ssh文件夹,命令如下:
ll -a
移除原来的.ssh文件夹,命令如下:
rm -rf .ssh/
重新生成一对公私钥,保存在用户目录.ssh/文件夹中,命令如下:
ssh-keygen -t rsa
按三下回车,完成操作。进去.ssh/文件夹中查看
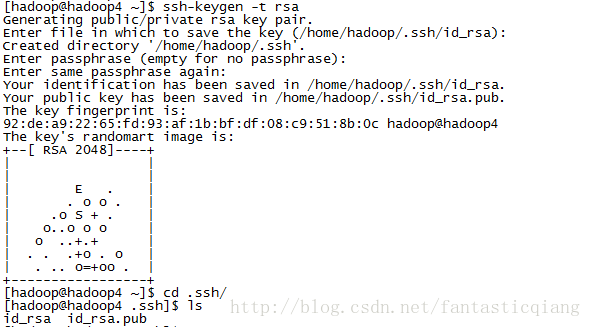
新建文件authorized_keys,它用来保存无秘登录到当前机器的公钥,命令如下:
touch authorized_keys
可以看出文件新建的时候权限是自己和所属组可读可写,对其他人可读:

注意需要保证这个文件的权限是“600”(只有自己可读可写),不然ssh无秘登录就会失败!
修改权限,命令如下:
chmod 600 authorized_keys
记住这句话就可以了,谁想ssh无密登录这台机器就把自己的公钥放到authorized_keys文件中即可。
首先把本机的公钥添加进去,命令如下:
cat id_rsa.pub >> authorized_keys
测试ssh无密登录本机(hadoop4),命令如下:
ssh hadoop4
第一次登录会让你输入“yes”,确认登录这台机器。我们输入“exit”退出当前登录,第二次我们输入“ssh hadoop4”的时候就能直接登录到这台机器了。

再通过复制粘贴的方式,把想登录到这台主机的公钥都复制到authorized_keys文件中即可。因为我们打算让这三台主机可以互相登录,所以三台主机中的authorized_keys文件中的内容都是一样的,即三台机器的公钥都在里面。
分别测试登录hadoop5,hadoop6都是成功的,这里就不截图了。
2.搭建zookeeper集群
因为Kafka集群是把状态保存在Zookeeper中的,首先要搭建Zookeeper集群。
使用 yum 命令下载wget,命令如下:
yum install wget
下载zookeeper安装包3.4.11地址 https://archive.apache.org/dist/zookeeper/zookeeper-3.4.11/zookeeper-3.4.11.tar.gz
命令窗口中输入以下命令:
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.11/zookeeper-3.4.11.tar.gz
如果下载速度太慢,可以使用迅雷下载后上传到linux机器上。由于本人使用secureCRT,所以按“alt+p”组合键进入上传界面
输入"cd /home/hadoop/app/zookeeper" 命令 进入上传目的地目录。
输入"lcd C:/Users/lqq/Documents"命令,进入上传目的地目录。
输入“put zookeeper-3.4.11.tar.gz”命令,完成上传。
输入“tar -zxvf zookeeper-3.4.11.tar.gz”解压文件,然后命令“mkdir zkData”用来存放zookeeper数据。
进入"/zookeeper-3.4.11/conf"目录,命令“ cp zoo_sample.cfg zoo.cfg”复制"zoo_sample.cfg"为“zoo.cfg”。
修改两个地方,①配置文件“data”目录,②配置zookeeper集群的ip,如下:
dataDir=/home/hadoop/app/zookeeper/zkData
#文件最后添加
server.1=hadoop4:2888:3888
server.2=hadoop5:2888:3888
server.3=hadoop6:2888:3888其中"server.1",1 表示hadoop4主机上zookeeper的标示,在刚才新建的zkData目录中,如下命令添加标示:
touch myid
echo 1 | cat > myid
由于我们已经配置了ssh免密登录,下面使用scp命令完成其它主机上的安装,如下:
scp -r zkData/ zookeeper-3.4.11/ hadoop@hadoop5:/home/hadoop/app/zookeeper/
需要修改myid中的内容为2。hadoop6主机同理完成文件复制,需要修改myid中的内容为3。
下面启动zookeeper并测试
分别进入三台主机zookeeper bin/目录中,"./zkServer.sh start"完成启动,“./zkServer.sh status”查看状态


3.搭建kafka集群
下载kafka下载地址
"mkdir kafka"把压缩包放入解压,并在kafka目录下新建logs文件夹用来存放kafka日志。
"tar -zxvf kafka_2.11-1.0.0.tgz"来解压kafka。
修改配置文件
listeners=PLAINTEXT://192.168.1.104:9092
zookeeper.connect=192.168.1.104:2181,192.168.1.105:2181,192.168.1.106:2181使用如下命令把kafka拷贝到其它主机上去:
scp -r kafka/ hadoop@hadoop5:/home/hadoop/app/
scp -r kafka/ hadoop@hadoop6:/home/hadoop/app/
注意需要把其它主机上的broker.id分别修改为“1”和“2”,listeners的ip地址也该成对应主机的。
保证zookeeper启动的情况下启动kafka:
bin/kafka-server-start.sh -daemon config/server.properties
创建主题test:
bin/kafka-topics.sh --create --zookeeper hadoop4:2181 --replication-factor 1 --partitions 1 --topic test
创建console生产者:
bin/kafka-console-producer.sh --broker-list hadoop4:9092 --topic test
创建console消费者:
bin/kafka-console-consumer.sh --bootstrap-server hadoop4:9092 --topic test --from-beginning
下面是成功发送消息的截图:
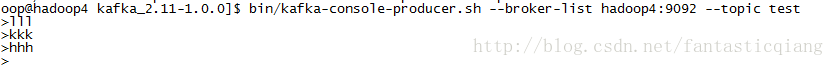
消费者截图:
