python读取与写入json+csv变成coco的json文件+安装labelme
一.python读取与输出json
读取json
path = './image/003.json'
with open(path) as file:
json_info = json.load(file)
#print(len(json_info['shapes']))如果是str形式的用json.loads
写入json
with open(path+'/'+name+'.json', 'w+') as fp:
json.dump(data, fp=fp, ensure_ascii=False, indent=4, separators=(',', ': '))
二.coco数据集介绍
{
"info": info, # dict
"licenses": [license], # list ,内部是dict
"images": [image], # list ,内部是dict
"annotations": [annotation], # list ,内部是dict
"categories": # list ,内部是dict
}
三.csv转coco的json文件
1,train的csv生成coco,json文件
csv文件如下:

图片如下:

import cv2
import math
import numpy as np
import xml.etree.ElementTree as ET
import pandas as pd
from PIL import Image, ImageEnhance
import glob
import json
CLASS_NAMES = ['steel']
class COCOStyleDataset(object):
# @staticmethod
# def json_info(json_path=None):
# # json_path = '/workspace/mmdetection-0p6rc/gangjin/train_annotations.json'
# from pycocotools import coco
# cd = coco.COCO(json_path)
# print('anno num: ', len(cd.anns))
# print('img num: ', len(cd.imgs))
# return len(cd.imgs), len(cd.anns)
@staticmethod
def json_annotations_for_train():
class_name2id = {}
for idx, cls_nm in enumerate(CLASS_NAMES):
class_name2id[cls_nm] = idx + 1
print(class_name2id)
final_json = dict()
final_json['info'] = None
final_json['licenses'] = None
final_json['categories'] = []
final_json['images'] = []
final_json['annotations'] = []
# categories
for i in range(1):
cat = dict()
cat['id'] = i + 1
cat['name'] = CLASS_NAMES[i]
cat['supercategory'] = CLASS_NAMES[i]
final_json['categories'].append(cat)
print(final_json)
sv_nm = 'train_annotations_example.json'
data_root = './'
path_prefix = 'JPEGImages_example/'
img_path = data_root + path_prefix
print('img_path=', img_path)
img_names = glob.glob1(img_path, '*jpg')
print('img_names=', img_names)
def pre_data(df):
df.iloc[:, 1] = df.apply(lambda x: [float(a) for a in x[1].split(' ')], axis=1)
def collect(df):
rlt = dict()
for i in range(df.shape[0]):
img_nm = df.iloc[i, 0]
if img_nm in rlt.keys():
rlt[img_nm].append(df.iloc[i, 1])
else:
rlt[img_nm] = [df.iloc[i, 1]]
for key, val in rlt.items():
rlt[key] = np.array(val)
return rlt
df = pd.read_csv(data_root + '/train_labels.csv')
print(df)
"""add part csv_name"""
for i in img_names:
df_part=df[df['ID']==i]
pre_data(df_part)
print(df_part)
lb_dict = collect(df_part)
print(lb_dict)
"""df_part replace df"""
assert len(lb_dict) == len(img_names)
img_names = list(lb_dict.keys())
print(img_names)
# gene json
image_id_counter = 250
annotation_id_counter = 30942
for img_name in img_names:
print(image_id_counter, annotation_id_counter, img_name)
# image
image = dict()
img_data = Image.open(img_path + img_name)
image['id'] = image_id_counter
image['width'] = img_data.width
image['height'] = img_data.height
image['file_name'] = img_name
final_json['images'].append(image)
print(lb_dict[img_name])
# annotation
for i in range(lb_dict[img_name].shape[0]):
x, y, x2, y2 = lb_dict[img_name][i]
width, height = x2 - x, y2 - y
annotation = dict()
annotation['id'] = annotation_id_counter
annotation['image_id'] = image_id_counter
annotation['category_id'] = 1
annotation['bbox'] = [x, y, width, height]
annotation['area'] = float(width * height)
annotation['iscrowd'] = 0
final_json['annotations'].append(annotation)
# update annotation id
annotation_id_counter += 1
# update image id
image_id_counter += 1
# write json
with open(data_root + sv_nm, 'w') as fp:
json.dump(final_json, fp=fp, ensure_ascii=False, indent=4, separators=(',', ': '))
@staticmethod
def json_annotations_for_test():
final_json = dict()
final_json['info'] = None
final_json['licenses'] = None
final_json['categories'] = []
final_json['images'] = []
final_json['annotations'] = []
img_path = './JPEGImages_example/'
img_names = sorted([nm for nm in os.listdir(img_path) if 'jpg' in nm])
print('img num: ', len(img_names))
image_id_counter = 0
for img_name in img_names:
print(image_id_counter, img_name)
img_data = Image.open(img_path + img_name)
# image
image = dict()
image['id'] = image_id_counter
image['width'] = img_data.width
image['height'] = img_data.height
image['file_name'] = img_name
final_json['images'].append(image)
image_id_counter += 1
with open('./test_annotations_example.json', 'w') as fp:
json.dump(final_json, fp=fp, ensure_ascii=False, indent=4, separators=(',', ': '))
if __name__ == '__main__':
# COCOStyleDataset.json_annotations_for_train()
COCOStyleDataset.json_annotations_for_test()
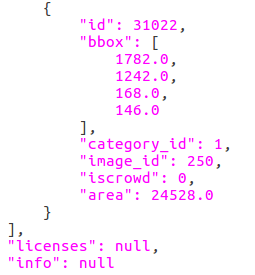
生成的json文件截图如下:

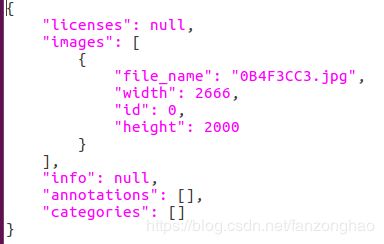
2,test的图片生成coco,json文件
test的json文件如下图
四,安装labelme
sudo apt-get install python-qt4 pyqt4-dev-tools
sudo pip install labelme # python2 workslabelme --nodata --autosave
会自动生成对应的json文件