MySql(二)之高级使用
##概述
本节主要讲解的知识有:
- 数据类型的使用。
- 主键,字段值唯一,不能为null等设置。
- sql语句中的表达式。
- 排序。
- 分页
- 聚合函数。
- 分组。
- sql注入及防止sql注入的方法。
##数据类型的使用
数据库中的数据类型很多,下面仅仅讲解项目中常用的数据类型。
数据类型分为四大类:整数,小数,字符串,时间。
一,整数
整数类型及占用的字节数如下:
| 数据类型 | 占用字节数(取值范围) |
| tinyint(m) | 1个字节(-128~127) |
| smallint(m) | 2个字节(-2的16次方~2的16次方-1) |
| mediumint(m) | 3个字节(-2的24次方~2的24次方-1) |
| int(m) | 4个字节(-2的32次方~2的32次方-1) |
| bigint(m) | 8个字节(-2的64次方~2的64次方-1) |
说明:
- 选择数据类型的原则是:在满足取值范围的前提下优先选择占用字节数小的。
- int数据类型与java中的int取值范围相同,bigint数据类型与java中的long取值范围相同。
- 实际开发中一般选择int,如果int不满足要求时再选择bigint。对于仅仅表示类型的整数可以选择binyint。
注意:int数据类型后面可以带参数,如:
create table person (id int(11),name varchar(10));
此时的11并不表示字节的长度,也不表示取值范围。因为int类型以及决定了数据的长度和取值范围。网上说11表示展示长度,但这个又有什么实质意义呢?以后再详细研究。
二,小数
小数类型及占用的字节数如下:
| 数据类型 | 占用字节数(取值范围) |
| float(n,d) | 单精度浮点型 4字节 |
| double(n,d) | 双精度浮点型 8字节 |
说明:float和double的取值范围分别与java中的float和double对应。
注:float和double后面可以根两个参数,如下:
create table person (id int(11),price double(10,2));此时10表示总数据位数,2表示小数位数,即整数位数是8.
三,字符串
字符串数据类型如下:
| 数据类型 | 说明 |
| char(n) | 固定长度,最多255个字符 |
| varchar(n) | 固定长度,最多65535个字符 |
| tinytext | 可变长度,最多255个字符 |
| text | 可变长度,最多65535个字符 |
| mediumtext | 可变长度,最多2的24次方-1个字符 |
| longtext | 可变长度,最多2的32次方-1个字符 |
说明:
- 最常使用的数据类型是varchar,varchar后面可以指定字符长度,最多是6.5万个。(注:是字符长度,不是字节长度,具体字节长度取决于编码格式)
- char的储存和查找效率都高于varchar。
- text与varchar对比完全没有优点,text不能设置索引,不能设置默认值。
- text的优点是:不能设置长度,此时就没有了具体长度限制。
四,时间类型
时间数据类型如下:
| 数据类型 | 说明: |
| date | 日期,只包含年月日 |
| time | 时间,只包含时分秒 |
| datetime | 日期和时间 |
| timestamp | 日期和时间 |
最常用的是datetime和timestamp,下面说明这个数据类型的区别。
datetime存入的是时间,没有时区的概念。timestamp是时间戳,同时间戳在不同时区对应不同时间。
datetime和timestamp的时间范围不同。datetime是任意时间范围。timestamp是1970年到2038年。
一般在操作当前时间时使用timestamp,操作历史或者很远的未来时间时使用datetime.
##主键,字段值唯一,不能为null等设置
一,主键的设置
在数据库中,通常要选择一个字段或多个字段作为这条数据的唯一标识,一个字段则称为唯一主键,多个字段则称为组合主键。
主键具有唯一性,即主键不能重复。对于组合主键多个字段不能同时重复。
主键的设置是在创建数据库时,示例如下:
create table person (
id int(11) primary key,
name varchar(10),
sex varchar(2),
age int
);
说明:上面sql中使用primary key关键词将id设为表的主键。
设置主键为自增长:既然主键是唯一性,那么需要操作数据时保证主键唯一,如果主键每次都自增长就确保了主键唯一。设置自增长的方法:
create table person (
id int(11) primary key auto_increment,
name varchar(10),
sex varchar(2),
age int
);##字段值唯一
一个表中只能设置一个主键,或者一组主键,如果其他字段也不能重复则可以使用unique关键字设置。
create table user(
ID int primary key auto_increment,
PHONE_NUM varchar(11) unique
);说明:保证手机号不能重复。当手机号重复时则插入失败。
##字段值不能为null
create table user(
ID int primary key auto_increment,
USERNAME varchar(100) not null unique,
GENDER char(1) not null,
);说明:使用not null设置字段值不能为null。
##给字段设置默认值
create table person (
id int(11) primary key auto_increment,
name varchar(10) default '',
sex varchar(2) default 'nan',
age int default 0
);
##sql语句中的表达式
在做查找,修改,删除操作时往往需要where条件,在条件语句中需要有大于,小于,and,or等运算符,带有运算符的sql语句称为表达式。
表达式分为算法表达式和逻辑表达式。具体如下:

注:in后面的元素不能超过1000个。当元素太多时in的效率会很低,可以使用exist语句替代。
一,like的详细使用
like是模糊查询的关键词。使用情况有如下三种:
--必须以张三开头
select * from person where name like '张三%';
--必须以张三结尾
select * from person where name like '%张三';
--必须包含张三,且张与三紧挨着
select * from person where name like '%张三%';
--必须包含张三,且张在三的前面
select * from person where name like '%张%三%';
--必须以张三开头,且只能包含三个字
select * from person where name like '张三_';
##排序
排序的关键词是order by。使用示例如下:
select * from person order by age得到结果样式如下:

此时我们看出,以age排序后,age依次增大。
默认的排序是升序。降叙排列使用关键词desc,如下:
select * from person order by age desc结果样式如下:

注:升序排序也可以加关键词asc,是ascending的缩写,但关键词asc常常省略不写。降叙desc是Descending单词的缩写。
注:排序可以同时指定两个关键词,如下:
select * from person order by age desc,name asc说明:
- 两个关键词以第一个为准,第一个字段相同时则按第二个排序。
- 不同字段需要分别指定升序还是降序。
##分页
分页使用关键词limit。示例如下:
select * from person limit 1,2结果如下:

说明:
- 1的意思是从1开始,但不包括1。2的意思是取两条。所以此时取出的是第2和第3条数据。
- 如果limit2,3则取出的是第3,第4和第5条。
- 第一个数可以省略。limit 2 表示从0开始,取出两条,即第1和第2条。
注:分页与排序同时使用时,必须先排序,后分页,如下:
select * from person order by age limit 1,2##聚合函数
sql语句中提供了一些聚合函数,如下:sum()求和,count()统计数量,max()求最大值,avg()求平均值.具体使用如下:
1,sum()求和
--一般使用
select sum(age) from person ;
--添加where条件
select sum(age) from person WHERE id > 2;注:sum的意思是求和,即通过select age from person语句得到的所有age相加之和。sum方法和可以这么使用:
select sum(1) from person注:这个意思是使用select 1 from person语句获取的所有数据相加,此时person有4条数据,sum(1)就是4,这种方式可以统计数量。
2,count()统计
--
select count(*) from person
--
select count(1) from person
--
select count('a') from person
--
select count(age) from person
--使用where条件
select count(*) from person where id >2注:count的意思是统计数据,即是通过select * from person得到的数据的个数。所以count的小括号内可以放任意值。
注:统计数量是最好用count(1)。
3,max()获取最大值
select max(age) from person 注:max的意思与sum类似,获取所有age,然后取最大值。sql语句后台同样可以添加where条件语句。
4,min()获取最小值
select min(age) from person 5,avg()获取平均值
select avg(age) from person ##分组
一,基本使用
分组使用关键词order by
原表数据如下:
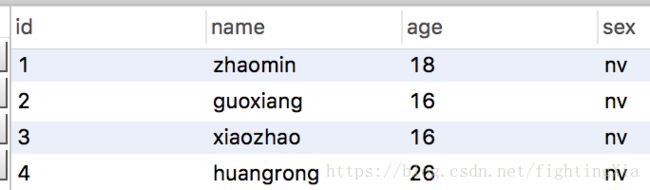
分组sql语句如下:
select age from person group by age查询结果如下:

说明:原表中有两个age是16,通过age分组只得到一个16.
注:group by后面可以跟多个字段,如下:
select name,age from person group by name,age说明:此时name和age同时相同时才会被分为一组。
二,分组求和
分组的作用:分组常常与聚合函数一起使用,比如获取各个年龄的人数,如下:
select age ,count(1) from person group by agesql执行结果如下:

说明:此时可以看到各个年龄的人数。
三,分组统计
需求:统计表中年龄的个数,即有几个年龄数。sql如下:
select count(1) from (select age from person group by age) temp这是一种多表操作,先使用select age from person group by age得到一个临时表,然后再查数量。
四,分组获取最大值
需求:统计各个年龄的最大id。sql如下:
select max(id),age from person group by age
五,分组最易范错误
如下面语句:
select name,age from person group by age执行会报下面异常:
Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'xia.person.name' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
说明:异常意思是说name不是分组的列。表中guoxiang,zhaomin的age都是16,所以不可能获取到一个name,但可以这么用:
select max(name),age from person group by age六,having的使用
where不能与group by一起使用,所以此时出现了having。用法示例如下:
--
select age from person group by age having age >2
--
select count(1), age from person group by age having count(1) >1
--
select age from person group by age having count(1) >1说明:having后面并不是所有字段都可以作为判断条件,必须是可以放在select 和from之间的字段才能作为判断条件。
##sql注入
持续完善中。。。